Опубликован: 12.02.2014 | Доступ: свободный | Студентов: 924 / 239 | Длительность: 11:22:00
Тема: Программирование
Специальности: Программист
Лекция 11:
Парсеры
Аннотация: Изучаются синтаксические анализаторы, или парсеры. Синтаксический анализатор проверяет строку на соответствие грамматике. Результатом анализа, или разбора строки является дерево разбора, листьями которого являются терминальные символы грамматики, а остальными вершинами – нетерминальные символы. Рассматривается парсер некоторых английский предложений, арифметических выражений и составных термов языка Пролог. Реализуется алгоритм поиска наибольшего общего унификатора.
В настоящей главе изучаются синтаксические анализаторы, или парсеры. Синтаксический анализатор проверяет строку на соответствие грамматике.
Формальная грамматика — это четверка вида 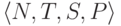 , где
, где 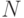 — множество нетерминальных символов,
— множество нетерминальных символов, 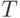 — множество терминальных символов,
— множество терминальных символов, 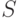 — начальный нетерминальный символ,
— начальный нетерминальный символ, 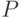 — множество правил. Множества и не пересекаются В контекстно-свободной грамматике правила, в форме Бэкуса-Наура (БНФ), имеют вид:
— множество правил. Множества и не пересекаются В контекстно-свободной грамматике правила, в форме Бэкуса-Наура (БНФ), имеют вид:
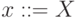
(используется также обозначение  ), где
), где  — нетерминальный символ грамматики, а
— нетерминальный символ грамматики, а 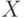 — последовательность терминальных и нетерминальных символов.
— последовательность терминальных и нетерминальных символов.
Язык состоит из фраз — последовательностей терминальных символов. Фраза (или слово, предложение, цепочка символов) принадлежит языку, если она может быть выведена с помощью применения правил грамматики из ее начального символа конечное число раз. Применение правила  преобразует слово
преобразует слово  в слово
в слово 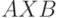 .
.
Результатом анализа, или разбора строки является дерево разбора, листьями которого являются терминальные символы грамматики, а остальными вершинами — нетерминальные символы.
11.1. Анализ английских предложений
Рассмотрим английские предложения вида [4]:
Every man that lives loves a woman. John likes Mary.
Грамматику таких предложений можно описать следующим образом:
- предложение состоит из группы существительного и группы глагола;
- группа существительного состоит из собственного имени или спецификатора, нарицательного имени и придаточного предложения;
- придаточное предложение состоит из указательного местоимения и глагольной группы;
- глагольная группа состоит из непереходного глагола или переходного глагола и группы существительного.
Грамматика в БНФ имеет вид:
sent ::= np vp np ::= spec1 noun relcOpt | np1 np1 ::= pnoun | spec2 noun relcOpt vp ::= verb1 | verb2 np1 relcOpt ::= relprn vp | none noun ::= [man] | [woman] | [cat] | [dog] pnoun ::= [John] | [Mary] verb1 ::= [lives] | [sings] | [runs] verb2 ::= [loves] | [likes] spec1 ::= [every] spec2 ::= [a] relprn ::= [that]
Множество нетерминальных символов образуют символы из левых частей правил. Терминальные символы заключены в квадратные скобки. Начальным символом грамматики является символ sent.
Дерево разбора предложения "every man that lives loves a woman" в соответствии с данной грамматикой приведено на рис. 11.1.

В следующей программе строится дерево разбора предложений, удовлетворяющих грамматике. Дерево разбора представляется в виде терма. Домен таких термов определяется рекурсивно (см. программу).
Первым аргументом предиката parser/4 является нетерминальный символ грамматики. Каждое правило, описывающее этот предикат, соответствует правилу грамматики, указанному в комментарии. На вход предиката также поступает список токенов. Предикат возвращает терм фрагмента дерева разбора и остаток списка токенов.
