Параллельное программирование на основе MPI
6.4. Коллективные операции передачи данных
Как уже отмечалось ранее, под коллективными операциями в MPI понимаются операции над данными, в которых принимают участие все процессы используемого коммуникатора. Выделение основных видов коллективных операций было выполнено в разделе 3. Часть из коллективных операций уже была рассмотрена в п. 6.2.3 - это операции передачи от одного процесса всем процессам коммуникатора ( широковещательная рассылка ) и операции обработки данных, полученных на одном процессе от всех процессов ( редукция данных ).
Рассмотрим далее оставшиеся базовые коллективные операции передачи данных.
6.4.1. Обобщенная передача данных от одного процесса всем процессам
Обобщенная операция передачи данных от одного процесса всем процессам ( распределение данных ) отличается от широковещательной рассылки тем, что процесс передает процессам различающиеся данные (см. рис. 6.4). Выполнение данной операции может быть обеспечено при помощи функции:
int MPI_Scatter(void *sbuf,int scount,MPI_Datatype stype,
void *rbuf,int rcount,MPI_Datatype rtype,
int root, MPI_Comm comm),где
- sbuf, scount, stype - параметры передаваемого сообщения ( scount определяет количество элементов, передаваемых на каждый процесс),
- rbuf, rcount, rtype - параметры сообщения, принимаемого в процессах,
- root - ранг процесса, выполняющего рассылку данных,
- comm - коммуникатор, в рамках которого выполняется передача данных.
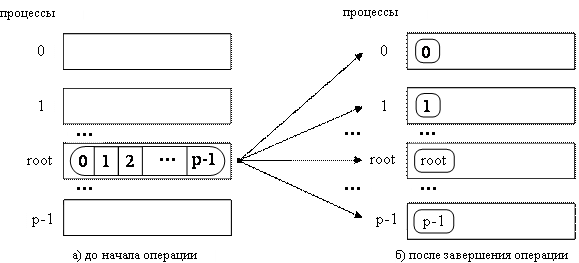
При вызове этой функции процесс с рангом root произведет передачу данных всем другим процессам в коммуникаторе. Каждому процессу будет отправлено scount элементов. Процесс с рангом 0 получит блок данных из sbuf из элементов с индексами от 0 до scount-1, процессу с рангом 1 будет отправлен блок из элементов с индексами от scount до 2* scount-1 и т.д. Тем самым, общий размер отправляемого сообщения должен быть равен scount * p элементов, где p есть количество процессов в коммуникаторе comm.
Следует отметить, поскольку функция MPI_Scatter определяет коллективную операцию, вызов этой функции при выполнении рассылки данных должен быть обеспечен в каждом процессе коммуникатора.
Отметим также, что функция MPI_Scatter передает всем процессам сообщения одинакового размера. Выполнение более общего варианта операции распределения данных, когда размеры сообщений для процессов могут быть разного размера, обеспечивается при помощи функции MPI_Scatterv.
Пример использования функции MPI_Scatter рассматривается в разделе 7 при разработке параллельных программ умножения матрицы на вектор.
6.4.2. Обобщенная передача данных от всех процессов одному процессу
Операция обобщенной передачи данных от всех процессоров одному процессу ( сбор данных ) является обратной к процедуре распределения данных (см. рис. 6.5). Для выполнения этой операции в MPI предназначена функция:
int MPI_Gather(void *sbuf,int scount,MPI_Datatype stype,
void *rbuf,int rcount,MPI_Datatype rtype,
int root, MPI_Comm comm),где
- sbuf, scount, stype - параметры передаваемого сообщения,
- rbuf, rcount, rtype - параметры принимаемого сообщения,
- root - ранг процесса, выполняющего сбор данных,
- comm - коммуникатор, в рамках которого выполняется передача данных.
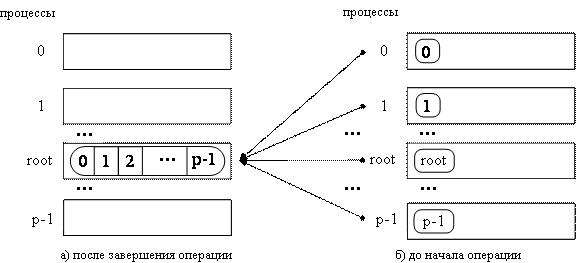
При выполнении функции MPI_Gather каждый процесс в коммуникаторе передает данные из буфера sbuf на процесс с рангом root. Процесс с рангом root собирает все получаемые данные в буфере rbuf (размещение данных в буфере осуществляется в соответствии с рангами процессов-отправителей сообщений). Для того, чтобы разместить все поступающие данные, размер буфера rbuf должен быть равен scount * p элементов, где p есть количество процессов в коммуникаторе comm.
Функция MPI_Gather также определяет коллективную операцию, и ее вызов при выполнении сбора данных должен быть обеспечен в каждом процессе коммуникатора.
