
|
Не обнаружил проекты, которые используются в примерах в лекции, также не увидел список задач. |
Тверской государственный университет
Опубликован: 22.11.2005 | Доступ: свободный | Студентов: 30526 / 1911 | Оценка: 4.31 / 3.69 | Длительность: 28:26:00
ISBN: 978-5-9556-0050-5
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Лекция 15:
Регулярные выражения
Пример "обратные ссылки"
В этом примере рассматривается ранее упоминавшаяся, но не описанная возможность задания в регулярном выражении обратных ссылок. Можно ли описать с помощью регулярных выражений язык, в котором встречаются две подряд идущие одинаковые подстроки? Ответ на этот вопрос отрицательный, поскольку грамматика такого языка должна быть контекстно-зависимой, и нужна память, чтобы хранить уже распознанные части строки. Аппарат регулярных выражений, предоставляемый классами пространства RegularExpression, тем не менее, позволяет решить эту задачу. Причина в том, что расширение стандартных регулярных выражений в Net Framework является не только синтаксическим. Содержательные расширения связаны с введением понятия группы, которой отводится память и дается имя. Это и дает возможность ссылаться на уже созданные группы, что и делает грамматику языка контекстно-зависимой. Ссылка на ранее полученную группу называется обратной ссылкой. Признаком обратной ссылки является пара символов " \k ", после которой идет имя группы. Приведу пример:
Console.WriteLine("Ссылка назад - второе вхождение слова");
strpat = @"\s(?<word>\w+)\s\k'word'";
str = "I know know that, You know that!";
FindMatches(str, strpat);Рассмотрим более подробно регулярное выражение, заданное строкой strpat. В группе, заданной скобочным выражением, после знака вопроса идет имя группы " word ", взятое в угловые скобки. После имени группы идет шаблон, описывающий данную группу, в нашем примере шаблон задается произвольным идентификатором " \w+ ". В дальнейшем описании шаблона задается ссылка на группу с именем " word ". Здесь имя группы заключено в одинарные кавычки. Поиск успешно справился с поставленной задачей, подтверждением чему являются результаты работы этого фрагмента кода.
Пример "Дом Джека"
Давайте вернемся к задаче разбора предложения на элементы. В классе string для этого имеется метод Split, который и решает поставленную задачу. Однако у этого метода есть существенный недостаток, - он не справляется с идущими подряд разделителями и создает для таких пар пустые слова. Метод Split класса Regex лишен этих недостатков, в качестве разделителей можно задавать любую пару символов, произвольное число пробелов и другие комбинации символов. Повторим наш прежний пример:
public void TestParsing()
{
string str,strpat;
//разбор предложения - создание массива слов
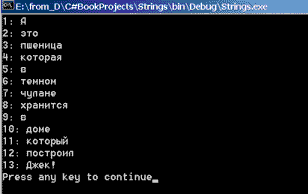
str = "А это пшеница, которая в темном чулане
хранится," +" в доме, который построил Джек!";
strpat =" +|, +";
Regex pat = new Regex(strpat);
string[] words;
words = pat.Split(str);
int i=1;
foreach(string word in words)
Console.WriteLine("{0}: {1}",i++,word);
}//TestParsingРегулярное выражение, заданное строкой strpat, определяет множество разделителей. Заметьте, в качестве разделителя задан пробел, повторенный сколь угодно много раз, либо пара символов - запятая и пробел. Разделители задаются регулярными выражениями. Метод Split применяется к объекту pat класса Regex. В качестве аргумента методу передается текст, подлежащий расщеплению. Вот как выглядит массив слов после применения метода Split.
