
|
Добрый день. Я сейчас прохожу курс повышения квалификации - "Профессиональное веб-программирование". Мне нужно получить диплом по этому курсу. Я так полагаю нужно его оплатить чтобы получить диплом о повышении квалификации. Как мне оплатить этот курс?
|
Опубликован: 01.07.2011 | Доступ: свободный | Студентов: 6758 / 1238 | Оценка: 4.07 / 3.64 | Длительность: 10:34:00
Специальности: Программист, Разработчик интернет-проектов
Лекция 8:
Перемещение в DOM
< Лекция 7 || Лекция 8 || Лекция 9 >
Аннотация: Объектная модель документа(DOM - Document Object Model). Представление DOM, как дерева. Узлы. Объект document. Прямой доступ.
Ключевые слова: Web, HTML, вывод, информационное сообщение, объектная модель документа, DOM, document object model, место, объектная модель, доступ, параграф, тег, ссылка, кодирование, поле, базовая, css, пользователь, валидность, браузер, дерево, узел, потомок, иерархия, отображение, информация, максимум, массив, объект, значение, node, firstChild, PHP, ASP, net, атрибут, getElementById, NULL, цикла, em, интерфейс, логический, org
Введение
В Web трудно найти пример полезного кода JavaScript, который не взаимодействует некоторым образом с документом HTML. Говоря в общем, коду необходимо прочитать значения со страницы, обработать их некоторым образом, и затем сгенерировать вывод в форме видимых изменений информационного сообщения. В качестве следующего шага по направлению к созданию быстрых интерфейсов для страниц и приложений эта лекция и следующая знакомит с Объектной моделью документа (DOM - Document Object Model), которая предоставляет механизм для проверки и управления создаваемыми слоями семантики и представления.
После прочтения этой лекции вы будете хорошо понимать, что такое DOM, и как ее можно использовать для перемещения по странице HTML, чтобы точно найти место, в котором необходимо получить некоторые данные или сделать изменения. Следующая лекция в этой серии (Создание и изменение HTML) описывает методы, с помощью которых можно манипулировать данными на странице, изменяя значения или создавая полностью новые элементы и атрибуты.
Данная лекция имеет следующую структуру:
- Высаживаем семена
- Растим деревья
- Узлы
- С ветки на ветку
- Прямой доступ
- Заключение
- Контрольные вопросы
Высаживаем семена
DOM, как можно понять из названия Объектная модель документа, является моделью документа HTML, которая создается браузером, когда он загружает web-страницу. JavaScript имеет доступ ко всей информации этой модели. Давайте вернемся на несколько шагов назад и рассмотрим, что в действительности моделируется.
Когда создается страница, цель разработчика состоит в добавлении смысла к исходному контенту, отображая его в имеющиеся теги HTML. Единицей контента является параграф, поэтому используется тег p, следующей единицей является ссылка, поэтому используется тег а, и т.д. Также выполняется кодирование отношений между элементами: каждое поле input (ввода) имеет label (метку), и они могут объединяться в fieldset. Более того, можно выйти немного за пределы этого базового набора тегов HTML, добавляя, где необходимо, атрибуты id и class, чтобы насытить страницу дополнительными структурами, которые можно использовать для стилевого оформления или манипуляций. Когда эта базовая структура HTML создана, используется CSS для придания этой чистой семантики стилевого представления. И вот, пожалуйста, создана страница, которая доставляет пользователям настоящее удовольствие.
Но это не все. Создан документ просто сочащийся мета-информацией, которой можно манипулировать с помощью JavaScript. Можно находить определенные элементы или группы элементов и удалять, добавлять, и модифицировать их в соответствии с определенными пользователем переменными, можно находить информацию о представлении (CSS) и изменять стили на лету. Можно проверять информацию, которую пользователь вводит в формы, и делать множество других вещей. Чтобы можно было делать это с помощью JavaScript, требуется доступ к информации, которую DOM предоставляет JavaScript.
Важно также отметить, что хорошо структурированный HTML и CSS формируют основу, из которой вырастает модель страницы для JavaScript. Эта модель для плохо сконструированного документа будет отличаться нежелательным образом от ожидаемой, и будет вести себя по-разному в разных браузерах. Поэтому жизненно необходимо, чтобы коды HTML и CSS были правильно сформированы и соответствовали требованиям (были валидными), что обеспечит получение для JavaScript той модели, которая должна быть.
