Инспектор

Вы можете этот курс.
Опубликован: 04.06.2009 | Уровень: специалист | Доступ: платный | ВУЗ: Нижегородский государственный университет им. Н.И.Лобачевского
Лекция 10:
Структура современной СУБД на примере Microsoft SQL Server 2008
Организация таблиц и индексов
Таблицы и индексы хранятся в виде коллекции страниц размером 8 КБ.
Страницы таблиц и индексов содержатся в одной или нескольких секциях. Секция — это пользовательская единица организации данных. По умолчанию таблица или индекс имеет единственную секцию, которая содержит все страницы таблицы или индекса. Секция располагается в одной файловой группе. Таблица или индекс, имеющие одну секцию, эквивалентны организационной структуре таблиц и индексов предыдущих версий SQL Server.
Если таблица или индекс используют несколько секций, данные секционируются горизонтально, так что группы строк сопоставляются отдельным секциям, основываясь на указанном столбце. Секции могут храниться в одной или нескольких файловых группах в базе данных. Таблица или индекс рассматриваются как единая логическая сущность при выполнении над данными запросов или обновлений. Секция состоит из фрагментов одного или нескольких файлов. Данные внутри фрагмента файла представляются в виде кучи (строки данных хранятся без определенного порядка – последовательное размещение) или сбалансированного дерева. Фрагмент файла может иметь один из трех видов: данные с типами небольших размеров (данные IN_ROW_DATA), данные с типами больших размеров (LOB_DATA), данные переменной длины (переполнение строки ROW_OVERFLOW_DATA).
В каждой секции кучи или индекса содержится по крайней мере одна единица распределения IN_ROW_DATA. Кроме того, в зависимости от схемы кучи или индекса, там могут содержаться единицы распределения LOB_DATA или ROW_OVERFLOW_DATA.
Следующая иллюстрация показывает организацию таблицы ( рис. 10.4).
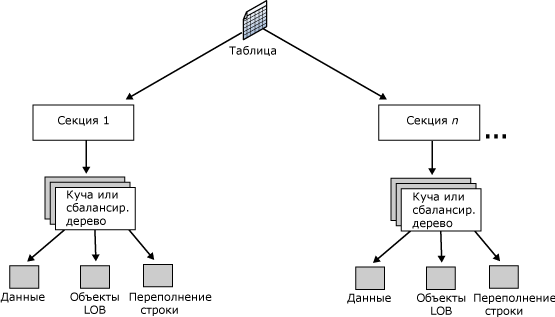
Каждая секция содержит строки данных либо в куче, либо в структуре кластеризованного индекса. Кластеризованный индекс реализуется в виде структуры индекса сбалансированного дерева, которая поддерживает быстрый поиск строк по их ключевым значениям. Страницы в каждом уровне индекса, включая страницы данных на конечном уровне, связаны в двунаправленный список. Однако перемещение из одного уровня на другой выполняется при помощи ключевых значений.
Куча — это последовательность строк таблицы, которые не имеют кластеризованного индекса. Строки данных хранятся без определенного порядка, и какой-либо порядок в последовательности страниц данных отсутствует. Страницы данных не связаны в связный список.
Управление работой с экстентами и свободным местом
Структуры данных SQL Server, управляющие использованием экстента и отслеживанием свободного места, обладают относительно простой структурой. Сведения о свободном месте плотно упакованы, поэтому эти данные содержат относительно небольшое количество страниц. Это приводит к увеличению скорости из-за уменьшения необходимых операций чтения диска для получения сведений о размещении. Также увеличивается вероятность того, что страницы размещения будут оставаться в памяти и повторных операций чтения не потребуется. Большая часть сведений о размещении не связана по цепочке друг с другом. Это упрощает управление сведениями о размещении. Каждое действие по размещению или освобождению страницы может выполняться быстро. Это сокращает конфликты между одновременными задачами использования и освобождения страниц.
