Проектирование и инженерия алгоритма: топологическая сортировка
Нумерация элементов
Чтобы использовать массив, нужно некоторым образом пронумеровать наши элементы. Ранее это было сделано в интересах удобства обращения. Теперь это становится необходимостью, связанной с нашим выбором структуры данных.
Значит ли это, что теперь требуется изменить родовой параметр класса TOPOLOGICAL_SORTER[G], поскольку все манипуляции над элементами будут теперь использовать их целочисленные номера? Абсолютно нет. Остается необходимым для выразительности создать механизм, применимый к элементам любого типа. На практике для этого потребуется хэш-таблица и массив:
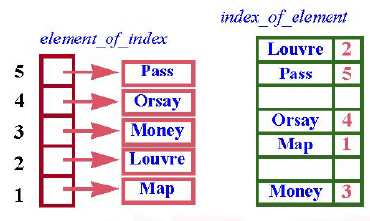
index_of_element: HASH_TABLE [INTEGER, G]
— Для каждого элемента дает его индекс
element_of_index: ARRAY [G]
— Для каждого индекса дает ассоциированный с ним элемент
Элемент хэш-таблицы index_of_element[e] дает целое x – индекс элемента e типа G. В свою очередь, element_of_index[x] = e.
В обоих случаях используется нотация с квадратными скобками.

Обе эти структуры при разумной реализации требуют памяти O(n).
Для определения хэш-таблицы с элементами типа G требуется, чтобы тип G удовлетворял ограничениям наследования – был потомком класса HASHTABLE и объявлен как G -> HASHTABLE (ограниченная универсальность будет подробно рассматриваться в следующей главе, сейчас же понятно, что элементы должны допускать построение хэш-функции).
Класс TOPOLOGICAL_SORTER[G -> HASHTABLE] не будет экспортировать компоненты index_of_element и element_of_index, так как они необходимы только для целей реализации, но мы должны позволять клиентам находить элементы, поскольку это является частью общей задачи работы с элементами, поэтому мы будем экспортировать запрос:
has_element (e: G): BOOLEAN
— Является ли e одним из элементов топологической сортировки?
do
Result:= index_of_element. has (e)
ensure
consistent: Result = index_of_element.has (e) and then
index_of_element [e] >= 1 and then
index_of_element [e] <= element_of_index. count and then
element_of_index [index_of_element [e]] = e
end
Убедитесь, что вы понимаете постусловие.
Давайте теперь докажем, что новые структуры данных позволяют добиться нашей цели – времени O(m + n). Необходимо рассмотреть два аспекта: выполнение операций Т1-Т3 и затраты на инициализацию – создание структур данных predecessor_count и successors. Оба аспекта важны. Если бы для новых структур данных операции Т1-Т3 выполнялись бы за время O(m + n), но для создания структур требовалось бы 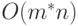 времени, то в целом никакого выигрыша мы бы не получили.
времени, то в целом никакого выигрыша мы бы не получили.
Представляется, что несложно реализовать построение требуемых структур данных за время O(m + n). Обрабатывая последовательно каждое ограничение [x, y], зная y, можно увеличить на 1 значение соответствующего элемента predecessor_count, а зная x, можно добавить последователя y в список соответствующего элемента successors. Обе операции выполняются за константное время. Опуская детали, будем считать далее, что построение структур данных за время O(m + n) возможно и сосредоточимся на рассмотрении операций Т1-Т3.
Базисные операции
Начнем с Т3: "Для заданного элемента x удалить из множества ограничений все ограничения, начинающиеся этим элементом (все пары вида [x, y])". Если мы знаем номер x, то выполнить удаление совсем просто.
В целом операция Т3 требует времени O(m + n) в худшем случае.
Вся только что описанная обработка сопровождается инвариантами класса, выражающими тот факт, что массивы predecessor_count и successors в полной мере отражают структуру оставшихся ограничений отношения.
Рассмотрим теперь операцию Т2: "Для заданного элемента x удалить его из множества элементов". Фактически, для нашей новой структуры данных нам ничего не нужно делать. Выполняя Т3, мы уже позаботились обо всем, что нужно было сделать, удаляя ограничение, начинающееся с x. Отлично!
