

|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 12:
Создание модели хранилища данных на основе корпоративной модели данных
Производные элементы данных
При проектировании БД OLTP-систем производные (выводимые) элементы данных, как правило, не включаются в структуру данных, и следовательно, корпоративная модель данных редко содержит такие данные. Производные данные не включаются в корпоративную модель данных, чтобы максимально исключить избыточность данных и сократить число элементов данных в модели.
Вопрос, нужно ли включать производные данные в модель ХД, является важным с точки зрения объема вычислений при обработке данных в ХД. Если размер ХД очень большой или растет очень быстро, то целесообразно включить в модель данных такие элементы данных, которые, будучи один раз вычислены при загрузке ХД, с течением времени своих значений не изменяют.
Проектировщику следует иметь в виду, что включение новых элементов данных в модель ХД приводит к излишнему увеличению размера ХД. Поэтому в модель ХД следует включать такие производные элементы данных, которые предполагается использовать достаточно часто.
Таким образом, критерий отбора производных полей для включения в модель ХД состоит в выполнении следующих двух условий:
- частота использования производных полей приложениями ХД достаточно высока;
- вычисленные значения элементов данных после занесения их в ХД не изменяются со временем.
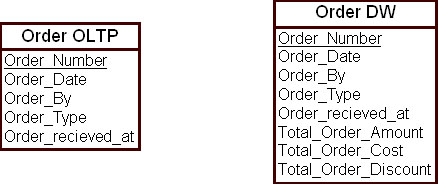
На рис. 16.7 проиллюстрирована процедура добавления производных полей в модель ХД на примере сущности "Заказ" ( Order ).
Введенные в модель ХД производные поля сущности "Заказ" — это атрибуты "Суммарное количество заказа" ( total_order_amount ), "Итоговая стоимость заказа" ( total_order_cost ), "Итоговая скидка по заказу" ( total_order_discount ). После закрытия заказа эти атрибуты не будут изменять свои значения. С другой стороны, при анализе продаж организации в рамках ХД вероятность частого использования этих полей в запросах велика. Поэтому было целесообразно включить эти атрибуты в модель ХД.
Трансформация взаимосвязей между данными
Одним из сложных вопросов проектирования ХД является вопрос о трансформации взаимосвязей корпоративной модели данных во взаимосвязи данных ХД. Проектировщик ХД должен ясно понимать суть этой проблемы, чтобы принять адекватные проектные решения, отражающие взаимосвязи в данных.
В корпоративной модели данных, как правило, предполагается, что каждая связь между сущностями фиксирует только одно бизнес-правило предметной области БД OLTP-системы. Эта взаимосвязь между сущностями корректна на момент доступа к данным, если данные адекватно отражают состояние сущностей в предметной области. Такой "моментный" характер интерпретации связи в корпоративной модели данных может потерять смысл при рассмотрении этой взаимосвязи между данными с точки зрения временной ретроспективы, которая характерна для модели ХД.
Рассмотрим вопрос, как взаимосвязь между сущностями корпоративной модели может быть представлена в ХД, когда данные из БД OLTP-системы загружены в ХД.
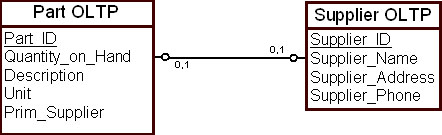
В качестве примера расследуем взаимосвязь между сущностями "Комплектующие" ( Part OLTP ) и "Поставщик" ( Supplier OLTP ). Эта взаимосвязь отражает бизнес-правило: каждое изделие поставляется от определенного поставщика. В частности, в организации может быть принято бизнес-правило: каждое изделие имеет основного поставщика. Тогда ограничение целостности состоит в том, что в БД не существует изделий, у которых нет основного поставщика. Это взаимосвязь действительна на момент доступа к данным ( рис. 16.8).
Допустим, что данные загружаются в ХД по принципу периодического моментального снимка. Периодический моментальный снимок таблицы с комплектующими деталями делается по концу отчетного периода — конец недели, конец месяца, конец квартала и т.д. Данные, описывающие изделие, захватываются в оперативной БД и помещаются в ХД в эти моменты времени. В том числе и основной поставщик изделия на момент взятия снимка, т.е. связь представляется в ХД через значения своих данных на момент взятия снимка.
Сущность "Комплектующие" меняет свое состояние достаточно быстро, поскольку изделия постоянно поставляются и отгружаются со склада. Сущность "Поставщик" меняет свое состояние гораздо медленнее, поэтому периодический моментальный снимок таблицы с поставщиками делается, например, раз в квартал. Таким образом, занесенный в ХД поставщик является по существу последним поставщиком данного изделия на момент взятия снимка ( рис. 16.9).
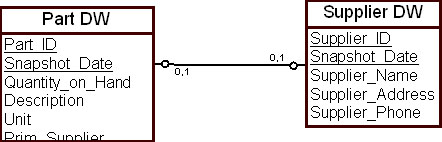
Рис. 16.9. Трансформация взаимосвязи между изделием и поставщиком в ХД после периодического моментального снимка
Главный недостаток таких периодических моментальных снимков состоит в том, что они могут неадекватно отражать состояние взаимосвязей между сущностями. В течение недели изделие может иметь пять основных поставщиков (т.е. менять их каждый рабочий день), но моментальный снимок не будет отражать таких изменений. Поставщик за квартал может отгрузить много различных изделий, но моментальный снимок покажет только последнюю сделанную отгрузку.