Пример "Атрибуты"
Как уже говорилось, регулярные выражения особенно хороши при разборе сложных текстов. Примерами таковых могут быть различные справочники, различные текстовые базы данных, весьма популярные теперь XML-документы, разбором которых приходится заниматься. В качестве заключительного примера рассмотрим структурированный документ, строки которого содержат некоторые атрибуты, например, телефон, адрес и e-mail. Структуру документа можно задавать по-разному; будем предполагать, что каждый атрибут задается парой "имя: Значение" Наша задача состоит в том, чтобы выделить из строки соответствующие атрибуты. В таких ситуациях регулярное выражение удобно задавать в виде групп, где каждая группа соответствует одному атрибуту. Приведу начальный фрагмент кода очередной тестирующей процедуры, в котором описываются строки текста и образцы поиска:
public void TestAttributes()
{
string s1 = "tel: (831-2) 94-20-55 ";
string s2 = "Адрес: 117926, Москва, 5-й Донской проезд,
стр.10,кв.7 ";
string s3 = "e-mail: Valentin.Berestov@tverorg.ru ";
string s4 = s1+ s2 + s3;
string s5 = s2 + s1 + s3;
string pat1 = @"tel:\s(?<tel>\((\d|-)*\)\s(\d|-)+)\s";
string pat2= @"Адрес:\s(?<addr>[0-9А-Яа-я \-\,\.]+)\s";
string pat3 =@"e-mail:\s(?<em>[a-zA-Z\.@]+)\s";
string compat = pat1+pat2+pat3;
string tel="", addr = "", em = "";Строки s4 и s5 представляют строку разбираемого документа. Их две, для того чтобы можно было проводить эксперименты, когда атрибуты в документе представлены в произвольном порядке. Каждая из строк pat1, pat2, pat3 задает одну именованную группу в регулярном выражении, имена групп - tel, Адрес, e-mail - даются в соответствии со смыслом атрибутов. Сами шаблоны подробно описывать не буду - сделаю лишь одно замечание. Например, шаблон телефона исходит из того, что номеру предшествует код, заключенный в круглые скобки. Поскольку сами скобки играют особую роль, то для задания скобки как символа используется пара - " \( ". Это же касается и многих других символов, используемых в шаблонах, - точки, дефиса и т.п. Строка compat представляет составное регулярное выражение, содержащее все три группы. Строки tel, addr и em нам понадобятся для размещения в них результатов разбора. Применим вначале к строкам s4 и s5 каждый из шаблонов pat1, pat2, pat3 в отдельности и выделим соответствующий атрибут из строки. Вот код, выполняющий эти операции:
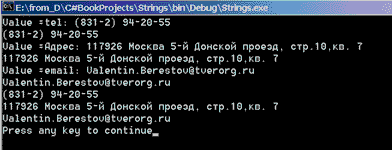
Regex reg1 = new Regex(pat1);
Match match1= reg1.Match(s4);
Console.WriteLine("Value =" + match1.Value);
tel= match1.Groups["tel"].Value;
Console.WriteLine(tel);
Regex reg2 = new Regex(pat2);
Match match2= reg2.Match(s5);
Console.WriteLine("Value =" + match2.Value);
addr= match2.Groups["addr"].Value;
Console.WriteLine(addr);
Regex reg3 = new Regex(pat3);
Match match3= reg3.Match(s5);
Console.WriteLine("Value =" + match3.Value);
em= match3.Groups["em"].Value;
Console.WriteLine(em);Все выполняется нужным образом - создаются именованные группы, к ним можно получить доступ и извлечь найденный значения атрибутов. А теперь попробуем решить ту же задачу одним махом, используя составной шаблон compat:
Regex comreg = new Regex(compat); Match commatch= comreg.Match(s4); tel= commatch.Groups["tel"].Value; Console.WriteLine(tel); addr= commatch.Groups["addr"].Value; Console.WriteLine(addr); em= commatch.Groups["em"].Value; Console.WriteLine(em); }// TestAttributes
И эта задача успешно решается. Взгляните на результаты разбора текста.
На этом и завершим рассмотрение регулярных выражений а также лекции, посвященные работе с текстами в C#.