Осталась операция T1: "Найти элемент без предшественников – или уведомить об отсутствии такового". Для этого достаточно выполнить обход массива predecessor_count и найти элемент со значением 0. Но для этого понадобится время O(n), а для всех элементов 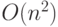 . Это плохо!
. Это плохо!
Нам недостает еще одной структуры данных!
Кандидаты
Нам не избежать O(n) обхода массива predecessor_count при инициализации (предложения from нашего главного цикла) для поиска первоначальных кандидатов – элементов без предшественников в исходном отношении. Если только не каждый элемент включен в цикл, то такие элементы найдутся. Это потребует O(n) времени, но выполнить эту операцию придется лишь один раз, так что пока все хорошо. По ходу процесса топологической сортировки обнаружение кандидатов на удаление – элементов без предшественников – можно получить в качестве побочного эффекта выполняемой операции Т3. Действительно, на этапе L2 мы уменьшаем на 1 число предшественников. Если при этом это число становится равным нулю, то найден новый кандидат. Если ранее этап L2 можно было бы записать в виде:
— Уменьшить на единицу число предшественников y:
predecessor_count [y]:= predecessor_count [y] – 1
то теперь соответствующий код будет выглядеть так:
— Уменьшить на единицу число предшественников y
— и проверить, не становится ли y кандидатом:
predecessor_count [y]:= predecessor_count [y] – 1
[3]
if predecessor_count [y] = 0 then
"Записать, что y не имеет предшественников"
end
"Записать, что y не имеет предшественников" может быть реализовано как добавление в структуру candidates, которая будет заполняться при инициализации и пополняться по ходу обработки. Ее элементами являются еще не обработанные элементы, не имеющие предшественников. Какую конкретную структуру следует выбрать для candidates? Для алгоритма топологической сортировки точный выбор не имеет значения. Важно лишь, чтобы эта структура поддерживала следующие 5 операций.
feature — Access
item: G
— Получить ранее вставленный элемент.
require
not_empty: not is_empty
feature — Measurement
count: INTEGER
— Число элементов.
ensure
non_negative: Result >= 0
feature — Status report
is_empty: BOOLEAN
— Пуста ли структура?
ensure
definition: Result = (count = 0)
feature –- Element change
put (x: G)
— Вставить элемент x.
ensure
one_more: count = old count + 1
remove: G
— Удалить прочитанный элемент.
require
not_empty: not is_empty
ensure
one_fewer: count = old count – 1
Структуры данных с такими свойствами называются распределителями.

Как вы помните, основная идея распределителя в том, что не вы задаете, какой элемент будет получен и удален из распределителя, – стратегия задается типом распределителя. Стеки характеризуются политикой LIFO, очереди – FIFO.
Для топологической сортировки любой распределитель будет выполнять нужную работу. Выбор определенного вида влияет на фактический порядок, в котором будут выводиться элементы (решений, совместимых с ограничениями, может быть несколько). Так что это тот рычаг, которым можно управлять, оптимизируя результат по некоторому критерию. Он позволяет рассматривать семейство алгоритмов топологической сортировки.
Мы можем рассматривать распределитель кандидатов в виде:
candidates: PRIORITY_QUEUE [INTEGER]
— Элементы без предшественников, готовые к удалению
— Дополнительное предложение для инварианта:
— predecessor_count[x] = 0 для каждого элемента x из массива candidates
Реализация распределителя стеком или очередью (STACK или QUEUE) допустима, но очередь с приоритетами является более общим видом, где каждый элемент может сопровождаться приоритетом. В такой очереди элементы отсортированы по приоритетам, и операции item и remove выполняются для элемента с наибольшим приоритетом. Стек и очередь – это специальные случаи, когда приоритет задается порядком поступления элементов. Распределитель PRIORITY_QUEUE позволяет вам, играя приоритетами, управлять политикой выбора.
