

|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Опубликован: 30.07.2013 | Доступ: свободный | Студентов: 1904 / 163 | Длительность: 24:05:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Лекция 6:
Протокол розыска соседей
Мы же предположим, что у эталонного хоста IPv6 в каждый момент времени есть один выходной интерфейс по умолчанию, который и используется для передачи пакетов.
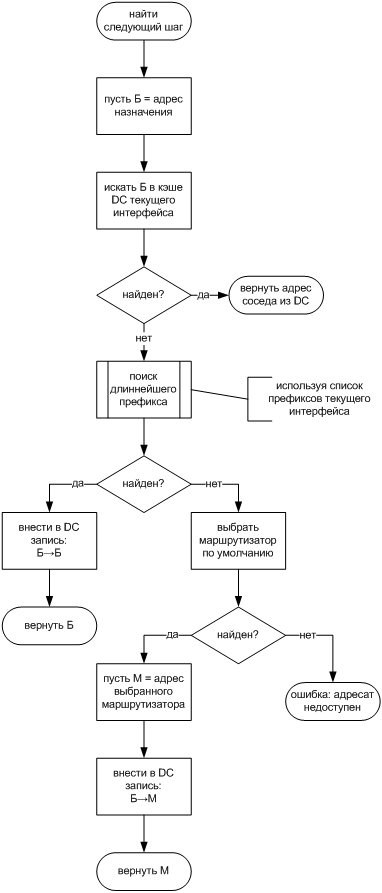
Теперь нам пора свести воедино наши соображения о том, каков принципиальный алгоритм передачи пакета эталонным хостом IPv6 [§5.2 RFC 4861]. Вызов этого алгоритма будет происходить на каждый исходящий пакет. Входными данными алгоритма послужат сетевой адрес назначения пакета и требуемый выходной интерфейс, а вернуть он должен канальный адрес следующего шага, или же ошибку, если следующий шаг найти не удалось.
Первое решение хоста состоит в том, является ли адрес назначения индивидуальным или групповым. Определить это просто благодаря тому, что все групповые адреса имеют префикс FF00::/8. Дальнейшая работа над групповым адресом для нас сейчас интереса не представляет, так как, согласно нашему плану, групповые адреса IPv6 всегда "на канале", а канальный групповой адрес просто вычисляется из сетевого группового адреса по правилам инкапсуляции IPv6 для каналов данного типа. Например, в Ethernet это уже знакомая нам элементарная операция: взять 32 младших бита группового адреса IPv6 и присоединить к ним префикс 33 33. Поэтому сосредоточим наше внимание на индивидуальных адресах назначения.
Далее хосту надо найти сетевой адрес следующего шага. Здесь хост пытается сэкономить время, применяя кэш адресатов DC, привязанный к выходному интерфейсу. Если адрес назначения уже содержится в левой части записи DC, то правая часть этой записи сразу же отвечает на два вопроса: явным образом она сообщает сетевой адрес следующего шага, а неявно говорит, "на канале" ли адресат. Впрочем, хосту уже неважен ответ на второй вопрос, потому что он знает ответ на первый.
Если же записи об адресе назначения в кэше DC нет, хост должен определить, "на канале" ли адресат. Здесь безопаснее ошибочный диагноз: "Вне канала", — потому что в этом случае пакет уйдет через маршрутизатор. Напротив, ошибочный диагноз: "На канале", — приведет к невозможности передать пакет. Поэтому хост сопоставляет адрес назначения со списком префиксов выходного интерфейса и делает вывод: "На канале", — только если адрес назначения содержит хотя бы один из этих префиксов. В противном же случае хост обязан действовать так, как если бы адресат был "вне канала".
Действующий стандарт ND предписывает поиск длиннейшего префикса [§5.2 RFC 4861], хотя эта информация здесь явно избыточна. Ведь даже если список префиксов содержит более короткий префикс наряду с содержащим его префиксом большей длины, результат проверки не зависит от того, какой именно префикс был обнаружен в адресе назначения. Допустим, например, что список префиксов состоит всего из двух пунктов: 2001:DB8::/48 и 2001:DB8::/64. Тогда адрес 2001:DB8::1234 будет "на канале" вне зависимости от того, какой из префиксов "сработал" при проверке. Информация о длиннейшем префиксе могла бы понадобиться, если бы надо было распространить поиск на несколько сетевых интерфейсов и выбрать интерфейс с самым точным префиксом. Однако выбор выходного сетевого интерфейса сознательно не включен в современную версию ND. По-видимому, поиск длиннейшего префикса в стандарте ND остался с тех пор, когда поддержка нескольких интерфейсов на уровне ND была предметом исследования. Кроме того, поиск самого точного префикса может быть нужен, если хост ведет статистику для каждого префикса на канале: счетчик числа обращений и т.п.
