|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Московский физико-технический институт
Опубликован: 24.08.2004 | Доступ: свободный | Студентов: 25878 / 9653 | Оценка: 4.37 / 4.06 | Длительность: 19:18:00
ISBN: 978-5-9556-0044-4
Тема: Операционные системы
Лекция 14:
Сети и сетевые операционные системы
Проблемы адресации в сети
Любой пакет информации, передаваемый по сети, должен быть снабжен адресом получателя. Если взаимодействие подразумевает двустороннее общение, то в пакет следует также включить и адрес отправителя. В лекции 4 мы описали один из протоколов организации надежной связи с использованием контрольных сумм, нумерации пакетов и подтверждения получения неискаженного пакета в правильном порядке. Для отправки подтверждений обратный адрес также следует включать в пересылаемый пакет. Таким образом, практически каждый сетевой пакет информации должен быть снабжен адресом получателя и адресом отправителя. Как могут выглядеть такие адреса?
Несколько раньше, обсуждая отличия взаимодействия удаленных процессов от взаимодействия локальных процессов, мы говорили, что удаленные адресаты должны обладать уникальными адресами уже не в пределах одного компьютера, а в рамках всей сети. Существует два подхода к наделению объектов такими сетевыми адресами: одноуровневый и двухуровневый.
Одноуровневые адреса
В небольших компьютерных сетях можно построить одноуровневую систему адресации. При таком подходе каждый процесс, желающий стать участником удаленного взаимодействия (при прямой адресации), и каждый объект, для такого взаимодействия предназначенный (при непрямой адресации), получают по мере необходимости собственные адреса (символьные или числовые), а сами вычислительные комплексы, объединенные в сеть, никаких самостоятельных адресов не имеют. Подобный метод требует довольно сложного протокола обеспечения уникальности адресов. Вычислительный комплекс, на котором запускается взаимодействующий процесс, должен запросить все компьютеры сети о возможности присвоения процессу некоторого адреса. Только после получения от них согласия процессу может быть назначен адрес. Поскольку процесс, посылающий данные другому процессу, не может знать, на каком компоненте сети находится процесс-адресат, передаваемая информация должна быть направлена всем компонентам сети (так называемое широковещательное сообщение – broadcast message ), проанализирована ими и либо отброшена (если процесса-адресата на данном компьютере нет), либо доставлена по назначению. Так как все данные постоянно передаются от одного комплекса ко всем остальным, такую одноуровневую схему обычно применяют только в локальных сетях с прямой физической связью всех компьютеров между собой (например, в сети NetBIOS на базе Ethernet), но она является существенно менее эффективной, чем двухуровневая схема адресации.
Двухуровневые адреса
При двухуровневой адресации полный сетевой адрес процесса или промежуточного объекта для хранения данных складывается из двух частей – адреса вычислительного комплекса, на котором находится процесс или объект в сети ( удаленного адреса ), и адреса самого процесса или объекта на этом вычислительном комплексе ( локального адреса ). Уникальность полного адреса будет обеспечиваться уникальностью удаленного адреса для каждого компьютера в сети и уникальностью локальных адресов объектов на компьютере. Давайте подробнее рассмотрим проблемы, возникающие для каждого из компонентов полного адреса.
Удаленная адресация и разрешение адресов
Инициатором связи процессов друг с другом всегда является человек, будь то программист или обычный пользователь. Как мы неоднократно отмечали в лекциях, человеку свойственно думать словами, он легче воспринимает символьную информацию. Поэтому очевидно, что каждая машина в сети получает символьное, часто даже содержательное имя. Компьютер не разбирается в смысловом содержании символов, ему проще оперировать числами, желательно одного и того же формата, которые помещаются, например, в 4 байта или в 16 байт. Поэтому каждый компьютер в сети для удобства работы вычислительных систем получает числовой адрес. Возникает проблема отображения пространства символьных имен (или адресов) вычислительных комплексов в пространство их числовых адресов. Эта проблема получила наименование проблемы разрешения адресов.
С подобными задачами мы уже сталкивались, обсуждая организацию памяти в вычислительных системах (отображение имен переменных в их адреса в процессе компиляции и редактирования связей) и организацию файловых систем (отображение имен файлов в их расположении на диске). Посмотрим, как она может быть решена в сетевом варианте.
Первый способ решения заключается в том, что на каждом сетевом компьютере создается файл, содержащий имена всех машин, доступных по сети, и их числовые эквиваленты. Обращаясь к этому файлу, операционная система легко может перевести символьный удаленный адрес в числовую форму. Такой подход использовался на заре эпохи глобальных сетей и применяется в изолированных локальных сетях в настоящее время. Действительно, легко поддерживать файл соответствий в корректном виде, внося в него необходимые изменения, когда общее число сетевых машин не превышает нескольких десятков. Как правило, изменения вносятся на некотором выделенном административном вычислительном комплексе, откуда затем обновленный файл рассылается по всем компонентам сети.