Растим деревья
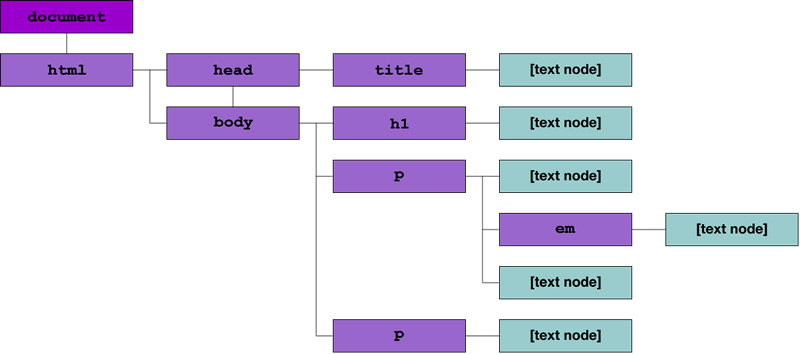
После создания и оформления документа следующий шаг состоит в передаче его браузеру для вывода пользователям. Здесь начинает играть свою роль DOM. Считывая написанный документ, браузер динамически генерирует DOM, который можно использовать в программах. В частности DOM представляет страницу HTML как дерево, почти таким же образом, как можно представить себе генеалогическое семейное дерево пользователя. Каждый элемент на странице представлен в DOM как узел, с ветвями, соединенными с элементами, которые он непосредственно содержит (его потомки ), и с элементом, в котором он непосредственно содержится (его предок). Давайте рассмотрим простой документ HTML, чтобы яснее представить себе эти отношения:
<html>
<head>
<title>This is a Document!</title>
</head>
<body>
<h1>This is a header!</h1>
<p id="excitingText">
This is a paragraph! <em>Excitement</em>!
</p>
<p>
This is also a paragraph, but it's not nearly as exciting as the last one.
</p>
</body>
</html>Как можно видеть, весь документ содержится в элементе html. Этот элемент непосредственно содержит два других: head и body. Они показаны в нашей модели как его потомки, и каждый из них указывает на html, как на предка. И так далее, вниз по иерархии документа, где каждый элемент указывает на своих непосредственных потомков, и на своего непосредственного предшественника предка.
- title является потомком head.
- body имеет три потомка - два элемента p и элемент h1.
- Элемент p с id="excitingText" имеет своего собственного потомка - элемент em.
- Текстовое содержимое элементов (например, "This is a Document!") также представлено в DOM как текстовые узлы. Они не имеют собственных потомков, но указывают содержащие их элементы как предков.
Поэтому получаемая иерархия DOM для показанного выше документа HTML визуально представляется следующим образом:
Это прямолинейное отображение из документа HTML в древовидную структуру, которая сжато представляет прямые отношения между элементами на странице, делая иерархию понятной. Однако можно заметить, что здесь добавлен узел, помеченный document, выше узла html.Это корень документа, который действует как наиболее видимая зацепка для JavaScript в документе.
Узлы
Прежде чем мы начнем рассматривать дерево и перемещаться с ветки на ветку, давайте рассмотрим подробнее, что именно мы будем с ним делать.
Каждый узел дерева DOM является объектом, представляющим один элемент на странице. Узлы знают об отношениях с другими узлами в своей непосредственной близости, и содержат достаточно много информации о себе. Поэтому можно легко получить всю необходимую информацию из узла, чтобы получить доступ к его предку или к потомкам.
Как и можно было ожидать, учитывая объектную природу JavaScript, искомая информация в данном случае находится в свойствах узла. В частности в свойствах parentNode и childNodes. Так как каждый элемент на странице имеет максимум одного предка, то свойство parentNode является простым: оно просто предоставляет доступ к предку узла. Однако узлы могут иметь любое число потомков, поэтому свойство childNodes является в действительности массивом. Каждый элемент массива указывает на одного потомка, в том же порядке, в котором они появляются в документе. Элемент body документа нашего примера будет, поэтому, иметь массив childNodes, содержащий элементы h1, первый p, затем второй p, в данном порядке.
