Инспектор

Вы можете этот курс.
Опубликован: 16.04.2007 | Уровень: специалист | Доступ: платный
Лекция 12:
Концепции распределенных баз данных
Аннотация: В этой лекции рассматриваются концепции распределенных баз данных, вопросы репликации данных и синхронизации баз. Также здесь рассказывается о том, как запустить несколько серверов MySQL на одном компьютере.
Ключевые слова: сервер, запрос, ПО, производительность, память, СУБД, базы данных, распределенные базы данных, очередь, внутренние связи, системы управления распределенными базами данных, интерфейс, модуль, репликация в mysql, таблица, mysql, копирование баз данных, полезность, база данных, отложенная синхронизация, доступ, запись, файл, сценарий, индекс, переменная, утилиты командной строки, пользователь, список, информация, программа, журнал изменений, подчиненный сервер, хранение данных, поток, приложение, генератор, пул сервера, алгоритм, журнал ошибок, функция, генератор псевдослучайных чисел, значение, Unix, изменение таблицы, REVOKE, реальное значение, отношение, инструкция, USER, архив, CNF, опция, идентификатор, репликация, Internet, пространство, открытая среда, множества, группа, имя пользователя, пароль, целое число, номер порта, запуск нескольких серверов
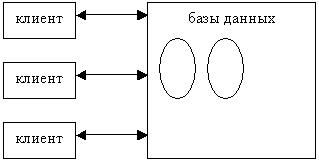
Обычный сервер хранит у себя все данные и обслуживает все клиентские запросы. Схема взаимодействия между сервером и клиентами изображена на рис 12.1. Серверные данные располагаются на одном или нескольких физических дисках. Чтобы сделать запрос, клиент устанавливает соединение с сервером. Сервер анализирует инструкции, выполняет их, извлекает данные и возвращает результаты запроса. По мере возрастания нагрузки производительность сервера снижается. Чтобы избежать этого, задействуют дополнительные ресурсы, например, наращивают память, ставят дополнительные процессоры и даже сетевые платы. Эта стратегия эффективна, если клиенты расположены в непосредственной близости от сервера, — например, несколько серверов приложений взаимодействуют с одной СУБД. Но в тех архитектурах, где сервер и клиенты удалены друг от друга, производительность обратно пропорциональна расстоянию.
Решением этой проблемы являются распределенные базы данных (РБД), которые сегментируют хранимую информацию и перемещают отдельные ее блоки ближе к нужным клиентам. Способов организации таких баз данных много. Можно разместить таблицы на разных компьютерах или использовать несколько идентичных хранилищ. Во втором случае серверы взаимодействуют друг с другом для поддержания синхронизации. Если на одном из серверов происходит обновление данных, оно распространяется и на все остальные серверы.
К недостаткам распределенных баз данных можно отнести то, что возрастает сложность управления ими. Но преимуществ все же больше. Главное из них — повышение производительности. Данные быстрее обрабатываются несколькими серверами, а кроме того, данные располагаются ближе к тем пользователям, которые чаще с ними работают.
Система становится более устойчивой, если она способна выдержать сбой одного из своих компонентов. В распределенной базе данных с симметричной схемой хранения исчезновение одного из серверов приводит к замедлению работы пользователей, находящихся ближе к этому серверу, но в целом система остается работоспособной. К тому же, она легко масштабируется, так как ее не нужно останавливать при добавлении еще одного сервера.
В несимметричной системе можно оптимизировать схему расположения данных. Чем ближе пользователи находятся к нужным им данным, тем меньше на их работу влияют сетевые задержки. В результате серверам приходится обрабатывать меньшие объемы данных. Это также способствует повышению безопасности данных, поскольку их можно физически хранить в тех системах, где пользователи имеют право работать с соответствующими данными. В целом, однако, применение распределенных баз данных связано с достаточно высоким риском. Требуется обеспечить соблюдение мер безопасности сразу на нескольких узлах, что не так-то просто реализовать.
Распределенные базы данных трудно проектировать и обслуживать. Порядок работы в системе может со временем поменяться что повлечет за собой изменение схемы хранения данных. Как клиенты, так и серверы должны уметь обрабатывать запросы к данным, которые не расположены в ближайшей системе. Плохо спроектированная РБД может демонстрировать меньшую производительность, чем одиночный сервер.
РБД состоит из трех основных частей: клиентов, модуля обработки транзакций и хранилища данных. Сервер обычно берет на себя задачи обработки транзакций и хранения данных, хотя в полностью распределенной базе данных за решение этих задач отвечают разные аппаратные компоненты. Обратимся к рис 12.2. Здесь три клиента взаимодействуют с двумя модулями обработки транзакций, которые, в свою очередь, работают с двумя хранилищами. Клиенты посылают свои запросы модулям, а те определяют, в каком из хранилищ находятся требуемые данные.
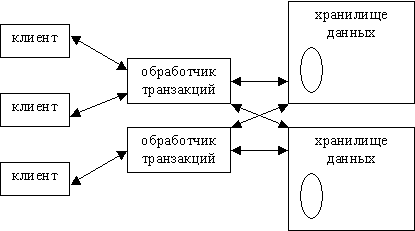
В идеальном случае, клиенты не знают, является система распределенной или нет. Они лишь посылают ей запросы, а система возвращает клиентам результаты этих запросов. Как она это делает, клиентов не интересует. На практике распределенные базы данных проявляют разную "прозрачность". В крайнем случае РБД хранится на нескольких независимых серверах, а клиентскому приложению приходится выбирать сервер в зависимости от того, какую информацию требуется получить. Это подразумевает, что таблицы, находящиеся на разных серверах, не имеют никаких внутренних связей. Естественно, такая организация РБД лишь изредка оказывается полезной.
Система управления распределенными базами данных, или РСУБД, предоставляет клиентам унифицированный интерфейс доступа к данным, благодаря которому возникает иллюзия единого сервера. Если данные находятся в разных местах, РСУБД посылает запросы и обновления в соответствующие хранилища. В зависимости от того, с каким хранилищем ведется работа, производительность системы может оказаться разной, но, по крайней мере, клиентам не приходится самим заниматься выбором сервера.
Если данные реплицируются между несколькими серверами, клиент в общем случае может предпочесть тот или иной сервер. В подобной схеме все серверы хранят одни и те же данные. Специальный модуль может помогать клиентам в выборе серверов, осуществляя выравнивание нагрузки. РСУБД отвечает за выполнение транзакций в многосерверной среде, но в любой момент времени два сервера не могут быть синхронизированы между собой.
В РБД применяется несколько схем распределения данных. В случае репликации каждый сервер хранит весь объем данных. Для этого требуется, чтобы РСУБД дублировала транзакции, позволяя всем клиентам видеть согласованный образ базы данных. В случае несимметричного разделения данных выбирается уровень сегментации. На самом высоком уровне расщеплению подвергаются отдельные базы данных, но не таблицы. Каждая таблица целиком находится в каком-то одном месте. На более низком уровне таблицы расщепляются по строкам или столбцам. Например, при горизонтальном расщеплении отдельные подмножества записей помещаются в разные хранилища, а при вертикальном расщеплении подмножества формируются на основании столбцов.