Хранение данных и доступ к ним
11.5 Представление таблиц в базах данных реляционного типа
В современных СУБД используются следующие виды таблиц:
- обычная таблица типа куча (heap);
- многоверсионные (темпоральные, временные) таблицы;
- кластеризованные таблицы;
- индексно-организованные таблицы;
- временные таблицы;
- материализованные представления;
- секционированные таблицы;
- внешние таблицы.
Чаще всего используются обычные таблицы. Их организация в формате кучи означает, что строки такой таблицы не упорядочены.
Особенность многоверсионных (темпоральных) таблиц в том, что они, в отличие от heap-таблиц хранят не только текущие, но и все прежние состояния данных. В действительности многоверсионные таблицы это сложные конструкции. Например, в Oracle при замене обычной таблицы на много-версионную сама таблица переименовывается, создается представление с исходным именем таблицы, создается несколько триггеров типа INSTEAD OF для реализации работы с темпоральными данными и ряд других структур.
Кластеризованные таблицы это набор, состоящий обычно из двух таблиц, соединенных внешним ключом. Кластеры бывают индексированные и хэшированные. Особенность кластера в способе организации хранения данных. Связанные строки таблиц хранятся по возможности в одном блоке. Это существенно ускоряет запросы по общему (кластерному) ключу, но может замедлить другие запросы. Вариант хэш-кластера более эффективен при поиске по точному соответствию, но мало эффективен при поиске по диапазону.
Индексно-организованные таблицы это B*-индексы, в которых листовые узлы вместо ссылок на строки таблицы содержат саму строку.
Временные таблицы предназначены для хранения данных во время транзакции или сеанса. Это промежуточные таблицы при расчетах или составлении отчетов. Обычно данные временной таблицы невидимы из других сеансов или транзакций. По завершении транзакции или сеанса данные временных таблиц удаляются.
Материализованные представления создаются, когда необходимо собрать значительное количество данных, к которым необходимо обращаться многократно. Это по сути дела хранимая таблица, построенная по данным базовых обычных таблиц или представлений. У нее может быть дополнительное свойство — автоматически поддерживать актуальность данных, если в базовых таблицах происходят изменения.
Секционирование таблицы в некоторых СУБД обеспечивает хранение больших структур (таблиц, индексов, материализованных представлений, а также бинарных и символьных больших объектов) в нескольких сегментах, может быть распределенных в сети. Созданная структура поддерживается СУБД, так что обращение к ней производится также как обычно, а вызовы распределяются по сегментам хранения автоматически. Разбиение объекта может быть горизонтальным и вертикальным. Для его организации достаточно при создании хранимого объекта указать способ секционирования.
В качестве примера, представим себе организацию, распределенную в пространстве. Каждый филиал должен иметь доступ к строкам таблицы emp описывающим своих сотрудников, а центральному офису нужны и свои данные и данные филиалов. Тогда условием разбиения по вертикали может быть принадлежность сотрудника филиалу. Строки таблицы emp размещаются на всех серверах филиалов и центральном сервере, но все они принадлежат одной секционированной таблице emp. У программиста нет проблем с именованием частных таблиц и с выбором сервера, на котором находятся данные.
На секционированную таблицу можно создавать секционированные индексы, также прозрачные для пользователя.
Внешние таблицы это некоторые объекты, лежащие вне базы, например, таблицы Excel. Их можно только читать.
11.6 Доступ к данным
Рассмотрим основные способы доступа к данным одной или многих таблиц. Знакомство с ними позволит нам в разделе 11.7 разобраться с планами исполнения запросов.
Как вы помните, в базах данных используются декларативные языки, определяющие свойства получаемых данных, но ничего не говорящих о том, как этот результат получить. Планы исполнения добавляют необходимую процедурную компоненту.
11.6.1 Доступ к единственной таблице
Существует два варианта доступа к одной таблице:
- полное сканирование таблицы;
- индексный доступ к таблице.
Полное сканирование таблицы это чтение всех блоков таблицы без использования индексов. Одна из возможных неприятностей в том, что при использовании стратегии LRU сканирование большой таблицы может удалить из кэша многие блоки данных и индексов других таблиц. Это вызвало бы снижение производительности запросов к другим таблицам. Чтобы этого не случилось, алгоритм изменяют так, чтобы блоки, полученные при полном сканировании большой таблицы, отправлялись в хвост кэша. По миновании необходимости, их заменяют на следующую группу блоков.