Если по итогам этой проверки адрес назначения находится "на канале", то сетевой адрес следующего шага совпадает с адресом назначения. В противном случае хост выбирает кандидата из списка маршрутизаторов по умолчанию, например, руководствуясь сведениями NUD. Окончательный результат помещается в кэш DC.
Если сведений NUD ни об одном маршрутизаторе нет, то достаточно перебирать список маршрутизаторов по кругу [§6.3.6 RFC 4861]. Тогда довольно скоро в кэше NC появится актуальная информация о доступности хотя бы некоторых маршрутизаторов.
В этом и состоит первая часть эталонного алгоритма передачи пакета хостом IPv6: выбор следующего шага (маршрутизация). Давайте представим его в виде блок-схемы рис. 5.22.
Теперь сетевой адрес следующего шага выбран, и слово за модулем ND, чьей задачей будет выяснить отвечающий ему канальный адрес. Процесс ND тоже старается сэкономить время и силы, на этот раз с помощью кэша соседей NC при выходном интерфейсе. Если данный адрес уже закэширован и запись о нем полная, то есть содержит канальный адрес, то достаточно вернуть последний. Конечно, сам факт обращения к записи NC может включить фоновый механизм ее освежения согласно NUD, например, если запись ПРОСРОЧЕННАЯ. Тем временем алгоритм передачи IPv6 успешно завершает работу, так как любой полной записью NC можно немедленно пользоваться для передачи пакета.
И, наконец, если полной записи о следующем шаге в кэше NC еще нет, то хосту остается только поместить пакет в буфер и начать процедуру розыска соседа. В результате ее работы возникнет полная запись NC, если искомый узел доступен, конечно. Так задача сведется к предыдущей, когда запись NC уже есть.
Какими любопытными свойствами обладает этот алгоритм? С одной стороны, он вполне способен распределить нагрузку на несколько маршрутизаторов [RFC 4311], но при этом он не страдает от недостатков случайного распределения, потому что кэширует следующий шаг для каждого адресата.
Проблемы, которые влечет за собой бессистемное распределение пакетов по разным путям, мы уже упомянули в §5.1.
С другой стороны, этот алгоритм не обременен мгновенной проверкой доступности следующего шага. Допустим, хост до некоторых пор пользовался одним маршрутизатором, а затем его маршрутизатор-фаворит неожиданно взяли и выключили. Тогда алгоритм передачи хоста продолжит возвращать канальный адрес выключенного маршрутизатора до тех пор, пока фоновый механизм NUD не сигнализирует о его недоступности и пока не исчезнут указывающие на него записи кэша DC. И только после этого произойдет полное переключение на новый маршрутизатор.
Конечно, это компромисс между надежностью и производительностью: маршрутизаторы не исчезают ежесекундно, тогда как проверять доступность маршрутизатора перед каждым пакетом было бы накладно. К тому же, благодаря непрерывной обратной связи с вышестоящими протоколами, механизм NUD может установить свои тайм-ауты весьма короткими и обнаружить пропажу соседа в считанные секунды после того, как прекратятся сигналы вышестоящих протоколов о его доступности.
Дальнейшая оптимизация состоит в том, чтобы удалить все записи кэша DC, которые ссылаются на пропавшего соседа, как только механизм NUD обнаружил его недоступность. Это вызовет пересмотр следующего шага для всех активных адресатов, ранее доступных через пропавшего соседа.
Кроме того, если пропавший сосед — маршрутизатор по умолчанию, то надо на какое-то время исключить его из кандидатов для алгоритма передачи. Например, при циклическом обходе списка маршрутизаторов достаточно перейти к следующему элементу в нем. Тогда пропавший маршрутизатор окажется в конце списка и хост выберет его в последнюю очередь; у бедняги будет время на то, чтобы прийти в себя.
