Введение
Классификация параллельных архитектур
Подробный анализ и обзор современных архитектур параллельных вычислительных систем можно найти в книгах [1.1-1.2]. В этой лекции рассматриваются лишь те особенности архитектур, которые необходимо учитывать при создании параллельных программ. Отметим, что эти особенности в значительной мере определяют инструментарий параллельного программирования. Под инструментарием параллельного программирования понимается набор алгоритмических языков (в том числе и расширения стандартных алгоритмических языков), использующихся для написания параллельных программ, а также специализированные библиотеки функций, адаптированные к архитектуре конкретной параллельной вычислительной системы. Кроме того, к инструментарию параллельного программирования относятся средства отладки и оптимизации быстродействия параллельных программ, а также средства визуализации и представления результатов параллельных вычислений. В настоящее время различные производители системного программного обеспечения предлагают множество разнообразных инструментов, которые могут быть использованы в процессе создания параллельных программ. Поэтому для получения максимального эффекта необходимо хорошо ориентироваться при выборе конкретных инструментов параллельного программирования среди множества существующих.
В настоящее время существуют различные методы классификации архитектур параллельных вычислительных систем. Подробно различные методы классификации архитектур параллельных вычислительных систем изложены в [1.3].
Одна из возможных классификаций архитектур параллельных вычислительных систем состоит в разделении параллельных вычислительных систем по типу памяти (классификация Джонсона). В этом случае в качестве одного из классов можно выделить параллельные вычислительные системы с распределенной памятью (distributed memory) или массивно-параллельные системы (MPP). Обычно такие системы состоят из набора вычислительных узлов - каждый из них содержит один или несколько процессоров, локальную память, прямой доступ к которой невозможен из других узлов, коммуникационный процессор или сетевой адаптер, а также может содержать жесткие диски и устройства ввода/вывода. В массивнопараллельных системах могут быть и специализированные управляющие узлы и узлы ввода/вывода. Узлы в массивно-параллельных системах связаны между собой через коммуникационную среду (высокоскоростная сеть, коммутаторы либо их различные комбинации).
В качестве второго класса можно выделить архитектуры параллельных вычислительных систем с общей памятью (shared memory) или симметричные мультипроцессорные системы (SMP). Такие системы, как правило, состоят из нескольких однородных процессоров и массива общей памяти. Каждый из процессоров имеет прямой доступ к любой ячейке памяти, причем скорость доступа к памяти для всех процессоров одинакова. Обычно процессоры подключаются к памяти с помощью общей шины либо с помощью специальных коммутаторов.
Однако кроме двух вышеперечисленных классов существуют и некоторые их гибриды.
В качестве первого гибридного класса назовем системы с неоднородным доступом к памяти (Non-Uniform Memory Access) - так называемые NUMA-системы. Такие параллельные вычислительные системы обычно состоят из однородных модулей, каждый из которых содержит один или несколько процессоров и локальный для каждого модуля блок памяти. Объединение модулей между собой осуществляется при помощи специальных высокоскоростных коммутаторов (Numalink). В таких вычислительных системах адресное пространство является общим. Прямой доступ к удаленной памяти, т. е. к локальной памяти других модулей, поддерживается аппаратно. Однако время доступа процессора одного модуля к памяти другого модуля заметно больше времени доступа к локальной памяти исходного модуля. Это время может существенно различаться и зависит главным образом от топологии соединения модулей. Очевидно, что этот третий класс является некоторой комбинацией первого и второго классов.
В качестве второго гибридного класса отметим различные комбинации соединения систем трех вышеперечисленных типов. Такие соединения могут иметь весьма сложный иерархический характер. Возможно также соединение кластеров или их отдельных частей через Интернет. Такие вычислительные системы развиваются в рамках международного проекта GRID (см., например, [1.4-1.5]).
Современные направления развития параллельных вычислительных систем
В настоящее время началось широкое использование двуядерных микропроцессоров Pentium D, Xeon, Itanium 2, Opteron и IBM POWER5. В ближайшей перспективе ожидается появление процессоров и с большим количеством ядер. Представители компании Intel уже объявили о предстоящем начале выпуска в ближайшее время 6-ядерных процессоров Clovertown. К 2009 году компания Intel предполагает начать производство 256- ядерных процессоров. Фирма IBM в 2007 году начала выпуск процессора Cell с 9 ядрами, каждое из которых выполняет одновременно по два потока. Кластер, построенный на этих процессорах, был продемонстрирован на выставке CeBIT в марте 2006 года в Ганновере.
Отметим, что все ядра - как некоторых уже выпускаемых процессоров, например Pentium D и IBM POWER5, так и перспективных процессоров Cell - могут выполнять одновременно по два параллельных потока. Таким образом, даже персональный компьютер с одним процессором Pentium D позволяет выполнять одновременно до 4 процессов. То есть обычный персональный компьютер с одним из таких процессоров является параллельной вычислительной системой с общей памятью (SMP-системой). Поэтому освоение эффективного инструментария для программирования на таких системах является очень актуальной и важной задачей подготовки и переподготовки специалистов в области программирования.