В современной сетевой паутине этот подход является неприемлемым. Дело даже не в размерах подобного файла, а в частоте требуемых обновлений и в огромном количестве рассылок, что может полностью подорвать производительность сети. Проблема состоит в том, что добавление или удаление компонента сети требует внесения изменений в файлы на всех сетевых машинах. Второй метод разрешения адресов заключается в частичном распределении информации о соответствии символьных и числовых адресов по многим комплексам сети, так что каждый из этих комплексов содержит лишь часть полных данных. Он же определяет и правила построения символических имен компьютеров.
Один из таких способов, используемый в Internet, получил английское наименование Domain Name Service или сокращенно DNS. Эта аббревиатура широко используется и в русскоязычной литературе. Давайте рассмотрим данный метод подробнее.
Организуем логически все компьютеры сети в некоторую древовидную структуру, напоминающую структуру директорий файловых систем, в которых отсутствует возможность организации жестких и мягких связей и нет пустых директорий. Будем рассматривать все компьютеры, входящие во Всемирную сеть, как область самого низкого ранга (аналог корневой директории в файловой системе) – ранга 0. Разобьем все множество компьютеров области на какое-то количество подобластей (domains). При этом некоторые подобласти будут состоять из одного компьютера (аналоги регулярных файлов в файловых системах), а некоторые – более чем из одного компьютера (аналоги директорий в файловых системах). Каждую подобласть будем рассматривать как область более высокого ранга. Присвоим подобластям собственные имена таким образом, чтобы в рамках разбиваемой области все они были уникальны. Повторим такое разбиение рекурсивно для каждой области более высокого ранга, которая состоит более чем из одного компьютера, несколько раз, пока при последнем разбиении в каждой подобласти не окажется ровно по одному компьютеру. Глубина рекурсии для различных областей одного ранга может быть разной, но обычно в целом ограничиваются 3 – 5 разбиениями, начиная от ранга 0.
В результате мы получим дерево, неименованной вершиной которого является область, объединяющая все компьютеры, входящие во Всемирную сеть, именованными терминальными узлами – отдельные компьютеры (точнее – подобласти, состоящие из отдельных компьютеров), а именованными нетерминальными узлами – области различных рангов. Используем полученную структуру для построения имен компьютеров, подобно тому как мы поступали при построении полных имен файлов в структуре директорий файловой системы. Только теперь, двигаясь от корневой вершины к терминальному узлу – отдельному компьютеру, будем вести запись имен подобластей справа налево и отделять имена друг от друга с помощью символа ".".
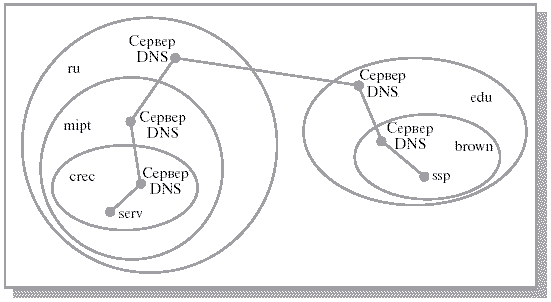
Допустим, некоторая подобласть, состоящая из одного компьютера, получила имя serv, она входит в подобласть, объединяющую все компьютеры некоторой лаборатории, с именем crec. Та, в свою очередь, входит в подобласть всех компьютеров Московского физико-технического института с именем mipt, которая включается в область ранга 1 всех компьютеров России с именем ru. Тогда имя рассматриваемого компьютера во Всемирной сети будет serv.crec.mipt.ru. Аналогичным образом можно именовать и подобласти, состоящие более чем из одного компьютера.
В каждой полученной именованной области, состоящей более чем из одного узла, выберем один из компьютеров и назначим его ответственным за эту область – сервером DNS. Сервер DNS знает числовые адреса серверов DNS для подобластей, входящих в его зону ответственности, или числовые адреса отдельных компьютеров, если такая подобласть включает в себя только один компьютер. Кроме того, он также знает числовой адрес сервера DNS, в зону ответственности которого входит рассматриваемая область (если это не область ранга 1), или числовые адреса всех серверов DNS ранга 1 (в противном случае). Отдельные компьютеры всегда знают числовые адреса серверов DNS, которые непосредственно за них отвечают.
Рассмотрим теперь, как процесс на компьютере serv.crec.mipt.ru может узнать числовой адрес компьютера ssp.brown.edu. Для этого он обращается к своему DNS -серверу, отвечающему за область crec.mipt.ru, и передает ему нужный адрес в символьном виде. Если этот DNS -сервер не может сразу представить необходимый числовой адрес, он передает запрос DNS -серверу, отвечающему за область mipt.ru. Если и тот не в силах самостоятельно справиться с проблемой, он перенаправляет запрос серверу DNS, отвечающему за область 1-го ранга ru. Этот сервер может обратиться к серверу DNS, обслуживающему область 1-го ранга edu, который, наконец, затребует информацию от сервера DNS области brown.edu, где должен быть нужный числовой адрес. Полученный числовой адрес по всей цепи серверов DNS в обратном порядке будет передан процессу, направившему запрос (см. рис. 14.2).
