Инспектор

Вы можете этот курс.
Опубликован: 11.03.2009 | Уровень: специалист | Доступ: платный
Лекция 12:
Оптимизация выполнения запросов
Аннотация: Лекция посвящена теме оптимизации выполнения запросов. В теоретической части рассказывается о выполнении запросов в Oracle, об оптимизаторе, его назначении и этапах работы, о параметрах, влияющих на работу оптимизатора. А также, рассматриваются практические задания по теме.
Ключевые слова: SQL-запрос, СУБД, запрос, языками запросов, синтаксический анализ, представление, объект базы данных, константа, информация, базы данных, оптимизация, эквивалентность, ограничение целостности, остов, план выполнения, стоимость, статистическая информация, оптимальный план, механизм "запрос-ответ", декларативный язык, запрос SQL, пользователь, множество, доступ к данным, множества, оптимальность, оптимизатор запросов, функция, Исход, вычисление выражения, SQL, оператор, путь доступа, Oracle, оптимизация запросов, критерии оптимизации, rule base, web-based, статистика, ресурс, операционная система, корректность, rule, bitmap, choose, интерфейс, причинность, производительность, cardinality, процессор, ввод/вывод, свободное пространство, длина строки, ключ, блок данных, факториал, кластеризация, NULL, диапазон, Гистограмма, x-высота, ячейка, выборка данных, high-q, mark, дерево, Двоичное дерево, идентификатор, ветвление, out-of-range, scan, вычисление, запись, ссылка, создание индекса, job, analyst, manager, кластерный индекс, критерии поиска, минимум, некластерный индекс, значение, пространство, операции, viewing, объект, отношение, транзакция, журнал изменений
Выполнение запросов в Oracle. Общая схема и взаимодействие с клиентским приложением и машиной PL/SQL
Все SQL-запросы, поступающие в СУБД, обрабатываются примерно по одной схеме.
На первой фазе запрос, заданный на языке запросов, подвергается лексическому и синтаксическому анализу. При этом вырабатывается его внутреннее представление, отражающее структуру запроса и содержащее информацию, которая характеризует объекты базы данных, упомянутые в запросе (отношения, поля и константы). Информация о хранимых в базе данных объектах выбирается из каталогов базы данных. Внутреннее представление запроса используется и преобразуется на следующих стадиях обработки запроса.
На второй фазе запрос во внутреннем представлении подвергается логической оптимизации. Могут применяться различные преобразования, "улучшающие" начальное представление запроса. Среди преобразований могут быть эквивалентные, после проведения которых получается внутреннее представление, семантически эквивалентное начальному (например, приведение запроса к некоторой канонической форме), Преобразования могут быть и семантическими: получаемое представление не является семантически эквивалентным начальному, но гарантируется, что результат выполнения преобразованного запроса совпадает с результатом запроса в начальной форме при соблюдении ограничений целостности, существующих в базе данных. После выполнения второй фазы обработки запроса его внутреннее представление остается непроцедурным, хотя и является в некотором смысле более эффективным, чем начальное.
Третий этап обработки запроса состоит в выборе на основе информации, которой располагает оптимизатор, набора альтернативных процедурных планов выполнения данного запроса в соответствии с его внутреннем представлением, полученным на второй фазе. Для каждого плана оценивается предполагаемая стоимость выполнения запроса. При оценках используется статистическая информация о состоянии базы данных, доступная оптимизатору. Из полученных альтернативных планов выбирается наиболее дешевый, и его внутреннее представление теперь соответствует обрабатываемому запросу.
На четвертом этапе по внутреннему представлению наиболее оптимального плана выполнения запроса формируется выполняемое представление плана.
Наконец, на пятом этапе обработки запроса происходит его реальное выполнение.
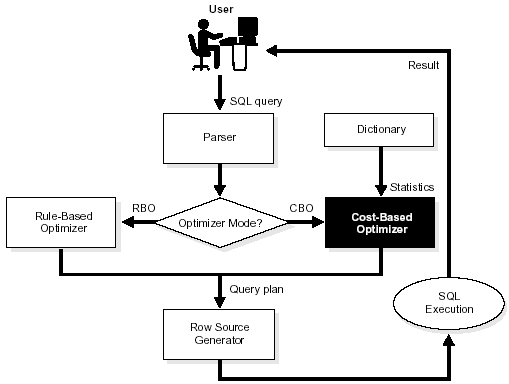
Оптимизатор. Его назначение. Этапы работы оптимизатора
Одним из основных преимуществ реляционных СУБД является механизм запросов на основе декларативного языка запросов SQL. При формулировании запроса пользователь указывает ЧТО он хочет получить а за то КАК это получить , отвечает СУБД. Поскольку существует потенциально очень большое множество способов выполнить конкретный запрос (комбинация способов и порядка соединения таблиц, путей доступа к данным и т.д.), появляется задача выбрать из всего множества способов выполнения запроса оптимальный. За эту задачу отвечает оптимизатор запросов.
