|
Здравствуйие! Я хочу пройти курс Введение в принципы функционирования и применения современных мультиядерных архитектур (на примере Intel Xeon Phi), в презентации самостоятельной работы №1 указаны логин и пароль для доступ на кластер и выполнения самостоятельных работ, но войти по такой паре логин-пароль не получается. Как предполагается выполнение самосоятельных работ в этом курсе? |
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 30.05.2014 | Доступ: свободный | Студентов: 305 / 36 | Длительность: 11:26:00
Специальности: Программист, Системный архитектор
Лекция 5: Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel C/C++ Compiler
Неявная схема работы с памятью в режиме offload
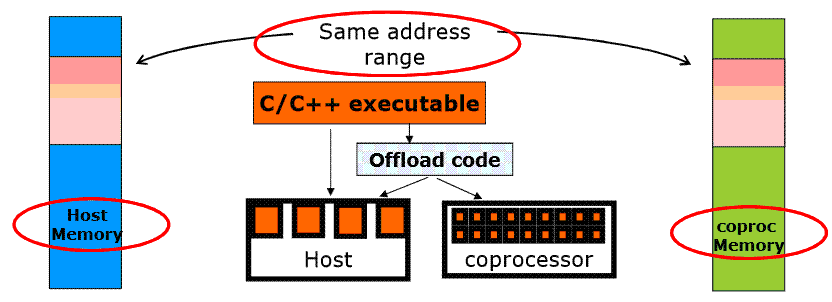
Вторым способом работы с сопроцессором является неявный режим, основанный на использовании ключевых слов – расширений языков C/C++ (не поддерживается языком Fortran). Основная идея неявной схемы состоит в использовании разделяемой между CPU и MIC памяти в рамках единого виртуального адресного пространства ( рис. 5.3).
Основным достоинством неявной схемы является возможность работы со сложными типами данных (возможность побитового копирования необязательна), размещаемыми в разделяемой памяти. При этом все операции по обмену такими данными берет на себя компилятор.
Для выделения участка разделяемой памяти динамически необходимо воспользоваться функциями:
- void *_Offload_shared_malloc(size_t size) ;
- void *_Offload_shared_aligned_malloc(size_t size, size_t alignment) ;
Удаление памяти выполняется соответственно с помощью функций:
- void _Offload_shared_free(void *p) ;
- void _Offload_shared_aligned_free(void *p) ;
Синхронизация данных в разделяемой памяти происходит в двух местах: в начале и в конце offload секции кода. Реально передаются только модифицированные данные. Если структура (или класс) в качестве одного из своих полей содержит указатель на данные в разделяемой памяти, что эти данные также будут синхронизированы автоматически.
Код сопроцессора может содержать стандартные методы синхронизации доступа к разделяемой памяти, такие как мьютексы, семафоры, критические секции и т.п.
Заметим, что неявная схема является частью расширения Intel Cilk Plus.
Ключевое слово _Cilk_shared используется для размещения переменных и функций в разделяемой памяти. Примеры его использования приведены в таблице 5.4.
| Что | Синтаксис | Семантика |
|---|---|---|
| Функции |
int _Cilk_shared f(int x)
{ return x + 1; } |
Компиляция для CPU и MIC, функция может быть вызвана на любой стороне |
| Глобальные переменные |
_Cilk_shared int x = 0; |
Переменная доступна на обеих сторонах |
| Статические переменные |
static _Cilk_shared int x; |
Переменная доступна на обеих сторонах, видна только в рамках файла/функции |
| Классы |
class _Cilk_shared x {…}; |
Поля, методы и операторы класса доступны на обеих сторонах |
| Указатели на разделяемые данные |
int _Cilk_shared *p; |
Локальный указатель на разделяемые данные |
| Разделяемые указатели |
int* _Cilk_shared p; |
Разделяемый указатель, должен указывать на разделяемые данные |
| Блоки кода |
#pragma offload_attribute(push, target(mic)) … #pragma offload_attribute(pop) |
Аналог _Cilk_shared для целого блока кода |
Выполнение кода на сопроцессоре обеспечивается ключевым словом _Cilk_offload (таблица 5.5).