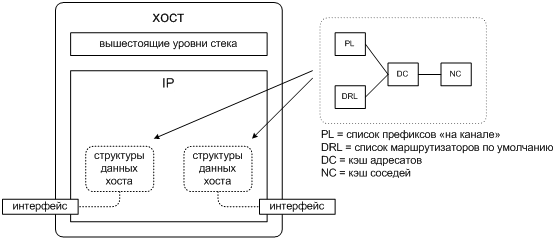
Как мы видим, структуры данных эталонного хоста IPv6 не только привязаны к определенному сетевому интерфейсу, но и логически связаны между собой , как это схематически показано на рис. 5.23.
Прямая связь заключается в следующем:
- хост использует список маршрутизаторов по умолчанию и список префиксов "на канале", чтобы выбрать следующий шаг пакета, и сохраняет свой выбор как запись в кэше DC;
- запись в кэше DC указывает на сетевой адрес следующего шага для данного адреса назначения;
- затем хост проводит розыск соседа для адреса следующего шага и сохраняет результат в кэше NC;
- в результате хост получает возможность передать пакет по определенному канальному адресу.
Обратная связь не менее важна и сводится вот к чему:
- механизм NUD в фоне следит за состоянием соседей, записи о которых есть в кэше NC хоста;
-
если NUD обнаруживает, что сосед стал недоступен, то это повод удалить из кэша DC все записи, ссылающиеся на него как на следующий шаг;
Это позволит хосту адаптироваться как к сбою маршрутизатора, так и к изменению топологии канала, когда бывший сосед становится доступен только через маршрутизатор.
- кроме того, если сосед — маршрутизатор по умолчанию, хосту следует принять его сбой во внимание при выборе следующего шага для адресатов "вне канала".
Как именно хост примет во внимание недоступность маршрутизатора, зависит от его алгоритма управления списком маршрутизаторов по умолчанию. Принципиальный алгоритм [§6.3.6 RFC 4861] рекомендует только, чтобы, во-первых, заведомо или вероятно доступные маршрутизаторы получали приоритет и, во-вторых, в отсутствие заведомо или вероятно доступных маршрутизаторов список перебирался по кругу. Смысл этого алгоритма в том, чтобы не выбрать снова сбойный маршрутизатор до тех пор, пока хост не попытает счастья со всеми остальными пунктами списка.
Сведения о доступности маршрутизаторов поставляет механизм NUD, и может так оказаться, что в данный момент полной записи NC ни об одном из них нет. Это вовсе не значит, что все маршрутизаторы недоступны, — просто стали недоступны те из них, которыми хост до сих пор пользовался. Это повод проверить на работоспособность остальные маршрутизаторы в списке. Отсюда и возникает перебор списка по кругу.
Подведем итоги. В §5.1 мы "сконструировали" механизм розыска соседей, однако еще не сформулировали правил, когда именно узел IPv6 вправе считать удаленный адрес соседским и поводить его розыск. А розыск соседа, который соседом не является — это все равно, что охота на несуществующую черную кошку в темной комнате. Поэтому сейчас нам пришлось целенаправленно поработать над этим вопросом. В процессе мы пересмотрели простую модель канала и подсети, принятую в IPv4, и признали ее слишком ограниченной и не отвечающей требованиям современных канальных технологий. Взамен мы сформулировали для IPv6 принципиально иную модель, в которой маршрутизаторы координируют передачу данных хостами по каналу и за его пределы, а хосты, в свою очередь, обращаются к маршрутизаторам за сведениями о топологии канала, а не пытаются самостоятельно вычислить ее. Затем мы "создали" довольно простой протокол в рамках ND, который обеспечивает работу канала IPv6 согласно этой модели.
Исторической справедливости ради заметим, что хост IPv4 тоже мог следовать подобной линии поведения, когда у него не было полноценной таблицы маршрутов, а вместо нее были список маршрутизаторов по умолчанию и кэш маршрутов, уточняемый переадресовками [§3.3.1.2 RFC 1122]. Тем не менее, критерий соседства IPv4 был задан вполне однозначно и отвечал модели, когда все адреса в подсети, и только они, принадлежат соседями [§3.3.1.1 RFC 1122].
Как вы думаете, насколько оригинальна наша модель? Конечно же, ничто не ново под луной, и на ту же самую модель давно опирается стек протоколов ISO. В частности, взаимодействие хостов (конечных систем, ES) и маршрутизаторов (транзитных систем, IS) в нем обеспечивает протокол ES IS [ISO 9542; предыдущая версия доступна как RFC 995].
