



|
Добрый день, Я прошёл платный курс по программе «Архитектурные решения на базе аппаратных платформ IBM» получил диплом №ПК 100848460. Как мне получить его ? Вы отправите его почтой ? |
Компания IBM
Опубликован: 09.01.2008 | Доступ: свободный | Студентов: 696 / 141 | Оценка: 4.24 / 4.00 | Длительность: 13:17:00
Специальности: Разработчик аппаратуры
Лекция 2:
Технология POWER
Ядра POWER4 и POWER5
POWER4 415mm2 115W @1.1 GHz, 156W @ 1.3 GHz 174M транзисторов
POWER4+ 267mm2 75W @ 1.2 GHz, 95W @ 1.45 GHz, 125W @ 1.7 GHz 184M транзисторов
POWER5 389mm2 167W @ 1.65 GHz 276M транзисторов
Процессор POWER5 был разработан с учетом двоичной и структурной совместимости с системами POWER4 для обеспечения поддержки всех существующих приложений.
POWER5
- Для систем как начального, так и старшего уровня
- Улучшенная подсистема памяти
- Увеличенная производительность
- Simultaneous Multi-Threading
- Аппаратная поддержка микро-разделов (Shared Processor Partitions)
- Динамическое управление питанием
- Совместимость с POWER4
- Улучшенные функции RAS
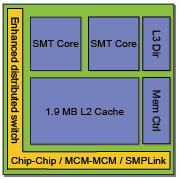
Каждое процессорное ядро имеет отдельный 64 КБ L1 кэш инструкций и 32 КБ L1 кэш данных. L1 кэш совместно используется двумя нитями на процессорном ядре. Оба процессорных ядра совместно используют 1.88 МБ L2 кэш. На процессорном чипе находится контроллер L3 кэша.Сам L3 кэш находится на отдельном чипе - Merged Logic DRAM (MLD) cache chip. L3 кэш - 36 МБ victim cache L2 кэша. L3 совместно используется двумя процессорными ядрами чипа POWER5. L2 и L3 кэши совместно используются всеми аппаратными нитями на обоих процессорных нитях в чипе. В отличие от POWER4, который был ориентирован на приложения систем старшего уровня, дизайн POWER5 ориентирован на широкий спектр приложений – начиная от 1-2-х процессорных систем начального уровня и заканчивая 64-х процессорными серверами старшего уровня.
SMPLink – технология соединения без коммутации с очень малой задержкой, которая позволяет узлам быть соединенными как плоская SMP-система. Порты SMPLink находятся непосредственно на чипе POWER5. При подключении, SMPLink предоставляет прямое соединение между каждым чипом POWER5.
С внедрением SMT, больше инструкций выполняются за такт на процессорном ядре, увеличивая общую частоту переключений на ядре и кристалле.
Улучшенная подсистема памяти
Улучшенный дизайн L1 кэша
- 2-way ассоциативный кэш инструкций
- 4-way ассоциативный кэш данных
- Новый алгоритм замещения (LRU вместо FIFO)
Больший объем L2 кэша
- 1.9 Mб, 10-way ассоциативный кэш
Улучшенный дизайн L3 кэша
- 36 Mб, 12-way ассоциативный кэш
- L3 на процессорной стороне фабрики
- Более частые попадания в кэш
- Избежание трафика на междучипном соединении фабрики
Контроллер каталога и памяти L3 – на чипе
- L3 каталог на чипе уменьшает задержки при на выходе из чипа после "промаха" в L2 кэше
- Уменьшенные задержки при обращении к памяти
Улучшенные алгоритмы
L1 кэш инструкций – двухпоточный, ассоциативный, с политикой замещения LRU (Least Recently Used). L1 кэш инструкций когерентен с L2 кэшем. L1 кэш данных – четырехпоточный, ассоциативный, с политикой замещения LRU (Least Recently Used). Модифицированные данные в L1-кэше не хранятся.
L2 кэш доступен обоим ядрам на чипе. Он поддерживает полную аппаратную когерентность с системой и может поддерживать интервенцию данных в ядра на других чипах POWER5.
1.88 МБ (1920 КБ) L2 кэш физически реализован тремя слоями, каждое размером 640 КБ. Каждый слой имеет отдельные контроллеры. Каждое ядро имеет независимый доступ к каждому контроллеру. Слои – десятипоточные, ассоциативные. Десятипоточная ассоциативность (по сравнению с восьмипоточной на POWER4) позволяет снизить замусориванние кэша путем предоставления болльшего количества мест для хранения данных на каждой линии.
L3 кэш - 36 МБ, доступный обоим ядрам на процессорном чипе POWER5. Он обеспечивает полную аппаратную когерентность с аппаратурой системы и может обеспечивать интервенцию данных в ядра на других процессорных чипах POWER5. Логически, L3 – встроенный (inline) кэш. L3 кэш – не подмножество L2 кэша; одна и та же строка никогда не находится в них обоих одновременно. L3 кэш реализован как внешний, отдельный MLD чип, но его каталог находится на процессорном кристалле. Это помогает процессору проверять каталог после промаха по L2 без дополнительной задержки. L3 кэш в POWER5 находится на процессорной стороне фабрики. Этот дизайн позволяет обслуживать промахи по L2 кэшу чаще, избегая трафика на междучипном соединении.
Контроллер памяти также находится на чипе POWER5, что позволяет снизить задержки при доступе к памяти.
Процессор POWER4 поддерживает максимально 32-х процессорное симметричное мультипроцессирование. Большее количество процессоров увеличивает межпроцессорное взаимодействие, увеличивая тем самым более высокий уровень трафика.Это может негативно повлиять на масштабируемость системы. Перемещение L3-кэша на процессорную сторону фабрики позволяет процессору POWER5 обслуживать промахи по L2 более часто, с попаданиями в L3 кэш, избегая лишнего трафика на межпроцессорном соединении.Это обеспечивает больший уровень масштабирования.Сейчас системы на базе POWER5 поддерживают 64 процессора.
POWER4 содержит на чипе L2 кэш 1.41 МБ. Чип POWER4+ схож по дизайну с POWER4, но сделан по технологии 130 нм, в отличие от POWER4 (180 нм). POWER4+ содержит на чипе L2-кэш 1.5 МБ. POWER4 и POWER4+ имеют L3 кэш размером 32 МБ.
Выполнение инструкций в POWER4
Микропроцессор POWER4 – высокочастотный, со спекулятивной суперскалярностью, с возможностью выполнения инструкций в другом порядке. Восемь независимых модулей выполнения инструкций (execution units) способны выполнять инструкции параллельно, обеспечивая значительный прирост производительности, известный как суперскалярность. Они включают два идентичных модуля выполнения инструкций с плавающей точкой (floating-point execution units), каждый способен выполнить за такт инструкции сложения и умножения (всего четыре операции с плавающей точкой за такт), два модуля загузки-выгрузки (load-store execution units), два модуля выполнения операций с фиксированной точкой (fixed-point execution units), модуль ветвлений (branch execution unit) и модуль условий (conditional register unit), используемый для выполнения логических операций.
Чтобы загрузить их работой, каждый процессор может выбирать до восьми инструкций за такт и может диспетчеризировать и завершать до пяти инструкций за такт. Процессор способен отслеживать около 200 инструкций в каждый момент времени. Инструкции могут выполняться в порядке, отличном от начального, при этом отслеживвается их логический порядок. Инструкции могут выполняться спекулятивно для увеличения производительности, когда может быть сделано точное предсказание логического ветвления.
Александр Панченко