Цикл, заключительный вид
Мы можем теперь выписать главный цикл алгоритма топологической сортировки – тело процедуры process со всеми деталями. Операторы псевдокода для наглядности сохраним и в этой версии как комментарии. Процедура должна объявить локальные переменные x и y типа INTEGER и x_successors типа LIST[INTEGER], сохраняющего последователей конкретного элемента. Мы также добавим целочисленную переменную processed_count, используемую далее, чтобы сохранять историю того, как много элементов уже обработано.
from
create sorted. make
find_initial_candidates — Смотри далее
invariant
— "Структуры данных представляют подмножество исходных элементов
— и соответствующее подмножество исходного отношения"
until
candidates.is_empty
loop
— "Пусть x – элемент без предшественников в ограничениях"
x:= candidates.item; candidates.remove
sorted.extend (element_of_index [x])
— "Удалим x и все пары в ограничениях, начинающиеся с x"
x_successors:= successors [x] — список
from x_successors.start until x_successors. after loop
y:= x_successors. item
— Следующие несколько строчек взяты из [3]:
predecessor_count [ y]:= predecessor_count [y] – 1
if predecessor_count [ y] = 0 then
— "Записать, что теперь y не имеет предшественников"
candidates. put (y)
end
x_successors. forth end
processed_count:= processed_count + 1
variant
count – processed_count
end
report_cycles — Смотри далее
done:= True
Этот алгоритм предполагает, что массивы predecessor_count и successors правильно сформированы, как и должно быть перед любым вызовом process. Детали инициализации появятся чуть позже.
Процедура find_initial_candidates должна наполнить распределитель candidates элементами, изначально не имеющими предшественников. Она реализуется просто:
find_initial_candidates
— Поместите в массив элементы без предшественников.
local
x: INTEGER
do
if candidates = Void then create candidates end
from x:= 1 until x > count loop
if predecessor_count [x] = 0 then
candidates. put (x)
end
x:= x + 1
end
end
Это обход за время O(n). Без введения такого массива пришлось бы выполнять такой обход на каждом шаге цикла. Теперь достаточно выполнить его один раз в самом начале работы.
Не является ошибкой, если в процедуре не будут найдены элементы, удовлетворяющие условию predecessor_count[x] = 0. Это просто означает, что структура candidates пуста, что цикл завершится незамедлительно и что все элементы включены в какой-либо цикл.
Процедура process по завершении цикла должна выполнить еще одну важную часть работы – она должна уведомить клиента о циклах, встречающихся в отношении. Это и делается при вызове процедуры report_cycles. Чтобы ее реализовать, предварительно заметим, что цикл завершается, когда в массиве candidates не остается элементов. Если исходное отношение было ациклическим, то будут обработаны все элементы, так что можно использовать введенную ранее переменную processed_count, чтобы понять, остались ли элементы, и, если да, то сколько их:
report_cycles
— Сделать информацию о циклах доступной клиентам.
do
if processed_count < count then
— В исходном отношении есть цикл!!
cycle_found:= True
create {LINKED_LIST [G]} cyclists. make
from x:= 1 until x > count loop
if predecessor_count [x] /= 0 then
— x включен в цикл
cyclists. extend (element_of_index [x])
x:= x + 1
end
end
end
Инициализация и время ее выполнения
Мы достигли эффективной реализации за время O(m + n) ядра топологической сортировки – ее основного цикла. Этому способствовали три структуры данных, специально спроектированные для этих целей – массивы predecessor_count и successors и распределитель candidates. Дополняя работу, следует убедиться, что инициализация не нарушает требуемых ограничений на время работы.
Инициализация должна выполнять:
- record_element(e) для каждого элемента – всего n раз;
- record_constraint(e, f) для каждого ограничения – всего m раз.
Работа record_element(e) состоит в том, чтобы присвоить номер элементу e, так чтобы в дальнейшей работе можно было бы использовать целые, а не сами элементы, имеющие тип G.
Это делается согласованным заполнением массива element_of_index и хэш-таблицы index_of_element, задающих взаимное отображение:
record_element (e: G)
— Добавить e в множество элементов, если там его еще нет.
require
not_sorted: not done
do
if not has_element (e) then
count:= count + 1
index_of_element. extend (count, e)
element_of_index. force (e, count)
—extend и force расширяют структуры при необходимости; это означает,
—что нам не требуется знать, сколь много элементов может появиться.
end
ensure
inserted: has_element (e)
one_more: not (old has_element (e)) implies (count = old count + 1)
end
Начальный тест должен убеждать, что процедура игнорирует повторную попытку вставки данного элемента. Эта политика позволяет record_constraint(e, f) стартовать, вызывая record_element как на e, так и на f, просто для того, чтобы убедиться, что элементы вставлены надлежащим образом. В упражнении вас попросят найти способ, позволяющий избежать дублирования работы между has_element и extend.