В действительности, каждый сервер DNS имеет достаточно большой кэш, содержащий адреса серверов DNS для всех последних запросов. Поэтому реальная схема обычно существенно проще, из приведенной цепочки общения DNS -серверов выпадают многие звенья за счет обращения напрямую.
Рассмотренный способ разрешения адресов позволяет легко добавлять компьютеры в сеть и исключать их из сети, так как для этого необходимо внести изменения только на DNS -сервере соответствующей области.
Если DNS -сервер, отвечающий за какую-либо область, выйдет из строя, то может оказаться невозможным разрешение адресов для всех компьютеров этой области. Поэтому обычно назначается не один сервер DNS, а два – основной и запасной. В случае выхода из строя основного сервера его функции немедленно начинает выполнять запасной.
В реальных сетевых вычислительных системах обычно используется комбинация рассмотренных подходов. Для компьютеров, с которыми чаще всего приходится устанавливать связь, в специальном файле хранится таблица соответствий символьных и числовых адресов. Все остальные адреса разрешаются с использованием служб, аналогичных службе DNS. Способ построения удаленных адресов и методы разрешения адресов обычно определяются протоколами сетевого уровня эталонной модели.
Мы разобрались с проблемой удаленных адресов и знаем, как получить числовой удаленный адрес нужного нам компьютера. Давайте рассмотрим теперь проблему адресов локальных: как нам задать адрес процесса или объекта для хранения данных на удаленном компьютере, который в конечном итоге и должен получить переданную информацию.
Локальная адресация. Понятие порта
Во второй лекции мы говорили, что каждый процесс, существующий в данный момент в вычислительной системе, уже имеет собственный уникальный номер – PID. Но этот номер неудобно использовать в качестве локального адреса процесса при организации удаленной связи. Номер, который получает процесс при рождении, определяется моментом его запуска, предысторией работы вычислительного комплекса и является в значительной степени случайным числом, изменяющимся от запуска к запуску. Представьте себе, что адресат, с которым вы часто переписываетесь, постоянно переезжает с место на место, меняя адреса, так что, посылая очередное письмо, вы не можете с уверенностью сказать, где он сейчас проживает, и поймете все неудобство использования идентификатора процесса в качестве его локального адреса. Все сказанное выше справедливо и для идентификаторов промежуточных объектов, использующихся при локальном взаимодействии процессов в схемах с непрямой адресацией.
Для локальной адресации процессов и промежуточных объектов при удаленной связи обычно организуется новое специальное адресное пространство, например представляющее собой ограниченный набор положительных целочисленных значений или множество символических имен, аналогичных полным именам файлов в файловых системах. Каждый процесс, желающий принять участие в сетевом взаимодействии, после рождения закрепляет за собой один или несколько адресов в этом адресном пространстве. Каждому промежуточному объекту при его создании присваивается свой адрес из этого адресного пространства. При этом удаленные пользователи могут заранее договориться о том, какие именно адреса будут зарезервированы для данного процесса, независимо от времени его старта, или для данного объекта, независимо от момента его создания. Подобные адреса получили название портов, по аналогии с портами ввода-вывода.
Необходимо отметить, что в системе может существовать несколько таких адресных пространств для различных способов связи. При получении данных от удаленного процесса операционная система смотрит, на какой порт и для какого способа связи они были отправлены, определяет процесс, который заявил этот порт в качестве своего адреса, или объект, которому присвоен данный адрес, и доставляет полученную информацию адресату. Виды адресного пространства портов (т. е. способы построения локальных адресов ) определяются, как правило, протоколами транспортного уровня эталонной модели.
Полные адреса. Понятие сокета (socket)
Таким образом, полный адрес удаленного процесса или промежуточного объекта для конкретного способа связи с точки зрения операционных систем определяется парой адресов: <числовой адрес компьютера в сети, порт>. Подобная пара получила наименование socket (в переводе – "гнездо" или, как стали писать в последнее время, сокет ), а сам способ их использования – организация связи с помощью сокетов . В случае непрямой адресации с использованием промежуточных объектов сами эти объекты также принято называть сокетами. Поскольку разные протоколы транспортного уровня требуют разных адресных пространств портов, то для каждой пары надо указывать, какой транспортный протокол она использует, – говорят о разных типах сокетов.
В современных сетевых системах числовой адрес обычно получает не сам вычислительный комплекс, а его сетевой адаптер, с помощью которого комплекс подключается к линии связи. При наличии нескольких сетевых адаптеров для разных линий связи один и тот же вычислительный комплекс может иметь несколько числовых адресов. В таких системах полные адреса удаленного адресата (процесса или промежуточного объекта) задаются парами <числовой адрес сетевого адаптера, порт> и требуют доставки информации через указанный сетевой адаптер.
Федор Антонов
Сергей Семёнов
|
Здравствуйте. Подскажите пожалуйста, где можно найти слайды презентаций для лекций? |