11.6.2 Соединения
Рассмотренные в "Язык SQL" эталонные алгоритмы выполнения запросов SQL к нескольким таблицам, основаны на создании декартового произведения, которое даже для не очень больших таблиц вычисляется неприемлемо медленно.
Мы рассмотрим три способа реализации соединений, используемые в практике — соединения при помощи вложенных циклов (nested loops), соединения хешированием (hash join) и соединения с сортировкой слиянием
(merge join). В соединениях хэшированием и с сортировкой слиянием сначала обращаются к каждой таблице отдельно, а затем соединяют соответствующие строки и отбрасывают ненужные.
В дальнейшем это позволит нам понимать конструкции планов исполнения запросов SQL. А овладение знаниями и навыками управления планами исполнения — это еще один слой знаний SQL, совершенно необходимый для написания запросов на профессиональном уровне.
Первый вариант — соединение при помощи вложенных циклов (рисунок 11.8)

Внешний цикл выполняет фактически однотабличный запрос к ведущей таблице, используя только условия, относящиеся к этой таблице. Каждая найденная строка передается внутреннему циклу, который, перебирая строки ведомой таблицы, ищет по одной все подходящие строки. Первая такая строка формирует первую строку результата, передавая ее в итоговую таблицу. После того, как будут перебраны все строки ведомой таблицы, внешний цикл, выберет следующую строку ведущей таблицы и т.д.
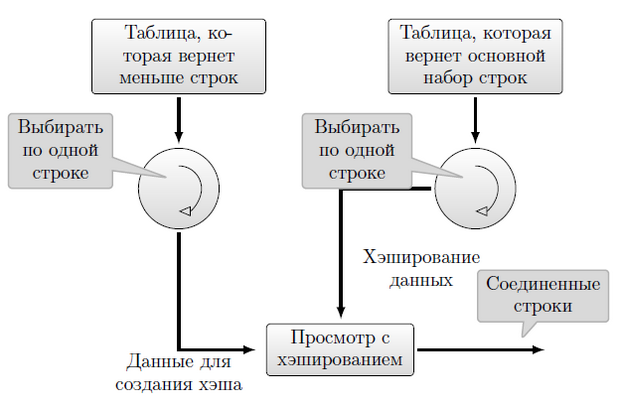
Второй вариант — соединение хешированием (рисунок 11.9) Два цикла выполняют фактически независимые оптимизированные од-нотабличные запросы к исходным таблицам, используя для каждой свои условия. Оптимизатор выбирает таблицу, которая вернет меньше строк и строит по ней хеш-функцию. Затем выполняется второй запрос с подборкой для результатов соответствующей области хеширования.
Третий вариант — соединение с сортировкой слиянием (рисунок 11.10) Таблицы считываются независимо. Оба результирующих набора предварительно сортируются по ключу соединения и затем соединяются.

Можно представлять, что два отсортированных списка помещены рядом. Указатели смещаются с верхних записей только вниз. При временно фиксированном левом указателе правый идет вниз до конца, задерживаясь только на соединяемых записях. Затем левый указатель опускается на шаг, а правый начинает движение вниз с позиции на строку ниже, чем в предыдущем цикле.
Сравним соединения:
- Соединение при помощи вложенных циклов каждый раз формирует в оперативной памяти единственную строку результата. Требуется немного оперативной памяти. Место на диске не нужно. Можно создавать огромные результирующие таблицы при ограниченной оперативной памяти.
- В соединении хэшированием набор строк, который предполагали меньшим, может оказаться неожиданно большим. Тогда потребуется дополнительное пространство на диске и процесс замедлится. Соединение хэшированием следует предпочесть соединению при помощи вложенных циклов только если есть уверенность в том, что меньший набор строк поместится в оперативную память.
- В соединении с сортировкой слиянием предварительная сортировка данных может занять много времени и ресурсов. Если необходимо выбрать между соединениями с сортировкой слиянием и с хэшированием рекомендуется выбирать соединения с хэшированием.