Следует отметить, что при использовании функции MPI_Gather сборка данных осуществляется только на одном процессе. Для получения всех собираемых данных на каждом из процессов коммуникатора необходимо использовать функцию сбора и рассылки:
int MPI_Allgather(void *sbuf, int scount, MPI_Datatype stype,
void *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm).Выполнение общего варианта операции сбора данных, когда размеры передаваемых процессами сообщений могут быть различны, обеспечивается при помощи функций MPI_Gatherv и MPI_Allgatherv.
Пример использования функции MPI_Gather рассматривается в разделе 7 при разработке параллельных программ умножения матрицы на вектор.
6.4.3. Общая передача данных от всех процессов всем процессам
Передача данных от всех процессов всем процессам является наиболее общей операцией передачи данных (см. рис. 6.6). Выполнение данной операции может быть обеспечено при помощи функции:
int MPI_Alltoall(void *sbuf,int scount,MPI_Datatype stype,
void *rbuf,int rcount,MPI_Datatype rtype,MPI_Comm comm),где
- sbuf, scount, stype - параметры передаваемых сообщений,
- rbuf, rcount, rtype - параметры принимаемых сообщений
- comm - коммуникатор, в рамках которого выполняется передача данных.
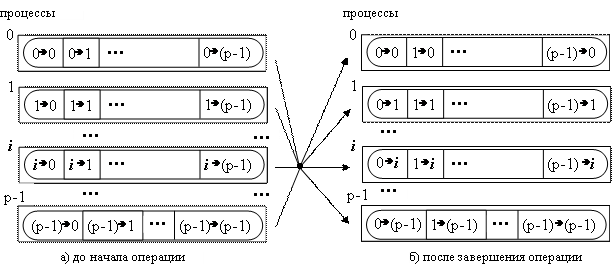
Рис. 6.6. Общая схема операции передачи данных от всех процессов всем процессам (сообщения показываются обозначениями вида i в j, где i и j есть ранги передающих и принимающих процессов соответственно
При выполнении функции MPI_Alltoall каждый процесс в коммуникаторе передает данные из scount элементов каждому процессу (общий размер отправляемых сообщений в процессах должен быть равен scount * p элементов, где p есть количество процессов в коммуникаторе comm ) и принимает сообщения от каждого процесса.
Вызов функции MPI_Alltoall при выполнении операции общего обмена данными должен быть выполнен в каждом процессе коммуникатора.
Вариант операции общего обмена данных, когда размеры передаваемых процессами сообщений могут быть различны, обеспечивается при помощи функций MPI_Alltoallv.
Пример использования функции MPI_Alltoall рассматривается в разделе 7 при разработке параллельных программ умножения матрицы на вектор как задание для самостоятельного выполнения.
6.4.4. Дополнительные операции редукции данных
Рассмотренная в п. 6.2.3.2 функция MPI_Reduce обеспечивает получение результатов редукции данных только на одном процессе. Для получения результатов редукции данных на каждом из процессов коммуникатора необходимо использовать функцию редукции и рассылки:
int MPI_Allreduce(void *sendbuf, void *recvbuf,int count,MPI_Datatype type, MPI_Op op,MPI_Comm comm).
Функция MPI_AllReduce выполняет рассылку между процессами всех результатов операции редукции. Возможность управления распределением этих данных между процессами предоставляется функций MPI_Reduce_scatter.
И еще один вариант операции сбора и обработки данных, при котором обеспечивается получение и всех частичных результатов редуцирования, может быть получен при помощи функции:
int MPI_Scan(void *sendbuf, void *recvbuf,int count,MPI_Datatype type, MPI_Op op,MPI_Comm comm).
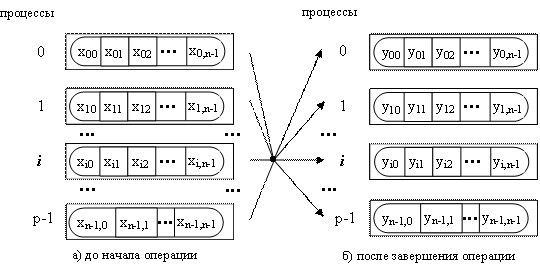
Общая схема выполнения функции MPI_Scan показана на рис. 6.7. Элементы получаемых сообщений представляют собой результаты обработки соответствующих элементов передаваемых процессами сообщений, при этом для получения результатов на процессе с рангом i, 0 i<n,используются данные от процессов, ранг которых меньше или равен i,т.е.

где  есть операция, задаваемая при вызове функции MPI_Scan.
есть операция, задаваемая при вызове функции MPI_Scan.
6.4.5. Сводный перечень коллективных операций данных
Для удобства использования сводный перечень всего рассмотренного учебного материала о коллективных операциях передачи данных представлен в виде табл. 6.3.