Эти, конечно, не единственные интересные свойства узла. Но это хорошее начало. Какой же код необходимо использовать, чтобы, прежде всего, получить доступ к одному из этих узлов? Где следует начать исследование дерева?
С ветки на ветку
Лучшим местом для старта является корень документа, доступный через объект document. Так как document находится точно в корне, он не имеет свойства parentNode, но имеет единственного потомка: узел элемента html, который доступен через массив childNodes:
var theHtmlNode = document.childNodes[0];
Эта строка кода создает новую переменную с именем theHtmlNode, и присваивает ей значение первого потомка объекта document (вспомните, что массивы JavaScript начинают нумерацию с 0, а не с 1). Можно убедиться, что мы получили доступ к узлу html, проверяя свойство nodeName переменной theHtmlNode, которое предоставляет жизненно важную информацию о точном виде узла, с которым мы имеем дело:
alert( "theHtmlNode is a " + theHtmlNode.nodeName + " node!" );
Этот код выводит окно сообщения, которое содержит "theHtmlNode is a HTML node!" ("theHtmlNode является узлом HTML!"). Отлично! Свойство nodeName предоставляет доступ к типу узла. Для узлов элементов, это свойство содержит имя тега в верхнем регистре: в данном случае это "HTML"; для ссылки это будет "A", для параграфа "P", и т.д. Свойство nodeName текстового узла будет "#text", а nodeName объекта document будет "#document".
Мы знаем также, что theHtmlNode должен содержать ссылку на своего предка. Можно убедиться, что это работает ожидаемым образом, с помощью следующего теста:
if ( theHtmlNode.parentNode == document ) {
alert( "Hooray! The HTML node's parent is the document object!" );
}Это работает, как мы и ожидали. Используя эту информацию, давайте напишем некоторый код для получения ссылки на первый параграф тела примера документа. Это будет второй потомок элемента body, который является вторым потомком элемента html, который является первым потомком объекта document. Вот так!
var theHtmlNode = document.childNodes[0]; var theBodyNode = theHtmlNode.childNodes[1]; var theParagraphNode = theBodyNode.childNodes[1]; alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Отлично. Мы получили то, что хотели. Но в действительности это достаточно многословно, и существует значительно лучший способ для записи этого кода. В лекции об объектах мы узнали, что ссылки на объекты можно соединять цепочкой, то же самое можно сделать здесь, пропуская промежуточные переменные и записывая следующий код:
var theParagraphNode = document.childNodes[0].childNodes[1].childNodes[1]; alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Этот код значительно короче.
Первый потомок узла всегда будет node.childNodes[0], а последний потомок узла всегда будет node.childNodes[node.childNodes.length - 1]. Эти элементы используются достаточно часто, но записывать их снова и снова достаточно громоздко. В связи c этим в DOM имеются для них явные сокращенные записи: .firstChild и .lastChild, соответственно. Так как узел html является первым потомком объекта document, а узел body является последним потомком узла html, можно переписать код еще более коротко следующим образом:
var theParagraphNode = document.firstChild.lastChild.childNodes[1]; alert( "theParagraphNode is a " + theParagraphNode.nodeName + " node!" );
Эти методы перемещения между узлами на близком расстоянии будут полезны, и позволяют оказаться в любом месте документа, но они несколько громоздки. Даже в этом крошечном примере документа можно видеть, насколько трудоемко может быть перемещение из корневого узла в глубину разметки. Должен быть лучший способ для таких задач!
Прямой доступ
В действительности очень сложно определить явные пути доступа для каждого требуемого элемента на странице. Более того, это становится совершенно невозможно, если страница, с которой вы работаете, является в какой-то степени динамически сгенерированной (например, с помощью серверных языков, таких как PHP или ASP.NET), так как невозможно гарантировать, что, например, параграф, который вы ищете, всегда является вторым потомком узла body. Поэтому для доступа к определенному элементу требуется лучший способ, не требующий явного знания его окружения.