Функция оптимизатора - выбрать наиболее оптимальный (исходя из набора критериев) план выполнения запроса. При формировании оптимального плана, оптимизатор решает следующие задачи
- Вычисление выражений и операций
- Преобразование SQL операторов
- Выбор способа оптимизации - по стоимости или по правилам
- Выбор путей доступа
- Выбор порядка соединений таблиц
- Выбор метода соединений таблиц
- Определение наиболее эффективного плана выполнения
В Oracle реализовано два подхода к оптимизации запроса, отличающиеся в выборе критериев оптимизации.
- Оптимизация по правилам (RULE BASED). Подход, при котором учитываются только способы доступа к данным, с зафиксированными приоритетами по эффективности доступа. Данный подход использовался в ранних версиях ORACLE и обладает существенным недостатком - он не учитывает реального распределения данных.
- Оптимизация по стоимости (COST BASED). Помимо эффективности различных путей доступа к данным, учитывается так же статистика по распределению данных и ресурсов операционной системы.
Режимы работы оптимизатора по стоимости. Установка режимов. Параметры, влияющие на работу оптимизатора
CBO управляется статистикой. Причем, когда он вычисляет стоимость, он учитывает количество блоков в таблице, количество строк, количество различных значений индексов и так далее. Чтобы он корректно работал, статистику надо регулярно собирать. Работа оптимизатора управляется параметром optimizer_mode, который может указываться на уровне сессии или на уровне экземпляра. Он может иметь следующие значения.
optimizer_mode = rule - RBO (был заморожен в версии 7), RBO, например, не умеет пользоваться Bitmap индексами.
optimizer_mode = all_rows - CBO, выбирает план выполнения с оптимальной стоимостью, режим работы оптимизатора по умолчанию.
optimizer_mode = first_rows - CBO, вычисляется стоимость разных планов выполнения, выбирает несколько планов с оптимальной стоимостью, по разным эвристическим соображениям пытается выбрать план, который наиболее быстро возвращает первые строки.
optimizer_mode = choose - Oracle сам выбирает, какой режим оптимизатора выбрать. Самый плохой случай: установлен данный режим и по каким-то таблицам есть статистика, а по каким-то нет. Пример, если хотя бы по одной из таблиц в запросе статистика есть, то в большинстве случаев будет использоваться all_rows, а если ни по одной из таблиц нет, то - rule. Если RBO не поддерживает интерфейс запроса (например, Bitmap -индексы), то используется CBO. CBO может оптимизировать запросы по таблицам, по которым не собрана статистика, используя умолчания для таблиц.
optimizer_mode = first_rows_1, first_rows_10, first_rows_1000 - при использовании first_rows Oracle вычисляет стоимость выполнения всего оператора, потом выбирает оптимальный план, при использовании first_rows_n вычисляет стоимость получения первых n строк, а стоимость выполнения всего оператора не вычисляется (данные режимы оптимальны для форм и первых операторов ).
Пример:
alter session set optimizer_mode= first_rows;
Статистика. Назначение, способы формирования
Отсутствие статистики оптимизатора или устаревшие статистические данные часто являются причиной неоптимальной производительности обработки запросов. Оптимизатор, работающий на основе стоимости, использует для определения стоимости пути доступа такую статистику, как число элементов ( cardinality ) таблицы, число возможных значений столбца и распределение данных. Стоимость является мерой того, сколько памяти, ресурсов процессора и каналов ввода-вывода потребуется для выполнения запроса. Чтобы эффективно использовать оптимизатор, работающий на основе стоимости, нужно собрать статистику числа элементов ( cardinality ) и распределения данных для каждой таблицы, индекса и материализованного представления. Статистика собирается с помощью пакета DBMS_STATS. Статистические данные можно собирать либо путем чтения всех строк, либо путем проведения оценки на основе чтения только небольшой выборки строк или блоков. В пакете DBMS_STATS предлагаются процедуры для сбора статистики уровня базы данных, схемы или таблицы, а также раздела таблицы.
Сбор статистики с помощью analyze
analyze table t compute statistics for table for all indexes for all columns; analyze table t compute statistics for table for all indexes for all indexed columns; analyze table t compute statistics for table for columns i, s; analyze index t_i compute statistics for table for all indexes for all columns; analyze table t estimate statistics for table for all indexes for all columns sample 10 rows; analyze table t estimate statistics for table for all indexes for all columns sample 10 percent; analyze table t compute statistics for table for all indexes for all columns size 100; analyze table t compute statistics for table for columns i size 100, s size 200;
Сбор статистики с помощью пакета dbms_stats
execute dbms_stats.gather_index_stats(ownname=>'stud',
indname=>'i', partname=>null, estimate_percent=>50, stattab=>null, statid=>null, statown=>null);
execute dbms_stats.gather_table_stats(ownname=>'stud',
tabname=>'t', partname=>null, estimate_percent=>50, block_sample=>false,
method_opt=>'FOR ALL COLUMNS', degree=>null,
cascade=>true, stattab=>null, statid=>null, statown=>null);
execute dbms_stats.gather_table_stats(ownname=>'stud',
tabname=>'t', partname=>null, estimate_percent=>50, block_sample=>false,
method_opt=>'FOR COLUMNS object_name, object_id',
degree=>null, cascade=>true, stattab=>null,
statid=>null, statown=>null);
execute dbms_stats.gather_schema_stats(ownname=>'stud',
estimate_percent=>50, block_sample=>false, method_opt=>'FOR ALL COLUMNS',
degree=>null, cascade=>true, stattab=>null, statid=>null, statown=>null);
execute dbms_stats.delete_index_stats(ownname=>'stud',
indname=>'i', partname=>null, stattab=>null, statid=>null, statown=>null);
execute dbms_stats.delete_table_stats(ownname=>'stud',
tabname=>'t', partname=>null, stattab=>null, statid=>null,
statown=>null, cascade_parts=>true, cascade_columns=>true);
execute dbms_stats.delete_schema_stats(ownname=>'stud', stattab=>null,
statid=>null, statown=>null);
Листинг
12.1.