Подход ES IS к решению данной задачи можно даже признать более изящным и логически завершенным. Он не сводится к одним только переадресовкам, а включает в себя периодические объявления, которыми ES и IS извещают друг друга о своем существовании. Поэтому некое подобие розыска соседей в ES IS необходимо, только когда на канале нет ни одной IS. Даже в этом случае ES-источник не тратит время на предварительный розыск соседа, а просто шлет пакет с данными по групповому канальному адресу "все ES". ES-адресат, если он действительно подключен к каналу, принимает пакет в обработку и заодно высылает ES-источнику объявление, содержащее его индивидуальный канальный адрес. Тогда ES-источник кэширует канальный адрес соседа, и последующие пакеты уже идут по нему, а не группе "все ES".
Таким образом, ES по умолчанию полагает, что все адреса "на канале". В противоположность этому, хост IPv6 обязан по умолчанию считать, что "вне канала" находятся все адреса, кроме внутриканальных. Когда нет ни маршрутизатора, ни ручной настройки списка префиксов, хосты IPv6 могут обмениваться индивидуальными пакетами, только используя внутриканальные адреса, так как в этих условиях все остальные индивидуальные адреса находятся "вне канала" и потому недоступны.
Любопытно, что ранние стандарты IPv6 следовали модели ES IS, в которой все адреса по умолчанию были "на канале", однако впоследствии от нее полностью отказались [RFC 5942], потому что за ее внешней простотой скрываются различные осложнения [RFC 4943].
Для общего знакомства со стеком протоколов ISO и, в частности, с протоколом ES IS мы настоятельно рекомендуем замечательную книгу Ради Перлман22 Radia Perlman. Mythology and Folklore of Network Protocol Design. http://www.isoc-au.org.au/Events/PerlmanNov05.pdf .
В завершение рассмотрим любопытный пример того, как отличается практика управления подсетями в IPv4 и IPv6. Как мы помним, в IPv4 была вполне допустима конфигурация сети, когда из подсети был "вырезан" префикс большей длины и назначен другому каналу. Скажем, префикс 192.0.2.0/24 назначен каналу К1, а 192.0.2.96/27 — каналу К2, как это показано на рис. 5.24.
Маршрутизаторы М1 и М2 естественно работали с такой конфигурацией, потому что префикс канала К2 был точнее, чем префикс канала К1, и диапазон адресов 192.0.2.96–192.0.2.127 однозначно маршрутизировался в направлении канала К2, тогда как остальные адреса вида 192.0.2.X оставались на канале К1. Тем не менее, хосты канала К1 не могли передавать пакеты хостам канала К2, потому что они разыскивали их на канале К1, вместо того чтобы обратиться к маршрутизатору М1. Обычным решением этой проблемы было или включить ARP proxy на маршрутизаторе М1, или распространить точный маршрут на 192.0.2.96/27 через М1 по всем хостам канала К1, вручную или протоколом маршрутизации.
Как бы мы стали решать ту же проблему в IPv6? Допустим, каналу К1 назначена подсеть 2001:DB8:1:2::/64, а каналу К2 — 2001:DB8:1:2:3:4::/96, как показано на рис. 5.25. Прежде всего, мы не можем не заметить, что длина префикса подсети, отличная от 64, нарушает адресную политику IPv6 из §2.6, хотя и не вступает в противоречие с базовым протоколом, так что назначение такого префикса остается на совести администратора сети.
Что же касается технического решения, то здесь мы видим, как минимум, три альтернативных подхода на основе стандартных механизмов IPv6:
- Во-первых, можно оставить списки префиксов хостов канала К1 пустыми, не считая внутриканального префикса, и тогда хосты будут сначала обращаться к маршрутизатору М1, а тот уже при необходимости переадресует их к соседу.
- Во-вторых, вполне допустимо считать весь префикс 2001:DB8:1:2::/64 "на канале" и включить на маршрутизаторе М1 ND proxy для префикса 2001:DB8:1:2:3:4::/96.
- В-третьих, можно составить и распространить по хостам канала К1 сложный список префиксов, который будет эквивалентен 2001:DB8:1:2::/64 за вычетом 2001:DB8:1:2:3:4::/96.
Пусть читатель найдет способ составить такой список префиксов, используя минимально возможное число элементов. (Начните с доказательства того, что минимально необходимое число префиксов в таком списке равно 32. Затем попробуйте доказать, что кратчайшее решение — единственное. По ходу вы поймете, как устроен этот список.)
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |