
|
не хватает одного параметра: static void Main(string[] args) |
Опубликован: 23.04.2013 | Доступ: свободный | Студентов: 859 / 186 | Длительность: 12:54:00
Лекция 5:
Потоки и параллельные вычисления
Потоки и параллельные алгоритмы
После рассмотрения учебных примеров давайте попробуем применить потоки к алгоритмам, которые рассматривались в "Параллельные алгоритмы" . Начнем с алгоритма вычисления определенного интеграла.
Вычисление определенного интеграла
Для вычисления интеграла на интервале [a, b] для распараллеливания вычислений можно применить простой прием. Интервал [a, b] разбивается на p отрезков по числу используемых процессоров. На каждом отрезке вычисляется интеграл по обычной последовательной схеме. Это типичный прием, когда исходная задача сводится к p подзадачам меньшего размера. Объединение решений подзадач в данном случае сводится к простому суммированию полученных значений.
В "Параллельные алгоритмы" мы построили класс NewIntegral, в который включили чисто последовательный вариант вычисления интеграла - DefiniteIntegral и последовательный вариант с разделением интервала интегрирования на отрезки - SequenceIntegralWithSegments.
В методе SequenceIntegralWithSegments итерации внешнего цикла независимы и могут выполняться параллельно. Давайте посмотрим, как можно использовать потоки для решения этой задачи. Очевидное решение состоит в том, чтобы создать массив потоков по числу отрезков, на которые разбивается интервал интегрирования. Каждый из потоков должен выполнять метод DefiniteIntegral для своих входных данных и результат посылать в свою ячейку памяти. Пересечений по данным у потоков нет, и потому проблем, связанных с взаимодействием потоков, не должно возникать.
Как в данной ситуации передать потоку метод, который он должен выполнять? Кажется, что наилучшее решение дает определение в момент создания потока анонимного метода, в котором можно вызвать метод DefiniteIntegral, передав ему нужные параметры.
К сожалению, теоретически правильная конструкция на практике не всегда работает корректно. Точно описать ситуацию, когда возникает некорректность в работе, пока не могу.
Давайте рассмотрим другой более надежный вариант решения стоящей перед нами задачи.
В класс NewIntegral, введенный в "Параллельные алгоритмы" , добавим метод, в котором распараллеливание вычислений ведется с использованием потоков:
/// <summary>
/// Параллельное вычисление интеграла
/// несколькими потоками
/// </summary>
public void ParallelIntegralWithThreads()
{
Thread[] threads = new Thread[p];
for (int i = 0; i < p; i++)
{
threads[i] = new Thread(ThreadTaskIntegral);
threads[i].Start(i);
}
for (int i = 0; i < p; i++)
{
threads[i].Join();
}
result = 0;
for (int i = 0; i < p; i++)
{
result += results[i];
}
}Потоки создаются по числу отрезков разбиения интервала интегрирования. В момент создания потоку передается метод ThreadTaskIntegral, который и будет выполняться потоком. Вот код этого метода:
void ThreadTaskIntegral(object index)
{
int i = (int)index;
double dx = (b - a) / p;
double start = 0, finish = 0;
start = a + i * dx;
finish = start + dx;
DefiniteIntegral(start, finish, out results[i]);
}Методу в качестве параметра передается индекс итерации. Благодаря этому можно рассчитать границы отрезка, на котором будет вестись интегрирование данным потоком. Для этого отрезка вызывается последовательный метод DefiniteIntegral, который результат вычисления интеграла поместит в соответствующий элемент массива результатов. Параллельно работающие потоки не пересекаются по данным, что обеспечивает их независимую работу.
В заключение приведу результаты экспериментов по вычислению интеграла. В качестве подынтегральной функции рассматривается функция, задающая гармонические колебания:

Здесь A - амплитуда, а 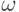 - частота колебаний. Вычисления, как уже говорилось, ведутся на 64-х битном компьютере с 6 Гб памяти, с четырьмя ядрами и восемью виртуальными процессорами. Приведу результаты экспериментов по вычислению интеграла в зависимости от числа разбиений интервала интегрирования на отрезки, а тем самым от степени параллелизма и числа создаваемых потоков:
- частота колебаний. Вычисления, как уже говорилось, ведутся на 64-х битном компьютере с 6 Гб памяти, с четырьмя ядрами и восемью виртуальными процессорами. Приведу результаты экспериментов по вычислению интеграла в зависимости от числа разбиений интервала интегрирования на отрезки, а тем самым от степени параллелизма и числа создаваемых потоков:
| Число разбиений интервала интегрирования | 1 | 2 | 4 | 8 | 16 | 32 |
| Последовательный алгоритм | 565 500 993 | 564 876 992 | 598 453 693 | 565 344 993 | 563 472 990 | 564 408 992 |
| Последовательный алгоритм с разбиением на отрезки | 565 188 993 | 211 848 372 | 401 856 706 | 410 436 721 | 752 077 321 | 407 472 715 |
| Параллельный алгоритм с потоками | 591 241 038 | 143 520 252 | 152 752 417 | 90 636 159 | 140 244 246 | 73 944 130 |
Последовательный алгоритм не зависит от числа потоков и показывает практически одинаковое время, появляющийся разброс определяется ошибками измерений времени. Последовательный алгоритм с разбиением на отрезки дает, как правило, лучшие результаты, чем интегрирование на всем интервале. Мы уже поясняли, что связано это с эффективным выбором числа точек на каждом отдельном отрезке. Параллельный алгоритм, в котором вычисление интеграла на каждом отрезке ведется в отдельном потоке, ведет себя предсказуемым образом. Он дает лучшие результаты, выигрывая по времени в 4 - 5 раз. При этом увеличение числа потоков до 32 не ухудшает результаты. Более того, наилучший результат в этом эксперименте достигается именно для 32-х потоков.