При подходящей реализации extend и force код процедуры record_element выполняется за O(1), что для всех элементов дает время O(n). Это согласуется с нашими требованиями.
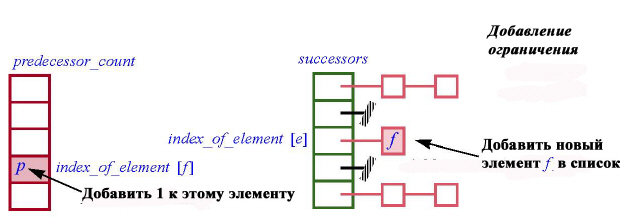
Оставшийся механизм инициализации дается процедурой для ввода ограничений. Вызов record_constraint(e, f) должен увеличивать на 1 число предшественников f в массиве predecessor_count и добавлять f в список последователей e. Этот список является одним из элементов массива successors:
Вот текст процедуры:
record_constraint (e, f: G)
— Добавить ограничение [e, f]
require
not_sorted: not done
exist: e /= Void and f /= Void
local
x, y: INTEGER
do
— Убедиться, что e и f вставлены (нет эффекта, если они уже там присутствуют):
record_element (e); record_element (f )
x:= index_of_element [e]
y:= index_of_element [f ]
predecessor_count [ y]:= predecessor_count [ y] + 1
add_successor (x, y)
ensure
both_there: has_element (e) and has_element (f)
end
Дополнительная процедура, которую можно не экспортировать:
add_successor (x, y: INTEGER)
— Запись y как последователя x.
require
1 <= x; x <= count
1 <= y; y <= count
local
x_successors: LINKED_LIST [INTEGER]
do
x _successors:= successors [x]
— Список последователей для x может быть еще не создан:
if x_successors = Void then
create x_successors. make
successors [x]:= x_successors
end
x_successors. extend (y)
end
Как уже отмечалось, работа record_constraint начинается с двух вызовов record_element для пары аргументов, задаваемых в ограничении. Из-за способа проектирования record_element эффекта от вызова не будет, если элементы уже присутствовали. Эта политика делает возможным для клиентского приложения начинать непосредственно со списка ограничений, никогда явно не обращаясь к записи элементов.
Говоря о дублировании, заметим, что процедура record_constraint не пытается определить, встречалось ли уже вводимое ограничение. Можете убедиться, что алгоритм сортировки корректно будет работать и в случае, когда ограничение повторяется. Применение другой политики, запрещающей дублирование, возлагается на клиента, ответственного за ввод данных.
Вернемся к эффективности. Код каждой из двух дополнительных процедур выполняется за время O(1): доступ к элементу массива, запись в конец списка во втором случае (при хорошей организации списка с курсором в конце операция выполняется за константное время). Так что время работы record_constraint также задается O(1), а поскольку процедура должна отработать для каждого ограничения, в целом получаем O(m). Таким образом, достигнута наша цель: получить алгоритм, выполняющийся за время O(m + n) как на этапе инициализации, так и при выполнении основной задачи – топологической сортировки.
Собираем все вместе
Мы уже познакомились со всеми элементами нашей программы, необходимыми для реализации топологической сортировки. Класс, построенный в полном соответствии с данным обсуждением, доступен в EiffelBase и используется в Traffic, но, полагаю, для проверки вашего понимания концепций следует самостоятельно написать его реализацию, собирая все вместе.
Время программирования!
Напишите класс TOPOLOGICAL_SORTER, обеспечивающий универсальную, практичную топологическую сортировку.
Убедитесь, что решение отвечает принципам инженерии программ, не только обеспечивает эффективный алгоритм, но и включает процедуры инициализации (record_element, record_constraint). Для тестирования решения используйте файл, доступный на сайте, который связан с курсом. Этот файл содержит несколько сотен ограничений и все возможные варианты топологической сортировки.