

|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 306 / 37 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Самостоятельная работа 1: Компиляция и запуск приложений на Intel Xeon Phi
Модели программирования приложений на Intel Xeon Phi
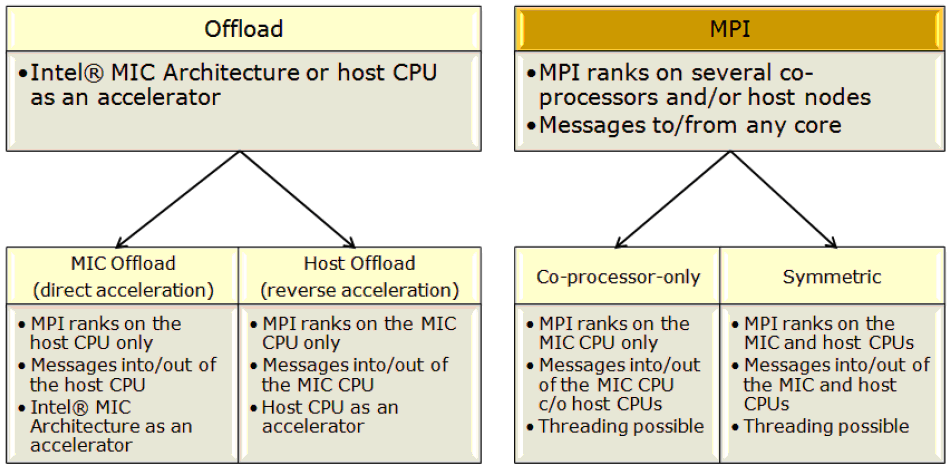
Разработка программ для Intel Xeon Phi предполагает выбор одной из моделей программирования, поддерживаемых посредством библиотеки Intel MPI. Существующие модели приведены на рис. 6.1.
Offload модель предполагает использование Xeon Phi в режиме сопроцессора, т.е. дополнительного вычислительного устройства, доступ к которому осуществляется с помощью специальных команд (директив) из кода, выполняемого на обычном центральном процессоре. Данный режим поддерживается библиотекой Intel MPI, начиная с версии 4.0 update 3, для операционных систем семейства Linux при условии, что в качестве центрального процессора выступает процессор семейства Intel Xeon (или совместимые процессоры сторонних производителей). При выполнении MPI программы в этом режиме, ранги присваиваются только центральным процессорам.
Теоретически возможен и обратный вариант, когда в роли сопроцессора выступает центральный процессор, а основной код работает на Xeon Phi. Однако этот вариант на текущий момент не поддерживается.
Offload модель поддерживается такими продуктами Intel, как компиляторы C/C++ и Fortran, а также Intel Math Kernel Library (MKL).
В режиме MPI как центральный процессор, так и сопроцессор являются отдельными вычислительными узлами и могут взаимодействовать между собой посредством обмена MPI сообщениями. Написание кода для сопроцессора в этом случае ничем не отличается от написания MPI программы для CPU. Внимание нужно уделять разве что балансировке нагрузки и особенностям оптимизации кода под архитектуру Intel MIC.
Обычно рассматриваются три MPI модели:
- Симметричная модель. Вычисления производятся как на процессоре, так и на сопроцессоре, причем с точки зрения MPI программирования они являются отдельными узлами и обладают собственными рангами. Это наиболее общая модель.
- Использование только сопроцессора. Программа исполняется только на сопроцессоре (одном или многих). Каждый сопроцессор обладает собственным MPI рангом. CPU в вычислениях не задействован.
- Использование только процессора. Программа исполняется только на центральных процессорах без использования сопроцессоров. По сути, это обычное исполнение MPI программ. В данной лабораторной работе этот режим рассматриваться не будет.
Режим offload
В данном разделе рассматривается процесс компиляции и запуска программы для Intel Xeon Phi в режиме offload.
Вывод максимального числа потоков сопроцессора
Рассмотрим простую, но полезную задачу: необходимо вывести максимальное число потоков центрального процессора и сопроцессора Xeon Phi.
