
|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 304 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 4: Оптимизация расчетов на примере задачи вычисления справедливой цены опциона Европейского типа
Версия 2. Эквивалентные преобразования: cdfnorm() vs. erf()
Вычисления, которые мы до сих пор выполняли с помощью функции cdfnormf() можно проделать и другим способом, используя функцию erff(). Дело в том, что вычисление cdfnormf является более трудоемким (подумайте, почему это так, рассмотрите интегралы, которые необходимо посчитать).
Используем формулу 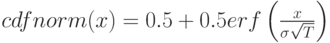
Выполнив необходимые математические преобразования, получим следующий код.
__declspec(noinline) void GetOptionPricesV2(float *pT,
float *pK, float *pS0, float *pC)
{
int i;
float d1, d2, erf1, erf2;
for (i = 0; i < N; i++)
{
d1 = (logf(pS0[i] / pK[i]) + (r + sig * sig * 0.5f) *
pT[i]) / (sig * sqrtf(pT[i]));
d2 = (logf(pS0[i] / pK[i]) + (r - sig * sig * 0.5f) *
pT[i]) / (sig * sqrtf(pT[i]));
erf1 = 0.5f + 0.5f * erff(d1 / sqrtf(2.0f));
erf2 = 0.5f + 0.5f * erff(d2 / sqrtf(2.0f));
pC[i] = pS0[i] * erf1 - pK[i] * expf((-1.0f) * r *
pT[i]) * erf2;
}
}
Добавьте в массив указателей GetOptionPrices, новую функцию.
tGetOptionPrices GetOptionPrices[9] =
{ GetOptionPricesV0, GetOptionPricesV1, GetOptionPricesV2
};
Соберите программу и проведите эксперименты.
На описанной ранее инфраструктуре авторы получили следующие времена.
| N | 60 000 000 | 120 000 000 | 180 000 000 | 240 000 000 |
| Версия V0 | 17,002 | 34,004 | 51,008 | 67,970 |
| Версия V1 | 16,776 | 33,549 | 50,337 | 66,989 |
| Версия V2 | 2,871 | 5,727 | 8,649 | 11,230 |
Как видно из таблицы 9.4, время работы версии 2 почти в 6 раз меньше, чем версии 1. В дальнейших модификациях будем использовать именно функцию erff().
Версия 3. Векторизация: использование ключевого слова restrict
Возможности алгоритмической оптимизации на этом в основном исчерпаны. Перейдем к векторизации расчетного цикла. Прежде всего, необходимо сменить режим компиляции, указав в командной строке ключ –mavx, в противном случае компилятор будет использовать наборы команд SSE, но не AVX.
Проведя эксперименты с собранной версией, можно убедиться, что время работы функции GetOptionPricesV2() не изменится. Чтобы понять, в чем дело, укажем при сборке ключ -vec-report3, "попросив" компилятор выдать отчет о векторизации. Цифра "3" соответствует степени подробности отчета, соответствующей выдаче информации о векторизованных/невекторизованных циклах, а также причинах отсутствия векторизации. Заметим, что в последних версиях компилятора появился новый, шестой тип отчета (-vec-report6), дополнительно дающий некоторые рекомендации относительно векторизации.
Отчет о векторизации приведен ниже ( рис. 9.2). К сожалению, в данном случае он не слишком информативен. Заметим, что при компиляции данного кода при помощи Intel C/C++ Compiler for Windows в отчете можно увидеть фразу о том, что возможны зависимости между массивами. В целом, наш опыт говорит о том, что диагностики компиляторов Intel для C/C++ чаще всего позволяют догадаться, что именно мешает векторизации.
Вернемся к вопросу о том, как "уговорить" компилятор векторизовать цикл.
Объяснить компилятору, что опасности нет, можно разными способами: используя ключевое слово restrict в объявлении формальных параметров функции, с помощью директивы #pragma ivdep, с помощью директивы #pragma simd перед циклом. Кроме перечисленного, можно указать специальную опцию, которая подскажет компилятору, что массивы в программе никогда не пересекаются, но эта опция действует на всю программу целиком и при неаккуратном использовании может "сломать" код.
Рассмотрим сначала первый вариант. Ключевое слово restrict в объявлении указателей говорит о том, что в данную область памяти не будут обращаться при помощи других указателей. Это дает компилятору информацию о том, что массивы pT, pK, pS0 и pC не пересекаются, а, следовательно, запись pC[i] не оказывает никакого влияния на значения в других массивах, то есть можно безопасно менять порядок вычислений, организуя их векторно.
__declspec(noinline) void GetOptionPricesV3(
float * restrict pT, float * restrict pK,
float * restrict pS0, float * restrict pC)
{
int i;
float d1, d2, erf1, erf2;
for (i = 0; i < N; i++)
{
d1 = (logf(pS0[i] / pK[i]) + (r + sig * sig * 0.5f) *
pT[i]) / (sig * sqrtf(pT[i]));
d2 = (logf(pS0[i] / pK[i]) + (r - sig * sig * 0.5f) *
pT[i]) / (sig * sqrtf(pT[i]));
erf1 = 0.5f + 0.5f * erff(d1 / sqrtf(2.0f));
erf2 = 0.5f + 0.5f * erff(d2 / sqrtf(2.0f));
pC[i] = pS0[i] * erf1 - pK[i] * expf((-1.0f) * r *
pT[i]) * erf2;
}
}
Добавьте в массив указателей GetOptionPrices, новую функцию.
tGetOptionPrices GetOptionPrices[9] =
{ GetOptionPricesV0, GetOptionPricesV1, GetOptionPricesV2,
GetOptionPricesV3 };
Для корректной сборки программы, в которой используется ключевое слово restrict, необходимо указать в командной строке одноименную опцию.
icc -O2 –restrict -mavx ...
Соберите программу и проведите эксперименты.
На описанной ранее инфраструктуре авторы получили следующие времена.
| N | 60 000 000 | 120 000 000 | 180 000 000 | 240 000 000 |
| Версия V0 | 17,002 | 34,004 | 51,008 | 67,970 |
| Версия V1 | 16,776 | 33,549 | 50,337 | 66,989 |
| Версия V2 | 2,871 | 5,727 | 8,649 | 11,230 |
| Версия V3 | 0,522 | 1,049 | 1,583 | 2,091 |
Как видно из таблицы 9.5, время работы версии 3 примерно в 5.5 раз меньше, чем версии 2. Процессор, на котором проводились эксперименты, способен с использованием AVX выполнять операции одновременно над 8 элементами типа float. Почему код ускорился в меньшее число раз, чем должен, предлагаем выяснить читателям самостоятельно, собрав профиль работы функции, использую Intel VTune Amplifier XE (обратите внимание на вызовы математических функций и примените закон Амдаля).
Svetlana Svetlana