Следует заметить, что результаты зависят от величины интервала интегрирования и простоты интегрируемой функции. Чем выше частота гармонических колебаний, тем лучшие результаты показывает параллельный алгоритм с потоками в сравнении с последовательным алгоритмом. Но и для простейшего случая, когда амплитуда и частота колебаний равна 1, а интегрирование ведется на отрезке от 0 до  , потоковый алгоритм показывает лучший результат, заканчиваясь практически с нулевым временем работы. На следующем рисунке показан сеанс работы алгоритма для такого случая:
, потоковый алгоритм показывает лучший результат, заканчиваясь практически с нулевым временем работы. На следующем рисунке показан сеанс работы алгоритма для такого случая:
Пузырьковая сортировка и потоки
Рассмотрим теперь подключение потоков к алгоритмам сортировки, рассмотренным в "Параллельные алгоритмы" . Начнем с алгоритма пузырьковой сортировки. Параллельная версия этого алгоритма, которую мы написали, основана на распараллеливании по данным. Исходный массив разбивается на подмножества, для чего используется шаговый алгоритм. Каждое подмножество сортируется независимо, а затем результаты отсортированных подмножеств сливаются. Этот алгоритм показывает лучшие результаты, даже при выполнении его одним процессором. Можно ли добиться улучшения, если сортировка каждого подмножества выполняется в отдельном потоке?
Давайте напишем реализацию этого подхода. При создании потоков будем использовать не анонимные методы, а надежный подход с объектами специально созданного класса SortOne. Этот класс будет содержать метод, выполняющий сортировку, а все необходимые данные будут содержаться в полях класса. Вот как выглядит этот класс:
class SortOne
{
double[] mas;
int j;
int p;
int n;
public SortOne(double[] mas, int j, int p)
{
this.mas = mas;
this.j = j;
this.p = p;
n = mas.Length;
}
/// <summary>
/// Сортирует пузырьком часть массива mas
/// начиная с элемента с номером n - j -1
/// Сортируемые элементы отстоят на расстоянии p
/// </summary>
public void BubbleSortPart()
{
int i0 = n - j - 1, m = i0 / p;
double temp;
//цикл по числу проходов m
for (int k = 0; k < m; k++)
{
//цикл всплытия легкого элемента на k-м проходе
for (int i = i0; i - p >= k * p; i = i - p)
{
if (mas[i] < mas[i - p])
{//swap
temp = mas[i];
mas[i] = mas[i - p];
mas[i - p] = temp;
}
}
}
}
}Теперь напишем версию параллельного алгоритма пузырьковой сортировки с введением потоков:
/// <summary>
/// Версия параллельного алгоритма
/// пузырьковой сортировки с введением потоков
/// для сортировки подмножеств массива
/// </summary>
/// <param name="mas">сортируемый массив</param>
/// <param name="processors">число подмножеств</param>
public void BubbleSortWithTreads(double[] mas, int processors)
{
Thread[] threads = new Thread[processors];
SortOne[] sorts = new SortOne[processors];
//Создание объектов SortOne,
//передаваемых создаваемым потокам
for (int i = 0; i < processors; i++)
{
sorts[i] = new SortOne(mas, i, processors);
threads[i] = new Thread(sorts[i].BubbleSortPart);
threads[i].Start();
}
//Синхронизация
for (int i = 0; i < processors; i++)
{
threads[i].Join();
}
//Слияние отсортированных последовательностей
Merge(mas, processors);
}Особых пояснений помимо комментариев, включенных в текст метода, видимо не требуется, поскольку подобный прием уже применялся при построении метода вычисления интеграла. Текст процедуры слияния Merge ранее приведен в "Параллельные алгоритмы" . В заключение приведем результаты экспериментов по сортировке массива вещественных чисел, содержащего100 000 элементов.
| Число разбиений массива на подмножества | 1 | 2 | 4 | 8 | 16 | 32 |
| Последовательный алгоритм | 460 980 809 |  |
|
|
|
|
| Последовательный алгоритм с разбиением на подмножества | |
283 296 498 | 141 492 249 | 74 412 130 | 36 504 065 | 18 096 032 |
| Параллельный алгоритм с потоками | |
164 268 288 | 52 416 092 | 19 188 033 | 10 296 018 | 6 396 011 |
Последовательный алгоритм не зависит от разбиений и во всех случаях дает одни и те же результаты по времени работы. При единичном разбиении его результаты лучше, чем результаты двух других версий алгоритма по понятным причинам - алгоритм проще.
Версия алгоритма с разбиением массива на подмножества существенно эффективнее последовательного алгоритма, - при разбиении исходного массива на 32 подмножества время сортировки уменьшается более чем в 20 раз. Причина этого эффекта уже объяснялась - в шаговом варианте разбиения легкие элементы всплывают быстрее.
Версия параллельного алгоритма с потоками в данном случае дает существенный выигрыш. При числе потоков, равном 32, она на два порядка лучше чисто последовательной версии и в три раза лучше версии с разбиением на подмножества. Результаты улучшаются с возрастанием числа используемых потоков. Введение потоков дает существенный эффект при увеличении размера сортируемого массива. Для небольших массивов введение потоков особого эффекта не дает.
Алексей Рыжков
Никита Белов
|
Выставил оценки курса и заданий, начал писать замечания. После нажатия кнопки "Enter" окно отзыва пропало, открыть его снова не могу. Кнопка "Удалить комментарий" в разделе "Мнения" не работает. Как мне отредактировать недописанный отзыв? |