Статистика по таблицам
Данные по статистике таблиц можно посмотреть в словаре USER_TABLES. Основная статистика -
- количество строк
- количество блоков
- количество пустых блоков
- среднее доступное свободное пространство
- количество мигрировавших строк
- средняя длина строки
Пример:
select * from user_tables where table_name = 'T';
analyze table t delete statistics;
select num_rows, blocks, empty_blocks, avg_space,
chain_cnt, avg_row_len, avg_space_freelist_blocks,
num_freelist_blocks, sample_size, last_analyzed from user_tables
where table_name = 'T';
analyze table t compute statistics for table;
select num_rows, blocks, empty_blocks, avg_space,
chain_cnt, avg_row_len, avg_space_freelist_blocks,
num_freelist_blocks, sample_size, last_analyzed from user_tables
where table_name = 'T';Статистика по индексам
Статистику по индексам можно посмотреть в словаре USER_INDEXES. Основная статистика -
- глубина индекса
- кол-во листовых блоков
- кол-во различн. ключей
- средн. кол-во лист. блоков на ключ
- средн. кол-во блоков данных на ключ
- кол-во узлов индекса
- фактор кластеризации (кол-во блоков, которое надо выбрать для выборки всех строк из таблицы по индексу)
Пример:
analyze table t delete statistics;
select blevel, leaf_blocks, distinct_keys,
avg_leaf_blocks_per_key, avg_data_blocks_per_key,
clustering_factor, num_rows, sample_size,
last_analyzed from user_indexes
where table_name = 'T' and index_name = 'T_I';
analyze table t compute statistics for all indexes;
select blevel, leaf_blocks, distinct_keys,
avg_leaf_blocks_per_key, avg_data_blocks_per_key,
clustering_factor, num_rows, sample_size,
last_analyzed from user_indexes
where table_name = 'T' and index_name = 'T_I';Статистика по столбцам
Статистику по столбцам можно посмотреть в словаре USER_TAB_COLUMNS, USER_TAB_COL_STATISTICS. Статистика -
Пример:
select * from user_tab_columns where table_name = 'T' and column_name = 'I'; select * from user_tab_col_statistics where table_name = 'T' and column_name = 'I'; analyze table t delete statistics; select * from user_tab_col_statistics where table_name = 'T' and column_name = 'I'; analyze table t compute statistics for all columns; select * from user_tab_col_statistics where table_name = 'T' and column_name = 'I';
Данная статистика не содержит одну очень важную информацию - распределение значений по диапазонам. Для хранения этой информации используются гистограммы. Существует два типа гистограмм - частотные гистограммы и сбалансированные по высоте. Максимальное количество брикетов в гистограмме - 254. Если количество различных значений в столбце меньше указанного размера гистограммы, то строятся частотная гистограмма. В противном случае - сбалансированная по высоте.
Сбалансированные по высоте гистограммы содержат одинаковое количество строк в каждом брикете гистограммы. Значение ячейки соответствует максимальному значению столбца в группе. Частотные гистограммы содержат столько брикетов, сколько есть различных значений в столбце. Значение ячейки содержит количество строк со значениями столбца, меньше либо равными данному.
Пример:
analyze table t compute statistics for columns s size 254;
select endpoint_number, endpoint_value,
substr(endpoint_actual_value, 1, 30)
from user_tab_histograms where table_name =
'T' and column_name = 'S';
analyze table t compute statistics for columns s size 8;
select endpoint_number, endpoint_value,
substr(endpoint_actual_value, 1, 30)
from user_tab_histograms where table_name =
'T' and column_name = 'S';
analyze table t compute statistics for columns s size 254;
select endpoint_number, endpoint_value,
substr(endpoint_actual_value, 1, 30)
from user_tab_histograms where table_name =
'T' and column_name = 'S';
select s, count(*) from t group by s;Пути доступа к данным
Подготовка данных
-- создание объектов drop table h; -- create table h(p number constraint pk primary key, s varchar2(100) null, n number null, nu number null constraint un unique); create table h(p number, s varchar2(100) null, n number null, nu number null);