Машинный интерфейс, независимый от технологии
Итак, после того, как к большинству компьютерных систем были добавлены уровни абстракции, их архитектура стала многоуровневой. Главные уровни AS/400 — это архитектура независимого от технологии машинного интерфейса MI (Technology Independent Machine Interface) и архитектура RISC-процессора PowerPC.
Определение архитектуры PowerPC было дано с очевидным уклоном в сторону аппаратуры. Конструкторы микросхем играют важную роль в создании любой процессорной архитектуры — ведь именно они держат в голове массу вариантов ее реализации. Дабы не выйти за пределы возможностей конкретной аппаратуры конкретного кристалла, соблюсти время процессорного цикла, от одних функций им приходится отказываться, другие — определять заново. Это единственно верный подход — ведь в нереализуемой аппаратной архитектуре смысла мало. В то же время архитектура, учитывающая только требования аппаратуры, недолговечна.
Правда, есть и опирающиеся на аппаратуру архитектурыдолгожители. Например, Intel успешно довела свой процессор x86 с начала 80х до сего дня. Начав с Intel 8086, эта компания продолжает наращивать его функциональные возможности, по мере того как технология позволяет упаковать все больше транзисторов в один кристалл. Семейство процессоров 186, 286, 386, 486, Pentium, Pentium II и Pentium Pro — грандиозный успех Intel.
Для поддержания программной совместимости к оригинальной 16разрядной архитектуре были добавлены 32-разрядные расширения. С этой же целью новые (1997 год) команды расширений мультимедиа (MMX) используют существующие регистры с плавающей запятой, а не добавляют новые. С целью повысить конкурентоспособность и производительность Intel добавила в процессоры Pentium Pro и Pentium II набор микрокоманд RISC. Каждая CISC-команда x86 реализована в этих процессорах как последовательность RISC-команд. Благодаря использованию RISC-технологии архитектура x86 продолжает жить.
Обзор архитектуры MI
Определение архитектуры MI не привязано к аппаратуре. Это не физический, а логический интерфейс системы. Как уже говорилось в "Расширенная архитектура приложений" , архитектура MI предлагает полный набор API для OS/400 и всех приложений. Этот набор полон по определению; то есть ни система, ни приложения в принципе не могут выйти за пределы MI. Единственный способ связи с аппаратурой и некоторым системным ПО ниже MI — через сам MI. Это свойство отличает архитектуру MI от APIцентрической архитектуры, где приложения могут обходить API и, следовательно, становиться зависимыми от нижележащих аппаратуры и ПО.
Когда создавалась архитектура MI, термин API еще не был четко определен, так что разработчики называли эти модификации просто командами. Чтобы показать, что интерфейс архитектуры поддерживает как прикладное, так и системное ПО, они выбрали название машинный интерфейс. Так что можно считать, что "I" в аббревиатуре "API" — то же, что и в "MI". API — не что иное, как команды MI.
Вы поражены прозорливостью разработчиков первоначальной архитектуры MI, раз и навсегда определивших набор API, используемый OS/400 и всеми приложениями? Не стоит: они не сделали этого, да и не могли сделать. По мере появления новых приложений в архитектуру MI добавлялись поддерживающие их новые API. Дело в том, что архитектура MI безразмерна, и новые API для поддержки новых приложений или функций операционной системы к ней можно добавлять в любое время. А раз эта архитектура постоянно изменяется, приобретая новые функции, то значит, она никогда не устареет. Так как все предыдущие API остаются при этом нетронутыми, для всех ранее написанных приложений сохраняется защита в границах MI.
Архитектура MI состоит из двух компонентов: набора команд и операндов, над которыми эти команды выполняются. Часть операндов — из битов и байтов — не отличается от тех, что используются в обычных компьютерных архитектурах. Другие представляют собой объекты. Объект — это сложная структура данных, единственная, поддерживаемая в рамках MI.
Компьютер обычно представляет свои информационные ресурсы — каталоги, файлы баз данных и описания физических устройств — в виде структур данных или хранящихся в памяти блоков с заранее определенными полями. Приложения и системное ПО, обладая непосредственным доступом к этим структурам данных, манипулируют их полями. А следовательно, они должны "знать", как это делать.
Объект в границах MI — это контейнер, содержащий структуру данных, соответствующую информационному ресурсу. Определенный уровень независимости достигается следующим образом: прикладные и системные программы вместо того, чтобы работать непосредственно со структурой данных через инструкции на уровне битов и байтов, имеют дело лишь с инструкциями, рассматривающими объекты в целом.
Благодаря использованию объектов, прикладному и системному ПО больше не требуется информация о структуре или формате данных. Эта информация хранится в контейнере и невидима за пределами объекта. Поэтому любые изменения в структуре данных не влияют на прикладные или системные программы, и они остаются независимыми от структур нижнего уровня. Такое свойство сокрытия внутренних деталей называется инкапсуляцией. Мы обсудим инкапсуляцию, а также внутреннюю структуру объекта и команды для работы с ними в "Объекты" , а теперь сосредоточимся на наборе команд архитектуры MI.
