Параллельное программирование с использованием OpenMP
7.6. Распределение вычислительной нагрузки между потоками (распараллеливание по задачам при помощи директивы sections)
Напомним, что в рассмотренном ранее учебном материале для построения параллельных программ был изложен подход (см. подразделы 7.2 - 7.3), обычно именуемый распараллеливанием по данным, в рамках которого обеспечивается одновременное (параллельное) выполнение одних и тех же вычислительных действий над разными наборами обрабатываемых данных (например, как в нашем учебном примере, суммирование элементов разных строк матрицы). Другая также широко встречающаяся ситуация состоит в том, что для решения поставленной задачи необходимо выполнить разные процедуры обработки данных, при этом данные процедуры или полностью не зависят друг от друга, или же являются слабо связанными. В этом случае такие процедуры можно выполнить параллельно; такой подход обычно именуется распараллеливанием по задачам. Для поддержки такого способа организации п араллельных вычислений в OpenMP для параллельного фрагмента программы, создаваемого при помощи директивы parallel, можно выделять параллельно выполняемые программные секции (директива sections ).
Формат директивы sections имеет вид:
#pragma omp sections [<параметр> ...]
{
#pragma omp section
<блок_программы>
#pragma omp section
<блок_программы>
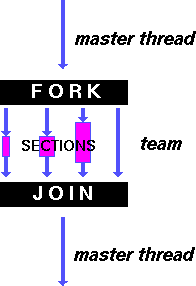
}При помощи директивы sections выделяется программный код, который далее будет разделен на параллельно выполняемые секции. Директивы section определяют секции, которые могут быть выполнены параллельно (для первой по порядку секции директива section не является обязательной) - см. рис. 7.6. В зависимости от взаимного сочетания количества потоков и количества определяемых секций, каждый поток может выполнить одну или несколько секций (вместе с тем, при малом количестве секций некоторые потоки могут оказаться и без секций и окажутся незагруженными). Как результат, можно отметить, что использование секций достаточно сложно поддается масштабированию (настройке на число имеющихся потоков). Кроме того, важно помнить, что в соответствии со стандартом, порядок выполнения программных секций не определен, т.е. секции могут быть выполнены потоками в произвольном порядке.
В качестве примера использования директивы расширим нашу учебную задачу действиями по копированию обрабатываемой матрицы (в качестве исходного варианта используется пример 7.6):
total = 0;
#pragma omp parallel shared(a,b) private(i,j)
{
#pragma omp sections /* Вычисление сумм элементов строк и общей суммы */
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=i; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма элементов строки %d равна %f\n",i,sum);
total = total + sum;
}
#pragma omp section
/* Копирование матрицы */
for (i=0; i < NMAX; i++) {
for (j=i; j < NMAX; j++)
b[i][j] = a[i][j];
}
} /* Завершение параллельного фрагмента */
printf ("Общая сумма элементов матрицы равна %f\n",total);
7.11.
Пример использования директивы sections
Для обсуждения примера можно отметить, что выполняемые в программе вычисления (суммирование и копирование элементов) можно было бы объединить в рамках одних и тех же циклов, однако приведенное разделение тоже может оказаться полезным, поскольку в результате разделения данные вычисления могут быть легко векторизованы (конвейеризированы) компилятором. Важно отметить также, что сформированные подобным образом программные секции не сбалансированы по вычислительной нагрузке (первая секция содержит больший объем вычислений).
В качестве параметров директивы sections могут использоваться:
Все перечисленные параметры уже были рассмотрены ранее. Отметим, что по умолчанию выполнение директивы sections синхронизировано, т.е. потоки, завершившие свои вычисления, ожидают окончания работы всех потоков для одновременного завершения директивы.
В заключение можно добавить, что также как и для директивы for, в случае если в блоке директивы parallel присутствует только директива sections, то данные директивы могут быть объединены. С использованием данной возможности пример 7.11 может быть переработан к виду:
total = 0;
#pragma omp parallel sections shared(a,b) private(i,j)
{
/* Вычисление сумм элементов строк и общей суммы */
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=i; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма элементов строки %d равна %f\n",i,sum);
total = total + sum;
}
#pragma omp section
/* Копирование матрицы */
for (i=0; i < NMAX; i++) {
for (j=i; j < NMAX; j++)
b[i][j] = a[i][j];
}
} /* Завершение параллельного фрагмента */
printf ("Общая сумма элементов матрицы равна %f\n",total);
7.12.
Пример использования объединенной директивы parallel sections
7.7. Расширенные возможности OpenMP
7.7.1. Определение однопотоковых участков для параллельных фрагментов (директивы single и master)
При выполнении параллельных фрагментов может оказаться необходимым реализовать часть программного кода только одним потоком (например, открытие файла). Данную возможность в OpenMP обеспечивают директивы single и master.