| Что | Синтаксис | Семантика |
|---|---|---|
| Вызов функции на сопроцессоре |
x = _Cilk_offload func(y); |
Функция выполняется на сопроцессоре, если это возможно |
x = _Cilk_offload_to(card_num) func(y); |
Функция должна выполниться на указанном сопроцессоре | |
| Асинхронный вызов на сопроцессоре |
x = _Cilk_spawn _Cilk_offload func(y); |
Неблокирующее выполнение на сопроцессоре |
| Параллельный цикл for на сопроцессоре |
_Cilk_offload _Cilk_for(i=0; i<N; ++i)
{ a[i] = b[i] + c[i]; } |
Цикл выполняется параллельно на сопроцессоре |
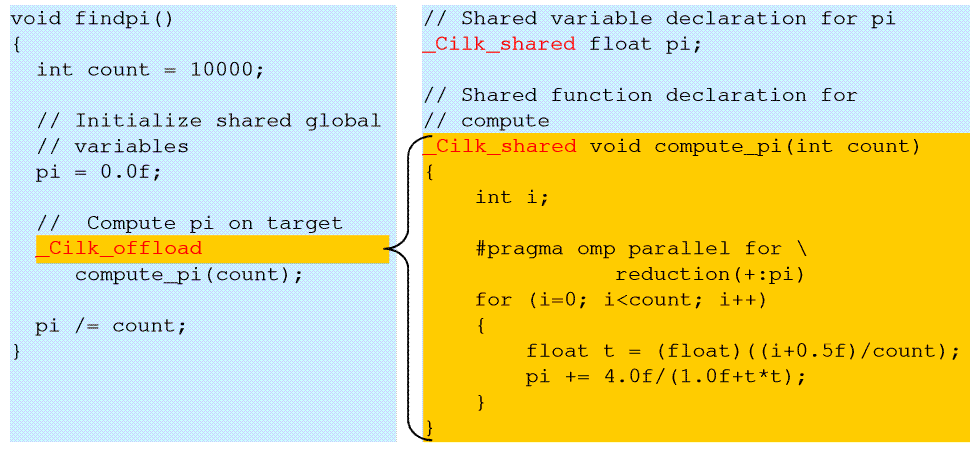
Использование неявной схемы продемонстрируем на примере функции для вычисления числа Пи ( рис. 5.4).
В данном примере используется глобальная переменная pi, размещаемая в разделяемой памяти CPU и сопроцессора. Используется функция compute_pi(), объявленная как общая для CPU и MIC. При вызове указывается необходимость ее запуска на сопроцессоре, если это возможно.
Сравнение явной и неявной схемы работы с памятью
В таблице 6 приводятся основные моменты, на которые стоит обратить внимание при выборе той или иной схемы работы с памятью. Вкратце, неявная схема более удобна в использовании, а явная предоставляет больше возможностей для контроля и оптимизации.
| Явная схема | Неявная схема | |
|---|---|---|
| Типы данных, для которых возможно автоматическое копирование | Скаляры, массивы, структуры с возможностью побитового копирования | Все типы данных |
| Когда происходит передача данных | Пользователь может явно контролировать передачу данных для каждой Offload директивы | Разделяемые данные синхронизируются в начале и в конце операторов _Cilk_offload |
| Когда Offload код копируется на сопроцессор | При первом вызове #pragma offload | В начале работы программы |
| Поддержка языков программирования | Fortran, C, C++ (без возможности передачи объектов класса) | C, C++ |
| Синтаксис | Директивы #pragma offload (С/C++) и !dir$ offload (Fortran) | Ключевые слова _Cilk_shared и _Cilk_offload |
| Используется для… | Передачи непрерывных блоков данных | Передачи сложных структур данных или многих маленьких участков данных |
Для обеих схем компилятор генерирует два типа бинарных кодов процессорную и сопроцессорную версию. Версия для CPU содержит все переменные и функции независимо от того, отмечены ли они offload директивами (ключевыми словами), или нет. Сопроцессорная версия содержит только функции и переменные, отмеченные как offload. Обе версии объединены в один исполняемый файл.
Svetlana Svetlana