Опубликован: 03.05.2012 | Доступ: свободный | Студентов: 3241 / 781 | Оценка: 4.39 / 4.14 | Длительность: 19:41:00
Тема: Сетевые технологии
Лекция 4:
Цифровая модуляция
Амплитудно фазовая модуляция с подавлением несущей
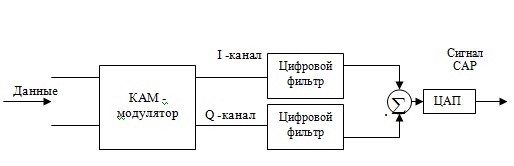
Амплитудно- фазовая модуляция с подавлением несущей (Carrierless Amplitude and Phase Modulation – CAP) представляет собой форму КАМ (иногда ее называют амплитудно-фазовая модуляция без несущей). При этом виде модуляции ( рис. 4.14) устанавливаются фильтры на синфазный канал (канал I) и квадратурный канал (канал Q) для подавления несущей частоты. Фильтры создаются на базе цифровых сигнальных процессоров (DSP). Фильтр синфазного канала преобразует данные канала I в косинусоидальные колебания, тогда как фильтр квадратурного канала преобразует данные канала Q в синусоидальные колебания. Преобразование фильтров такого типа обычно привязано к частоте несущей, так что на приемном конце можно восстановить несущую.
После сложения синфазного и квадратурного сигнала XE "синфазного и квадратурного сигнала" , результирующий сигнал преобразуется в аналоговый с помощью цифро-аналогового преобразователя XE "цифро-аналогового преобразователя" (ЦАП).
Сверточные и решетчатые коды
Сверточное кодирование XE "Сверточное кодирование" – метод непрерывного кодирования и декодирования. Эти коды относятся к классу прямого исправления ошибок FEC (Forward Error Correction), т.е. без использования обратного канала.
В случае сверточного на вход кодера поступает последовательность символов источника, а с выхода кодера снимается также непрерывная последовательность символов, которая является функцией входных символов и структуры кодера. Каждый входной символ, состоящий из k, битов преобразуется в n-битовый поток.
На рис.4.16 показан принцип построения сверточного кодера
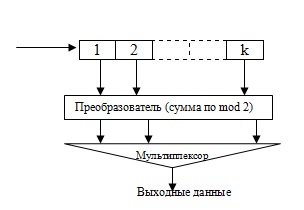
Сверточный кодер состоит из регистра сдвига из 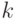 ячеек, блока сумматора по
ячеек, блока сумматора по  , входы соединены с некоторыми выходами регистра сдвига (в соответствии с принятой передаточной функцией
, входы соединены с некоторыми выходами регистра сдвига (в соответствии с принятой передаточной функцией  ).
).
Таким образом, на каждом такте в регистр сдвига последовательно поступает блок из исходных информационных символов. В том же такте на выходе преобразователя формируется кодовая последовательность длиной  последовательных символов. С помощью мультиплексора они передаются в канал.
последовательных символов. С помощью мультиплексора они передаются в канал.
Скорость поступления исходных данных равна  от выходной канальной скорости. Длина регистра сдвига, определяет длину кодируемого блока и называется длиной кодового ограничения.
от выходной канальной скорости. Длина регистра сдвига, определяет длину кодируемого блока и называется длиной кодового ограничения.
На рис.4.16 показаны два типа кодеров. Оба кодера называют кодерами с кодовой скоростью XE "кодовой скоростью" 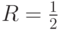 поскольку скорость исходных данных равна половине канальной скорости данных. В каждый интервал времени один входной бит порождает 2 выходных бита. Как показано на рис. 4.16 Кодер с кодовым ограничением 2 выдает логическую сумму по модулю 2 битов
поскольку скорость исходных данных равна половине канальной скорости данных. В каждый интервал времени один входной бит порождает 2 выходных бита. Как показано на рис. 4.16 Кодер с кодовым ограничением 2 выдает логическую сумму по модулю 2 битов 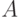 и
и 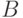 вместе с непосредственным значением . Кодер на рисунке 4.16 порождает сумму двух перекрывающихся полей (
вместе с непосредственным значением . Кодер на рисунке 4.16 порождает сумму двух перекрывающихся полей (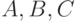 и
и 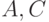 ). В этом случае логическая сумма битов равна единицы, тогда и только тогда когда нечетное число битов равно 1. На рис.4.16 длина регистра равна 2, следовательно, это кодер имеет кодовое ограничение XE "кодовое ограничение" равное 2. Поскольку выходной задающий генератор имеет скорость в два раза большую входной скорости канальная скорость, (канальное ограничение) будет 4. Аналогично кодер на рис.4.17б имеет кодовое ограничение XE "кодовое ограничение" 3 и канальное ограничение 6.
). В этом случае логическая сумма битов равна единицы, тогда и только тогда когда нечетное число битов равно 1. На рис.4.16 длина регистра равна 2, следовательно, это кодер имеет кодовое ограничение XE "кодовое ограничение" равное 2. Поскольку выходной задающий генератор имеет скорость в два раза большую входной скорости канальная скорость, (канальное ограничение) будет 4. Аналогично кодер на рис.4.17б имеет кодовое ограничение XE "кодовое ограничение" 3 и канальное ограничение 6.
Большие по величине кодовые ограничения дают лучшие характеристики.Поскольку кодер на рис.4.16 имеет наименьшее из возможных кодовое ограничение XE "кодовое ограничение" , он обычно не используется, но удобен для иллюстрации основного принципа работы сверточного кодера. На рис. 4.17 показаны два примера сверточного кодирования. На рисунке 4.17а для кодового ограничения  и на рис.4.17б для кодового ограничения 3.