Правила грамматики, в правых частях которых отсутствуют нетерминальные символы, реализуются в виде фактов.
open core, console, string
class predicates % разбиение на токены
scan: (string) -> string*.
clauses
scan(Str) = [Tok | scan(RestStr)]:-
frontToken(Str, Tok, RestStr),
!.
scan(_) = [].
domains % парсер
term = sent(term Np, term Vp); np(string, string, term Relc);
pn(string); vp(string, term Np); relc(string, term Vp); empty.
nt = sent; np; np1; vp; relc.
class predicates
parser: (nt, string*, term [out], string* [out]).
clauses
% sent ::= np vp
parser(sent, L, sent(Np, Vp), Rest):-
parser(np, L, Np, L1),
parser(vp, L1, Vp, Rest),
!.
% np ::= spec1 noun relcOpt
parser(np, [Spec, Noun | L], np(Spec, Noun, Relc), Rest):-
spec1(Spec),
noun(Noun),
!,
parser(relc, L, Relc, Rest).
% np ::= np1
parser(np, L, Np, Rest):- !,
parser(np1, L, Np, Rest).
% np1 ::= pnoun
parser(np1, [Name | L], pn(Name1), L):-
pnoun(Name1),
Name = toLowerCase(Name1),
!.
% np1 ::= spec2 noun relcOpt
parser(np1, [Spec, Noun | L], np(Spec, Noun, Relc), Rest):-
spec2(Spec),
noun(Noun),
!,
parser(relc, L, Relc, Rest).
% vp ::= verb1
parser(vp, [Verb | L], vp(Verb, empty), L):-
verb1(Verb),
!.
% vp ::= verb2 np1
parser(vp, [Verb | L], vp(Verb, Np), Rest):-
verb2(Verb),
!,
parser(np1, L, Np, Rest).
% relcOpt ::= relprn vp
parser(relc, [Rel | L], relc(Rel, Vp), Rest):-
relprn(Rel),
!,
parser(vp, L, Vp, Rest).
% relcOpt ::= none
parser(_, L, empty, L).
class facts
noun: (string).
pnoun: (string).
verb1: (string).
verb2: (string).
spec1: (string).
spec2: (string).
relprn: (string).
clauses
noun("man").
noun("woman").
noun("cat").
noun("dog").
pnoun("John").
pnoun("Mary").
spec1("every").
spec2("a").
verb1("lives").
verb1("sings").
verb1("runs").
verb2("loves").
verb2("likes").
relprn("that").
class predicates % печать дерева разбора
print: (term).
print: (term, charCount).
f: (charCount, string).
clauses
f(N, S):-
write(string::create(N, "\t"), S), nl.
print(Term):-
print(Term, 0).
print(sent(Np, Vp), N):-
f(N, "sent"),
print(Np, N + 1),
print(Vp, N + 1).
print(np(Spec, Noun, Relc), N):-
f(N, "np"),
f(N + 1, "spec"), f(N + 2, Spec),
f(N + 1, "noun"), f(N + 2, Noun),
print(Relc, N + 1).
print(pn(Name), N):-
f(N, "np"), f(N + 1, Name).
print(relc(Rel, Vp), N):-
f(N, "relc"),
f(N + 1, "relprn"), f(N + 2, Rel),
print(Vp, N + 1).
print(vp(Verb, Np), N):-
f(N, "vp"),
f(N + 1, "verb"), f(N + 2, Verb),
print(Np, N + 1).
print(empty, _).
run():-
Str = "Every man that lives loves a woman.",
write(Str), nl,
L = scan(toLowerCase(Str)),
parser(sent, L, Term, Rest),
write(Rest), nl,
write(Term), nl, nl,
print(Term),
_ = readLine().
Пример
11.1.
Разбор английских предложений
Предикат toLowerCase переводит все символы строки в нижний регистр.
Упражнение 1. Добавьте в предложения существительные множественного числа. Постройте грамматику и напишите парсер таких предложений.