Формат директивы single имеет вид:
#pragma omp single [<параметр> ...] <блок_программы>
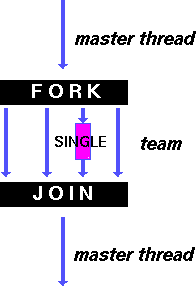
Директива single определяет блок параллельного фрагмента, который должен быть выполнен только одним потоком; все остальные потоки ожидают завершения выполнения данного блока (если не указан параметр nowait ) - см. рис. 7.7.
В качестве параметров директивы могут использоваться:
Новым в приведенном списке является только параметр copyprivate, который обеспечивает копирование переменных, указанных в списке list, после выполнения блока директивы single в локальные переменные всех остальных потоков.
Формат директивы master имеет вид:
#pragma omp master <блок_программы>
Директива master определяет фрагмент кода, который должен быть выполнен только основным потоком; все остальные потоки пропускают данный фрагмент кода (завершение директивы по умолчанию не синхронизируется).
7.7.2. Выполнение барьерной синхронизации (директива barrier)
При помощи директивы barrier можно определить точку синхронизации, которую должны достигнуть все потоки для продолжения вычислений (директива может находиться в пределах как параллельного фрагмента так и параллельной области, т.е. директива является отделяемой).
Формат директивы barrier имеет вид:
#pragma omp barrier
7.7.3. Синхронизация состояния памяти (директива flush)
Директива flush позволяетопределить точку синхронизации, в которой системой должно быть обеспечено единое для всех потоков состояние памяти (т.е. если потоком какое-либо значение извлекалось из памяти для модификации, измененное значение обязательно должно быть записано в общую память).
Формат директивы flush имеет вид:
#pragma omp flush [(list)]
Как показывает формат, директива содержит список list с перечнем переменных, для которых выполняется синхронизация; при отсутствии списка синхронизация выполняется для всех переменных потока.
Следует отметить, что директива flush неявным образом присутствует в директивах barrier, critical, ordered, parallel, for, sections, single.
7.7.4. Определение постоянных локальных переменных потоков (директива threadprivate и параметр copyin директивы parallel)
Как описывалось при рассмотрении директивы parallel, для потоков могут быть определены локальные переменные (при помощи параметров private, firstprivate, lastprivate ), которые создаются в начале соответствующего параллельного фрагмента и удаляются при завершении потоков. В OpenMP имеется возможность создания и постоянно существующих локальных переменных для потоков при помощи директивы threadprivate.
Формат директивы threadprivate имеет вид:
#pragma omp threadprivate (list)
Список list определяет набор определяемых переменных. Созданные локальные копии не видимы в последовательных участках выполнения программы (т.е. вне параллельных фрагментов), но существуют в течение всего времени выполнения программы. Указываемые в списке переменные должны быть уже определены в программе; объявление переменных в директиве должно предшествовать использованию переменных в потоках.
Следует отметить, что использование директивы threadprivate позволяет решить еще одну проблему. Дело в том, что действие параметров private распространяется только на программный код параллельных фрагментов, но не параллельных областей - т.е., например, любая локальная переменная, определенная в параллельном фрагменте функции root на рис. 7.3, будет недоступна в параллельной области функции node. Выход из такой ситуации может быть или в передаче значений локальных переменных через параметры функций или же в использовании постоянных локальных переменных директивы threadprivate.
Отметим еще раз, что полученные в потоках значения постоянных переменных сохраняются между параллельными фрагментами программы. Значения этих переменных можно переустановить при начале параллельного фрагмента по значениям из основного потока при помощи параметра copyin директивы parallel.
Формат параметра copyin директивы parallel имеет вид:
copyin (list)
Для демонстрации рассмотренных понятий приведем пример A.32.1c из стандарта OpenMP 2.5.
#include <stdlib.h>
float* work;
int size;
float tol;
#pragma omp threadprivate(work,size,tol)
void a32( float t, int n )
{
tol = t;
size = n;
#pragma omp parallel copyin(tol,size)
{
build();
}
}
void build()
{
int i;
work = (float*)malloc( sizeof(float)*size );
for( i = 0; i < size; ++i ) work[i] = tol;
}В приведенном примере определяются постоянно существующие локальные переменные work, size, tol для потоков (директива threadprivate ). Перед началом параллельного фрагмента значения этих переменных из основного потока копируются во все потоки (параметр copyin ). Значения постоянно существующих локальных переменных доступны в параллельной области функции build (для обычных локальных переменных потоков их значения пришлось бы передавать через параметры функции).