Давайте обсудим несколько примеров команд, выполняемых над обычными данными и команд, оперирующих объектами. Поговорим и о том, как компиляторы используют MI для генерации кода, выполняемого аппаратурой, познакомимся с характеристиками MI и программами MI. И наконец, рассмотрим структуру команд MI.
Неисполняемый интерфейс
Команды MI не исполняются аппаратурой непосредственно. Они либо предварительно (до исполнения программы) транслируются в аппаратный набор команд, либо специальный компонент SLIC интерпретирует некоторые команды MI одну за другой. Пример интерпретируемых команд MI — API Advanced 36. Мы называем процесс преобразования команд MI в низкоуровневые аппаратные команды трансляцией, а не компиляцией, так как при этом выполняется лишь часть функций компиляции. Прежде результатом такой трансляции был набор инструкций IMPI — теперь это набор инструкций PowerPC.
Набор инструкций MI нельзя считать ЯВУ в обычном смысле. Правильнее рассматривать его как разновидность промежуточного представления программы в современном компиляторе ЯВУ. Кое-кто предпочитает представлять набор инструкций MI как ЯВУ, требующий трансляции на более низкий уровень или исполнения посредством интерпретации. Краткое описание оптимизирующих компиляторов поможет понять, почему MI лучше рассматривать как промежуточное звено.
Структура современного оптимизирующего компилятора показана на рис. 4.1. Обычно, компилятор состоит из двух и более проходов или фаз. Проход — это одна фаза, за которую компилятор считывает и модифицирует всю программу. Термины фаза и проход часто используются как синонимы.
В процессе выполнения каждого прохода компилятор преобразуя программу, понижает уровень ее представления (от более абстрактного к менее). В конечном итоге получается набор команд аппаратуры. Такая структура оптимизирующего компилятора была впервые предложена в 60х годах для упрощения сложных преобразований, имевших целью получение оптимизированного кода.
Возможности однопроходного компилятора по оптимизации ограничены. Проще говоря, он не может просмотреть код программы вперед и учесть то, что произойдет дальше. "Заглянуть вперед" может многопроходный компилятор. Назначение регистров переменным в зависимости от их связей с другими переменными, запись в память ненужного более содержимого кэша, предварительная выборка операндов — вот лишь некоторые примеры оптимизации, выполняемой многопроходным компилятором.
Оптимизации, произведенные компилятором, могут значительно ускорить выполнение программы, особенно если она работает на процессоре, способном выполнять несколько команд параллельно. RISC-процессор — именно такого типа и ему необходим оптимизирующий компилятор для достижения высокой производительности. Применение нескольких проходов также облегчает процесс написания самого компилятора.
Первый проход компилятора, показанного на рис. 4.1, часто называют препроцессором (front end) компилятора. Его задача — преобразование текста на ЯВУ в общую промежуточную форму (common intermediate form).
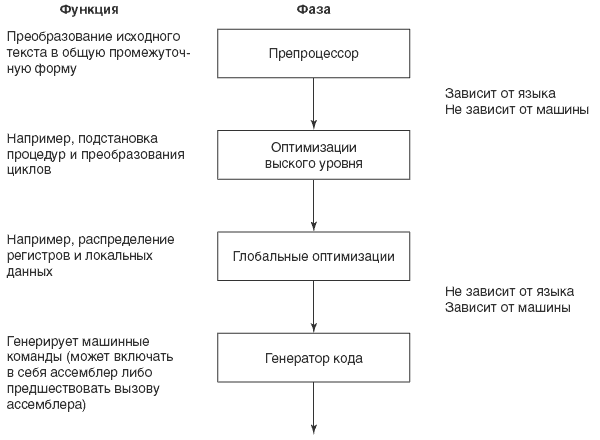
Постпроцессор (back end) компилятора состоит из фаз оптимизации и фазы генерации кода. Препроцессоры зависят от ЯВУ, тогда как постпроцессоры — от аппаратуры. Если общая промежуточная форма независима как от ЯВУ, так и от аппаратуры, то она может использоваться несколькими компиляторами. Для каждого нового ЯВУ нужен лишь новый препроцессор. Аналогично, если создан постпроцессор для новой аппаратуры, то с ним будут работать все старые препроцессоры. Такой модульный подход упрощает создание компиляторов ЯВУ для нового компьютера.
Набор команд MI аналогичен общей промежуточной форме, применяемой в компиляторах. Компилятор ЯВУ преобразует исходный текст в форму для MI. Транслятор, расположенный уровнем ниже MI, считывает программу в этой форме, выполняет оптимизацию и генерирует инструкции IMPI или PowerPC. Транслятор очень напоминает постпроцессор компилятора.
Общая промежуточная форма для некоторых языков может как транслироваться, так и интерпретироваться. В "Версия 4" мы рассмотрим язык Java, использующий как раз такую форму. Промежуточная форма Java, известная как байткод, также включена в MI.
Набор инструкций MI заменяет общую промежуточную форму не во всех компиляторах AS/400 — некоторые языки имеют собственную промежуточную форму. Ниже приводится описание внутренней структуры компиляторов языков для AS/400, и место MI в этой структуре.