и на рис.4.17б для кодового ограничения 3.
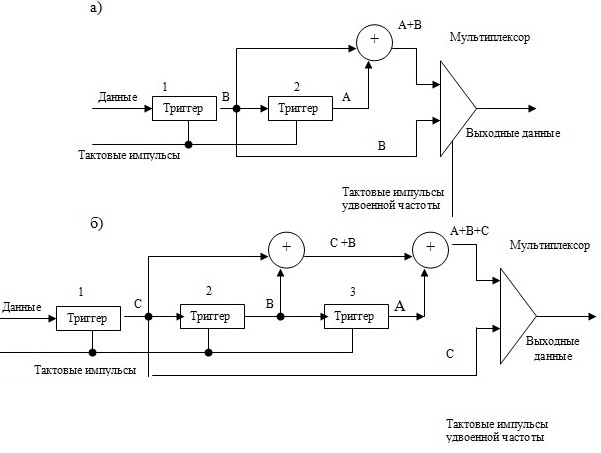
Рис. 4.17. Сверточные кодеры с кодовой скоростью 1/2 а – с кодовым ограничение 2; б- с кодовым ограничением равным 3
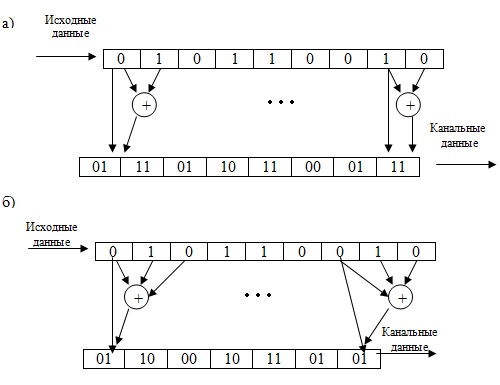
Рис. 4.18. Пример последовательностей данных для сверточного кодирования с параметрами: скорость кодирования R=1/2 и длиной ограничения: а) k=2; б) k=3
Ниже приводится алгоритм обработки входной последовательности в выходную последовательность для рис.4.17б.

Сверточный декодер обычно обрабатывает сигнал согласно алгоритму Витерби по методу максимального правдоподобия XE "методу максимального правдоподобия" [ 69 ] . Идея этого метода состоит в том, что последовательность отсчетов принимаемого сигнала сравнивается со всеми возможными входными канальными последовательностями, для определения символа исходных данных выбирается наиболее близкая последовательность.
Помехозащищенность кода в большой степени зависит от еще одной характеристики сверточного кода свободного расстояния 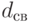 , под которым понимают расстояние по Хэминнгу между двумя полубесконечными последовательностями.
, под которым понимают расстояние по Хэминнгу между двумя полубесконечными последовательностями.
Предположим, что имеются две одинаковые входные последовательности. Если их подавать на вход кодера то, будет порождаться одинаковая выходная последовательность. Предположим, что одна входная последовательность будет содержать символ отличный от другой (например, 0, а в другой последовательности 1). Тогда при сверточном кодировании, начиная с этого бита, сверточный код будет давать различающиеся комбинации.
Свободное расстояние показывает какое наименьшее количество ошибок должно произойти в канале, чтобы одна кодовая последовательность была расшифрована как другая и ошибки не были обнаружены.
Выгрыш от кодирования XE "Выгрыш от кодирования" при кодовом ограничении XE "кодовом ограничении" равном 7 равен 5 дБ. При о кодовой скорости необходимо удвоение ширины полосы, что увеличивает величину шума на 3 дБ, то суммарный выигрыш составляет 2 дБ. Поиск хороших сверточных кодов ( с наибольшим при заданной кодовой скорости и кодовом ограничении XE "кодовом ограничении" ) осуществляется обычно методом перебора. Для иллюстрации рассмотрим следующий пример.
Пример. Определить логику декодирования данных полученных сверточным декодером, показанном на рис.4.17а. Будем считать, что побитные проверки проводятся для каждого принимаемого бита канальной последовательности и рассматриваются изолированно друг от друга.
Решение. При рассмотрении изолированных канальных ошибках возможны два случая: ошибка в исходном бите или ошибка в бите, полученном сложением  . Если исходный бит содержал ошибку, то в то мы получим также ошибку суммы
. Если исходный бит содержал ошибку, то в то мы получим также ошибку суммы 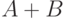 (исключающее ИЛИ). Тогда если мы обнаружим две смежных ошибки, то наиболее вероятное решение состоит в том, что искажен, бит . Если с ошибкой принят, бит суммы, наиболее вероятно, что это искажение самого бита суммы и не было ошибки исходных данных. Поэтом ошибки суммы не учитываются.
(исключающее ИЛИ). Тогда если мы обнаружим две смежных ошибки, то наиболее вероятное решение состоит в том, что искажен, бит . Если с ошибкой принят, бит суммы, наиболее вероятно, что это искажение самого бита суммы и не было ошибки исходных данных. Поэтом ошибки суммы не учитываются.
В общем случае, сверточное кодирование хорошо подходит для исключения независимых ошибок. Далее мы знаем, блочное кодирование (например, коды Рида – Соломона,см. раздел 4.9.) удобны в средах с пакетными ошибками. Из этих соображений часто используются комбинации этих двух видов кодирования.