Вернемся назад к документу HTML в примере выше. Можно видеть, что у рассмотренного только что параграфа имеется атрибут id. Этот id является уникальным, и идентифицирует определенное место в документе, что позволяет избавиться от явного пути доступа, используя метод getElementById объекта document. Этот метод делает именно то, что вы от него ожидаете, возвращает либо null, если JavaScript получает id, который не существует на странице, или узел запрашиваемого элемента, если он существует. Чтобы проверить это, давайте сравним результаты нового метода со старым:
var theParagraphNode = document.getElementById('excitingText');
if ( document.firstChild.lastChild.childNodes[3] == theParagraphNode ) {
alert( "theParagraphNode is exactly what we expect!" );
}Этот код выводит подтверждающее сообщение, говорящее, что два метода выдают идентичные результаты для примера документа. getElementById является наиболее эффективным способом получения доступа к определенному фрагменту страницы: если вы знаете, что требуется выполнить некоторую обработку где-то на странице (особенно, если вы не можете гарантировать место), добавление атрибута id в соответствующем месте сбережет ваше время.
В равной степени полезным является метод DOM getElementsByTagName,который возвращает совокупность всех элементов на странице определенного типа. Можно, например, заставить JavaScript показать все элементы p на странице. Следующий пример выдает нам все параграфы на странице:
var allParagraphs = document.getElementsByTagName('p');Обработка полученной совокупности, хранящейся в allParagraphs, лучше делать с помощью цикла for: можно работать с совокупностью почти также как с массивом:
for (var i=0; i < allParagraphs.length; i++ ) {
// выполните здесь обработку, используя
// "allParagraphs[i]" для ссылки на
// текущий элемент совокупности
alert( "This is paragraph " + i + "!" );
}Для более сложных документов, получение всех элементов данного типа, может по-прежнему быть чрезмерным. Вместо работы с множеством элементов div на большой странице, скорее всего в действительности необходимо обработка div из определенного раздела. В этом случае можно объединить эти два метода, чтобы профильтровать результаты: выбрать элемент с помощью его id, и опросить его обо всех элементах, заданного типа, которые он содержит. В качестве примера можно было бы выбрать все элементы em параграфа с id="excitingText", выполняя следующее
document.getElementById('excitingText').getElementsByTagName('em')Заключение
DOM является основой почти всего, что делает для нас JavaScript в web. Это интерфейс, который позволяет взаимодействовать с контентом страницы, и важно понимать, как можно использовать эту модель.
Эта лекция рассказала об основных инструментах такой работы. Вы можете теперь легко перемещаться по DOM, используя document, чтобы получить доступ к корню DOM, и childNodes и parentNode для перехода к ближайшим непосредственным связанным узлам. Вы можете пропускать промежуточные узлы и исключать жесткое кодирование длинных и громоздких путей доступа с помощью getElementById и getElementsByTagName для создания своих собственных сокращений. Но возможность побродить по своему дереву является только началом.
Следующий логический шаг состоит в том, чтобы начать делать всякие интересные вещи с полученными результатами. Вам необходимо получить данные, чтобы привести в действие свои сценарии, и манипулировать данными на странице для создания привлекательного взаимодействия с пользователями. Мы исследуем эти вопросы в следующей лекции, показывающей, как использовать методы, которые предоставляет DOM для взаимодействия с узлами и их атрибутами, и для включения этого взаимодействия в будущие сценарии и интерфейсы.
Контрольные вопросы
- Используя пример документа из лекции, напишите три различные пути доступа, которые приводят к элементу head. Не забудьте, что вы можете соединять childNodes и parentNode, как вам может понадобиться.
- Для данного произвольного узла, как можно определить его тип?
- Для данного произвольного узла, как можно вернуться назад к объекту document?
Совет: Вспомните, что свойство parentNode объекта document возвращает null.
Об авторе
Майк Вест является студентом философии, который ловко маскируется под опытного и успешного web-разработчика. Он работает с web более десяти лет, в последнее время в команде, которая отвечает за создание европейских новостных сайтов Yahoo!.
После того как он покинул в 2005 году широкие пригородные равнины Техаса, Майк поселился в Мюнхене, Германия, где он сражается с языком каждый день все в меньшей степени. mikewest.org (http://mikewest.org/) является его домом в web, собирающим (понемногу) его письменные творения и ссылки для потомства. Он хранит свой код на сайте GitHub (http://github.com/mikewest).
< Лекция 7 || Лекция 8 || Лекция 9 >
Сергей Крупко
Галина Башкирова
|
Здравствуйте, недавно закончила курс по проф веб программиованию, мне прислали методические указания с примерами тем, однако темы там для специальности Системный администратор информационно-коммуникационных» систем.
|