В связи с развитием параллельных возможностей современных микропроцессоров в настоящее время можно выделить три основных направления в развитии параллельных вычислительных систем.
Во-первых, это многоядерность (Multicore), когда несколько ядер находятся в корпусе одного процессора.
Во-вторых, это технологии с явным параллелизмом команд (EPIC - Explicitly Parallel Instruction Computing). Архитектура всех современных 64-разрядных процессоров Intel построена на использовании технологии EPIC. Параллелизм сегодня стал главным ресурсом наращивания вычислительной мощности компьютеров. Существенным препятствием к параллельному выполнению программ являются так называемые точки ветвления, в которых решается вопрос, по какому из нескольких возможных путей пойдет выполнение программы после этой точки. Чем более совершенным является механизм предсказания ветвлений, тем лучше может быть распараллелена программа. При наличии избыточных вычислительных ресурсов можно начать выполнять сразу два возможных направления работы программы, не дожидаясь, пока ее основная ветвь дойдет до точки ветвления. После того как программа достигнет точки ветвления, можно уже окончательно выбрать результаты, полученные по одной из возможных ветвей. Сущность EPIC заключается в том, что блок предсказаний ветвлений выносится из аппаратной логики процессора в компилятор. Анализируя программу, компилятор сам определяет параллельные участки и дает процессору явные инструкции по их выполнению - отсюда и следует название архитектуры EPIC. Модернизация компилятора гибче и проще, чем модификация аппаратной части параллельной вычислительной системы. Например, можно установить новую версию компилятора и посмотреть, как это отразится на скорости работы прикладных программ, создаваемых с помощью этого компилятора. При этом следует иметь в виду, что изменить устройство процессора в уже работающей вычислительной системе невозможно. Установленный процессор можно только заменить на новый, подходящий для данной системы процессор, если таковой имеется в наличии. Поэтому архитектура EPIC позволяет более эффективно модифицировать работающие вычислительные системы за счет установки более совершенных версий компилятора.
В-третьих, это многопоточность (TLP - Thread Level Parallelism), когда в каждом ядре процессора выполняется одновременно несколько потоков, конкурирующих между собой.
Главная задача в развитии вышеперечисленных направлений - существенное повышение производительности вычислительных систем. Без развития параллельных технологий решить задачу повышения производительности вычислительных систем в настоящее время не представляется возможным, поскольку современные технологии микроэлектроники подошли к технологическому барьеру, препятствующему дальнейшему существенному увеличению тактовой частоты работы процессора и изготовлению процессоров по технологиям, существенно меньшим 15 нанометров.
Межузловые соединения в параллельных системах
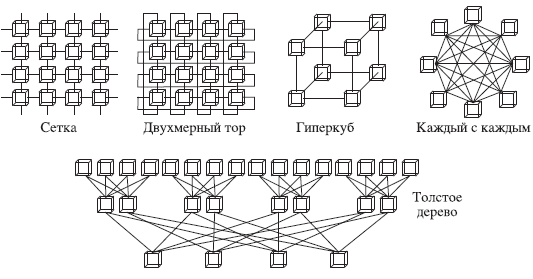
Большую роль в современных высокопроизводительных вычислительных системах играют топологии соединения процессоров и межузловые соединения. На рис. 1.1 представлены некоторые типичные топологии соединения вычислительных узлов в высокопроизводительных вычислительных системах. Отметим, что выбор топологии в соответствии со спецификой решаемых задач зачастую позволяет существенно повысить быстродействие системы при решении конкретного класса задач. Естественно, переход к решению другого класса задач может потребовать изменения топологии соединения узлов системы.
Коммуникационные технологии играют важную роль в быстродействии вычислительных систем. В настоящее время на практике получили распространение следующие типы протоколов межузловых соединений: Ethernet, Myrinet, Infiniband, SCI, Quadrics и Numalink для систем с NUMA-памятью, разрабатываемых фирмой Silicon Graphics. На физическом уровне межузловые соединения организованы с помощью специальных кабелей, коммутаторов и интерфейсных плат, соответствующих конкретному типу межузлового соединения. Интерфейсные платы должны быть установлены в каждый узел кластера. Как правило, протоколу межузлового соединения соответствуют специальные системные библиотеки функций обмена сообщениями, поставляемые в комплекте с кабелями и интерфейсными платами. Для получения максимальной производительности вычислительной системы необходимо использовать именно эти библиотеки в процессе разработки программного обеспечения, поскольку применение иных библиотек может порой привести к весьма значительному снижению производительности вычислительной системы.