|
Здравствуйте! Прошел курс, а где экзамен? Как сертификат получить? Без экзамена? |
Опубликован: 17.03.2025 | Доступ: свободный | Студентов: 7 / 0 | Длительность: 07:30:00
Лекция 7:
Архитектура процессоров
RISC процессоры ARM
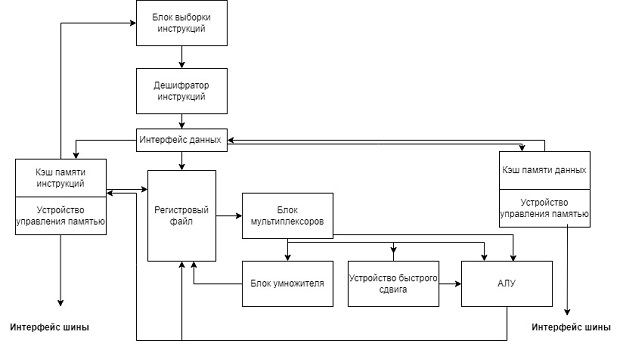
ARM процессоры - это коммерческие лицензируемые ядра процессоров, построенные с использованием RISC команд, но с технологическими особенностями организации этого ядра. Компания ARM, разработчик различных инженерных решений, продает лицензии и документацию на ядро процессора конечным производителям микропроцессоров. Разработчики, используя свои периферийные модули и другие вычислительные блоки, добавляя их к ядру ARM, получают готовое решение. На рисунке 7.7 представлена упрощенная структурная схема процессора ARM9, реализованная на описаниях из разных информационных источников [4,5]. На структурной схеме можно выделить следующие блоки:
- Регистровый файл содержит в себе регистры общего назначения - стандартное решение для RISC архитектур, с особенностями применения в зависимости от режима работы процессора;
- АЛУ - арифметико-логическое устройство;
- Устройство быстрого сдвига находится вне АЛУ, позволяет сдвигать входные данные на заданное число бит до операции в АЛУ;
- Блок умножителя, работающий по алгоритму Бута
- Кэш память инструкций и кэш память данных являются памятью быстрого доступа для ускорения выполнения операций. Быстродействие достигается за счет предварительной загрузки из основной памяти, тем самым снижая время обращения к ней.
- Блок выборки и инструкций и дешифратор инструкций - часть системы управления процессора. Они выбирают команды из памяти и осуществляют коммутацию блоков процессора;
- Блок мультиплексоров участвует в распараллеливании доступа к операционным блокам процессора;
- Интерфейс данных - часть общей системы управления, участвующая в распараллеливании процессов, а также включающая в себя регистр флагов для управления переходами;
- Устройство управления памятью (MMU) - блок трансляции "виртуальны адресов " программ в физические адреса памяти.
Более подробная информация об организации работы процессоров, существующих архитектурах, методах работы с памятью приводится в литературе [1,2] и дополнительной литературе [2,3].
Для понимания различий в архитектуре рассмотренных процессоров реализуем решение задачи по вычислению чисел Фибоначчи на языках ассемблера (ISA). Предварительно приведем код для вычисления чисел Фибоначчи на языке Си (листинге 7.1).
include <stdio.h >
int main() {
int n= 10; // количество чисел Фибоначчи
unsigned long long fib[10]; // массив для хранения чисел Фибоначчи
// инициализация первых двух чисел Фибоначчи
fib[0] = 0;
fib[1] = 1;
// вычисление чисел Фибоначчи
for (int i = 2; i < n; i++) {
fib[i] = fib[i - 1] + fib[i - 2];
}
// вывод чисел Фибоначчи
printf("Первые %d чисел Фибоначчи:\n", n);
for (int i = 0; i < n; i++) {
printf("%llu ", fib[i]);
}
printf("\n");
return 0;
}
Листинг
7.1.
Для описанного выше примера приведем код на языке ассемблера процессора x86, реализованного в компиляторе NASM (листинге 7.2)
section .data
fmt db "Fibonacci(%d) = %d", 10, 0 ; Формат строки для вывода
n db 5; Измените здесь для получения n-го числа Фибоначчи
section .bss
result resd 1; Результат вычисления
section .text
extern printf; Импорт функции printf
global main; Точка входа в программу
main:
; Загружаем значение n
movzx ecx, byte [n]; Загружаем n в ecx
mov eax, 0; fib(0)
mov ebx, 1; fib(1)
cmp ecx, 0; Если n = 0
je .done; Переход к завершению
cmp ecx, 1; Если n = 1
je .next; Переход к следующему
; Итеративная часть
.loop:
;Вычисляем n-е число Фибоначчи
mov edx, eax ; Сохраняем предыдущую Fibonacci (fib(n-2))
add eax, ebx; fib(n) = fib(n-1) + fib(n-2)
mov ebx, edx; Обновляем fib(n-1) на fib(n-2)
dec ecx; Уменьшаем счетчик
jnz .loop; Повторяем до n = 0
.next:
; Задаем результат для вывода
mov [result], eax ; Сохраняем результат
.done:
; Вывод результата
push eax; Параметр: значение Fibonacci
push dword [n]; Параметр: n
push fmt; Строка для printf
call printf; Вызов функции printf
add esp, 12; Очистка стека
; Завершение программы
mov eax, 1; sys_exit
xor ebx, ebx; Устанавливаем код возврата 0
int 0x80; Вызов ядра
Листинг
7.2.
Приведем решение данной задачи на языке ассемблера для микроконтроллера Atmega328P. Код приведен в листинге 7.3.
.section .text .global fib fib: ; Сохранение регистров push r16 push r17 mov r16, r24 ; Инициализация значений ldi r18, 0; Заносим первое значение ldi r19, 1; Заносим второе значение ; Проверяем (0 или 1) cp r16, r18 breq .fib_done cp r16, r19 breq .fib_done ; Цикл вычислений ldi r20, 2 ldi r21, 0 .fib_loop: cp r20, r16 breq .fib_done ; Вычисления чисел Фибоначчи add r21, r18 mov r18, r19 mov r19, r21 ; Увеличение счетчика inc r20 ; Проверка окончания цикла .fib_loop brne .fib_loop ; Возврат по окончании вычислений call .fib_done .fib_done: mov r24, r19; Сохранение итога ; Завершение программы pop r17 pop r16 retЛистинг 7.3.
Далее приводится код на ассемблере ARM процессора. Код разработан для микрокомпьютера Raspberry Pi 2/3 (листинг 7.4).
.section .data
fib_num: .asciz "Fibonacci: %d\n" // Форматированная строка для вывода
.section .bss
num1: .skip 4 // Первый элемент массива
num2: .skip 4 // Второй элемент массива
result: .skip 4 // Результат
.section .text
.global _start
.extern printf // Объявление функции printf
_start:
ldr r0, =0 // num1 = 0
str r0, num1
ldr r0, =1 // num2 = 1
str r0, num2
mov r1, #0 // Счетчик
mov r2, #10 // Количество чисел Фибоначчи для вычисления
fib_loop:
ldr r0, num1
ldr r3, num2
add r0, r0, r3 // r0 = num1 + num2
str r0, result
ldr r0, =fib_num // Указатель на строку
ldr r1, result // Результат для передачи в printf
bl printf
ldr r0, num2 // Обновление num1
str r0, num1
str r0, num2
add r1, r1, #1
cmp r1, r2
blt fib_loop // Если r1 < r2, продолжаем цикл
mov r0, #0 // Код возврата 0
bx lr // Завершение программы
Листинг
7.4.
В приложении А приводится краткая система команд данных процессоров.
Вячеслав Сагитов