SQL Server использует два типа карт для записи сведений об использовании экстентов:
- Глобальная карта распределения (GAM)
На GAM-страницах записано, какие экстенты были задействованы. В каждой карте GAM содержатся сведения об использовании 64 000 экстентов или о размещении почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент задействован.
- Общая глобальная карта распределения (SGAM)
На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится сведения об использовании 64 000 экстентов или о размещении почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Это дает простые алгоритмы управления экстентами страниц. Для использования для хранения объекта однородного экстента компонент СУБД Database Engine производит на карте GAM поиск бита 1 и заменяет его на бит 0. Для поиска смешанного экстента со свободными страницами компонент Database Engine производит поиск на карте SGAM бита 1. Для размещения смешанного экстента компонент Database Engine производит на карте GAM поиск бита 1 и заменяет его на бит 0, а затем устанавливает значение соответствующего бита на карте SGAM равным 1. Для освобождения экстента компонент Database Engine устанавливает бит GAM равным 1, а соответствующий бит SGAM равным 0. Внутренние алгоритмы, которые на самом деле используются компонентом Database Engine, более сложны, чем это описано в данном подразделе, так как компонент Database Engine распространяет данные в базе данных равномерно. Однако даже настоящие алгоритмы упрощаются из-за того, что отпадает необходимость управления цепочками сведений о размещении экстентов.
Отслеживание свободного места
На страницы PFS (Page Free Space) записывается состояние размещения каждой страницы, информация о том, была ли отдельная страница использована или нет, а также количество свободного места на каждой странице. В PFS на каждую страницу приходится по одному байту, хранящему информацию о том, была ли страница использована или нет, а если была — то пустая она, или ее заполнение находится в промежутке от 1 до 50 процентов, от 51 до 80 процентов, от 81 до 95 процентов или от 96 до 100 процентов.
После размещения объекта в экстенте компонент Database Engine использует PFS-страницы для записи информации о том, какие страницы в экстенте использованы, а какие свободны. Эти сведения используются компонентом Database Engine при выборе новой страницы для размещения объектов. Количеством свободного места на странице можно управлять только в случае кучи и страниц с типами данных "Текст" и "Примечание". Это используется при поиске страницы, обладающей свободным местом, достаточным для сохранения в ней новой добавляемой строки. Для индексов не требуется, чтобы отслеживалось свободное место на странице, так как место, в которое будет вставляться новая строка, назначается значениями ключа индекса.
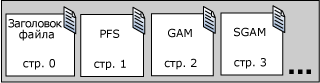
PFS-страница является первой страницей после страницы заголовка файла в файле данных (страница номер 1). Потом следует GAM-страница (страница номер 2), а затем SGAM-страница (страница номер 3). После первой PFS-страницы находится PFS-страница размером примерно 8 000 страниц. После первой GAM-страницы на странице 2 находится другая GAM-страница с 64 000 экстентов и другая SGAM-страница с 64 000 экстентов находится после первой SGAM-страницы на странице номер 3. На рис. 10.5 показана последовательность страниц, используемая компонентом Database Engine, для размещения и управления экстентами.
Краткие итоги: В лекции рассмотрена архитектура одной из наиболее распространенных клиент-серверных СУБД - Microsoft SQL Server. Описаны основные составляющие архитектуры соответствующей СУБД на разных уровнях абстракции. Рассмотрен логический уровень (уровень модели данных СУБД как средство представления концептуальной модели), включающий следующие понятия: таблицы и типы данных, первичные и внешние ключи, индексы, представления, сборки, ограничения, правила, значения по умолчанию). Рассмотрен физический уровень (внутреннее представление данных в памяти ЭВМ - физическая структура базы данных), включающий следующие понятия: файлы и файловые группы, файлы журналов, страницы и экстенты, физическую организацию таблиц и индексов, управление работой с экстентами и памятью).
Более подробно с материалами данной лекции можно ознакомиться в [ [ 10.1 ] , [ 10.2 ] , [ 3.3 ] ]