Для решения задачи будем использовать возможности технологии OpenMP. Создадим файл main.cpp, куда будем писать код. Сначала напишем функцию для вывода на консоль доступного числа потоков, которая работала бы на сопроцессоре. Для этого воспользуемся директивой offload_attribute [6.2]:
#pragma offload_attribute(push, target(mic))
#include <stdio.h>
#include <omp.h>
void testThreadCount()
{
int thread_count;
#pragma omp parallel
{
#pragma omp single
thread_count = omp_get_num_threads();
}
printf("Number of threads: %d\n", thread_count);
}
#pragma offload_attribute(pop)
Первый параметр директивы offload_attribute может принимать значения push либо pop, что соответствует началу и концу блока кода, который предназначен для выполнения как на центральном процессоре, так и на сопроцессоре.
Далее напишем код функции main:
int main()
{
printf("Intel CPU:\n");
testThreadCount();
int number_of_coprocessors =
_Offload_number_of_devices();
printf("Intel Xeon Phi:\n");
printf("Number of coprocessors: %d\n",
number_of_coprocessors);
for (int i = 0; i < number_of_coprocessors; ++i)
{
#pragma offload target(mic:i)
{
testThreadCount();
}
}
return 0;
}
Новой здесь является директива offload. Блок кода, который расположен за ней, будет выполнен на сопроцессоре. Параметр target(mic:<device_id> ) указывает, на каком именно сопроцессоре должен быть выполнен код. Следует отметить, что номера доступных сопроцессоров лежат в диапазоне от 0 до общего количества Intel Xeon Phi, установленных в рамках данного узла.
Заметим также, что запуск кода на сопроцессоре выполняется в синхронном режиме, т.е. при вызове функции управление передается сопроцессору, а выполнение основной программы блокируется, пока сопроцессор не завершит свою работу.
Для организации асинхронных вычислений нужно использовать несколько CPU потоков, в каждом из которых может использоваться либо отдельный сопроцессор, либо выполняться некие вычисления на процессоре.
Обратите внимание на разницу в директивах offload и offload_attribute.
С помощью директивы offload_attribute дается указание компилятору скомпилировать блок кода специальным образом для возможности его выполнения на Xeon Phi. При этом данный код не обязательно будет исполняться на сопроцессоре. Эту директиву нельзя использовать внутри функции. Обычно она обрамляет код функций и объявление глобальных переменных.
Директива offload говорит компилятору, что блок кода, непосредственно следующий за ней, должен быть выполнен на сопроцессоре. И если это не просто вызов функции, то этот блок кода также будет скомпилирован специальным образом.
Теперь скомпилируем написанную программу, используя Intel C/C++ Compiler. Поддержка offload режима добавлена в компиляторы Intel для Linux, начиная с версии 13. Сам процесс компиляции в данном случае ничем не отличается от компиляции кода для центрального процессора:
icc -02 -openmp main.cpp –o lab1_thread_test
В результате будет создан исполняемый файл lab1_thread_test, содержащий в себе как код центрального процессора, так и код сопроцессора.
Для запуска программы необходимо воспользоваться утилитой Hydra Process Manager, входящей в состав Intel MPI:
mpiexec.hydra –perhost 1 ./lab1_thread_test
После выполнения данной команды будет произведен запуск программы c использованием всех доступных узлу сопроцессоров. Результат работы зависит от количества имеющихся сопроцессоров. Для случая одного Intel Xeon Phi вывод программы приведен на рис. 6.2.
В случае если работа ведется на кластере с системой управления SLURM, необходимо предварительно получить один из доступных сопроцессоров для монопольного использования:
salloc –N 1 --gres=mic:1
После этого можно запускать программы на Xeon Phi в течение того промежутка времени, когда вы владеете сопроцессором. Время владения определяется системой управления кластером.
Команда salloc позволяет выделить несколько сопроцессоров путем задания соответствующего значения ключа –N. Ключ --gres=mic:1 говорит о необходимости выделить узел кластера с минимум одним сопроцессором Intel Xeon Phi.
В случае успешного завершения появится сообщение о том, что доступ получен. Дополнительно будет указан номер задачи, посредством которой обеспечивается монопольный доступ к сопроцессорам ( рис. 6.3). Отметим, что в случае отсутствия свободных ресурсов команда salloc будет ожидать их появления, блокируя консоль.
Если сопроцессор более не нужен, освободить его можно командой:
scancel <номер задачи>
Список активных задач выводит команда:
squeue
Svetlana Svetlana