|
Очень много ошибок в тестах. Другие люди их тоже нашли. Но прошло очень много времени и похоже что ошибки не собираются исправлять. Очень обидно что на такой большой платформе такая медленная реакция. |
Опубликован: 18.04.2021 | Доступ: свободный | Студентов: 1168 / 654 | Длительность: 04:36:00
Лекция 1:
Введение в методологию DevOps. Основные определения
Аннотация: Дано определение DevOps как методологии, основные определения. Рассмотрены сферы знаний, которые нужны для старта карьеры DevOps инженера.
Цель:Получить вводные знания по DevOps, ознакомится с методологией и основными определениями.
DevOps инженер - такую вакансию часто можно встретить на сайтах по поиску работы. На различных технических ресурсах постоянно обсуждаются облака, инфраструктура, деплой(развертывание) приложений. Поэтому может сложиться ощущение, что DevOps - это технология, которая позволяет деплоить приложения.
Но это не совсем верно. DevOps это не технология и не язык программирования. Сам по себе DevOps это методология разработки программного обеспечения.
Основные определения:
- DevOps (от англ. development and operations) - методология активного взаимодействия специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимная интеграция их рабочих процессов друг в друга для обеспечения качества продукта.
- Деплой (англ. deploy) - развертывание, - помещение исполняемого кода на сервер, где он будет работать.
- Билд (англ. build) - процесс сборки и/или компиляции программного продукта
- Артефакт - готовая для использования сборка продукта
- Релиз - версионированный артефакт сборки
- Окружение - изолированный набор серверов и/или сервисов
- Продакшн - обозначение окружения для клиентов
- Тест - среда (песочница, англ sandbox), которая используется для тестирования приложения.
- Стейджинг - это среда для тестирования, которая в точности похожа на продакшен-окружение.
- Конвейер (англ. pipeline) - набор процессов организованный в последовательность по типу конвейера позволяющий непрерывно производить программные артефакты.
(Продакшн, тест, стейджинг - эти определения относятся к окружениям окружения )
Методология DevOps сосредоточена на коммуникации, сотрудничестве и интеграции между подразделениями разработки и эксплуатации. Создание продукта требует больших временных затрат и состоит из нескольких итераций, таких как разработка идеи-концепции, написание кода, тестирование, деплой приложения. Конечной целью является качественный продукт, доставленный вовремя. Над этим работает команда разработчиков, тестировщики и адмнинов. Каждая команда обладает своей зоной ответственности.
Разработчики пишут код, причем каждый пишет свою часть,которую потом интегрирует в общий продукт.
Тестировщик занимается тестированием какой-то части продукта, после тестирования продукт либо уходит на следующий шаг - продакшн, либо возвращается разработчику для устранения багов (ошибок).
Задача operations команды, в свою очередь, заключается в том, чтобы готовый код правильно функционировал в различных средах разработки.
Все команды взаимно зависят друг от друга, без их взаимодействия и эффективной коммуникации продукт разработан не будет.
Каждая итерация требует временных затрат и, конечно же, компаниям-разработчикам программного обеспечения и заказчикам этого программного продукта хочется сократить время поставки без потери качества. Сделать это за счет сокращения времени написания кода или тестирования, невозможно.
Экономия времени возможна только за счет сокращения времени простоя между итерациями разработки ПО. Другими словами, за счет сокращения времени ожидания командами своей работы.
Это и предлагает DevOps методология - обеспечить эффективное и быстрое взаимодействие между командами.
Теперь у вас есть понимание классической DevOps методологии. На практике чаще всего применяются DevOps концепции, относящиеся к инфраструктуре приложений, а под DevOps инженером понимаю специалиста, который отвечает за инфраструктуру, развертывание, мониторинг и доступность приложений. Также DevOps инженер отвечает за настройку окружений для разработчика, тестировщика и в продакшене.
DevOps концепции, которые используются чаще всего на практике.
SaaS. PaaS. IaaS.
- System(Software) as a Service.
- Platform as a Service
- Infrastructure as a Service
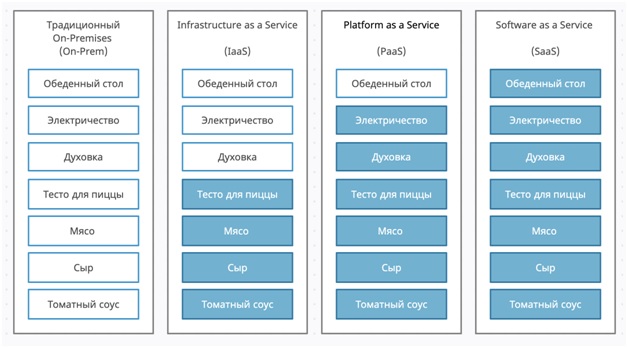
Эти три понятия приобрели популярность в последние лет десять, и представляют собой единую концепцию по которой некоторая услуга предоставляет в формате сервиса, которым вы пользуетесь как функционалом, или API, или любая другая форма. Достаточно часто эти концепции объясняются на примере пиццы (Рис. 1.1):
Незакрашенные элементы - ваша зона ответственности, закрашенные элементы - зона ответственности провайдера
- On-premises - вы все настраиваете самостоятельно
- В IaaS - вы получает только инфраструктуру приложения
- В PaaS - вы получаете инфраструктуру и подготовленное для разработки приложений программное обеспечение
- В SaaS - вы получаете готовое работающее в облаке приложение.
Pet vs Cattle
Концепция, название которой переводится как "Домашние питомцы против рогатого скота". Звучит странно, поэтому на русский язык название концепции чаще всего не переводится. В целом концепция заключается в двух различных подходах к управлению системами на серверах.
Подход Pet - этот подход довольно старый, но все еще актуальный. Заключается он в том, что система на серверах устанавливается один раз, и далее конфигурируется под любые нужды, а в случае поломки чинится.
Подход Cattle - более свежий, появившийся с распространением виртуальных серверов. Заключается в том, что система зачастую предварительно настроена уже в самом образе из которого она разворачивается. Если же система сервера повреждена, система просто уничтожается и разворачивается новая копия.
Оба подхода имеют право на жизнь и используются по сей день в разных видах, но уже чаще на разных уровнях и с разными типами приложений.
К примеру подход Cattle используется когда время простоя неприемлемо в силу невозможности переноса приложения на другой сервер или балансировки подключений. К примеру - гипервизоры, базы данных. Несмотря на то что буквально недавно получили достаточно широкое распространение технологии позволяющие перенести процесс (вместе с оперативной памятью и прочим) с одного сервера на другой не останавливая сам процесс. Это предельно сложная и затратная операция, и в случае гипервизора - по затратам дешевле починить систему на существующем, нежели переносить все ресурсы на новый сервер. Еще один пример - поддержка GitLab на своих серверах. Несмотря на прекрасное разделение ролей между компонентами приложения, опять таки проще, поддерживать в хорошем состоянии один сервер, чем перемещать хранилище, подключения к базе, очереди, обработчики задач и прочее с сервера на сервер.
С другой стороны, многие веб-приложения прекрасно работают вне своего состояния и не требуют много локальных ресурсов хранилища, что позволяет перенаправить трафик, просто пристрелив некорректно работающее приложение и поднять вместо старого экземпляра - новый.
Минусы и плюсы разумеется есть у обоих подходов, и в основном это касается ресурсов затрачиваемых на поддержку системы и глубины знаний требуемых для поддержки этой самой системы.
Рустам Тагаев