Из примера видно, что для того чтобы адекватно представить взаимосвязь между данными в ХД, требуется использовать историческую модель представления данных для рассмотренных сущностей.
В исторической модели данных сущность трактуется как совокупность своих последовательных состояний. Для исторической таблицы "Комплектующие" ( Part DW ) при получении изделия фиксируется вся подробная информация, в том числе и поставщик изделия. При таком подходе взаимосвязь между двумя сущностями, "Комплектующие" ( Part DW ) и "Поставщик" ( Supplier DW ), представлена в ХД полностью.
Если для поставщиков также поддерживается историческая таблица, то в нее заносятся данные о каждом заказе на получаемые изделия, сделанном поставщику. Таким образом, в ХД будут зафиксированы все отгрузки поставщика.
Пример дискретной исторической модели представления взаимосвязи приведен на рис. 16.10.
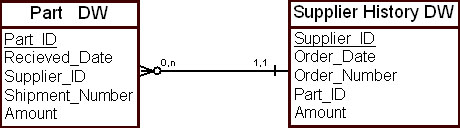
Рис. 16.10. Представление взаимосвязи между изделием и поставщиком в ХД в исторической модели данных
Таким образом, при выборе формы представления взаимосвязи между данными в ХД проектировщик должен учитывать следующие правила:
- историческая трактовка данных, относящихся к сущности;
- изменение качественного содержания бизнес-правила корпоративной модели данных при представлении его в ХД.
Определение уровня структуризации (гранулированности) данных
Уровень структуризации или детализации данных ( гранулированность ), как уже указывалось в предыдущих лекциях, является важной характеристикой ХД. В процессе проектирования проектировщик ХД принимает решение об уровне структуризации данных. При использовании корпоративной модели данных проектировщик решает вопрос: достаточен ли уровень структурированности данных в этой модели для представления в модели ХД? И если нет, то устанавливает необходимый уровень структуризации данных.
Для определения уровня структуризации данных в модели ХД проектировщик пытается получить от аналитиков предметной области ответы на следующие типовые вопросы:
- Какие элементы данных будут суммироваться?
- За какой период времени данные будут суммироваться (день, месяц, год)?
- Соответствует ли выбранный уровень структуризации данных для ХД уровню структуризации в корпоративной модели?
При определении степени детализации фактов проектировщик должен обратиться, в первую очередь, к изучению бизнес-процессов организации, для которой разрабатывается модель ХД. Как правило, каждый бизнес-процесс требует отдельной многомерной модели с уникальным определением гранулированности фактов.
С точки зрения проектировщика ХД каждый бизнес-процесс состоит из нескольких фактов и измерений, которые отличаются от других бизнес-процессов. Давайте на примере рассмотрим применение этого простого принципа к определению гранулированности фактов в модели ХД.
Предположим, что нам нужно построить многомерную модель ХД для розничной торговли в сети магазинов, расположенных в различных регионах (бизнес-процесс). Первый вопрос, который интересует руководство организации, это анализ сбыта товаров во всех магазинах. Второй вопрос, который интересует руководство, — анализ причин возврата товаров по всем магазинам и анализ всех поставщиков с учетом процента возврата товаров по каждому из них.
Существуют два различных определения гранулированности фактов для определенного выше бизнес-процесса. Для анализа сбыта товаров гранулированность может быть определена следующим образом (Случай 1): на каждый товар, включенный в один счет покупки.
Для анализа причин возврата товаров гранулированность может быть определена следующим образом (Случай 2): конкретный товар, возвращенный покупателем в любой из магазинов.
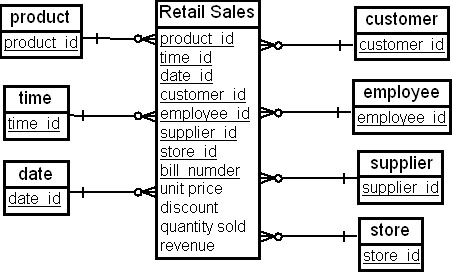
В первом случае в качестве измерений будут выступать "Товар" ( product ), "Время" ( time ), "Покупатель" ( customer ), "Дата" ( date ), "Продавец" ( employee ), "Поставщик" ( supplier ) и "Магазин" ( store ). В качестве фактов могут быть выбраны следующие: "Цена товара" ( unit price ), "Скидка" ( discount ), "Количество проданных товаров" ( quantity sold ) и "Доход" ( revenue ). Схема "звезда" с таблицей фактов "Розничная продажа" ( Retail Sales ) для этого случая показана на рис. 16.11.
Во втором случае в качестве измерений будут выступать "Дата возврата" ( return date ), "Дата покупки" ( purchase date ), "Покупатель" ( customer ), "Магазин, который продал бракованный товар" ( store purchased ). "Возвращенный товар" ( products returned ), "Причина возврата" ( reasons for return ), "Поставщик" ( supplier ). В качестве фактов могут быть выбраны "Потерянный доход от возврата" ( revenue returned ) и "Количество возвращенных товаров" ( quantity returned ). Схема "звезда" с таблицей фактов "Возвращенный товар" ( Return Products ) для этого случая показана на рис. 16.12.

увеличить изображение
Рис. 16.12. Схема "звезда" для модели ХД учета возврата товаров по сети магазинов розничной торговли
Как видно из сказанного, одному бизнес-процессу может отвечать несколько многомерных моделей. Сколько создавать таблиц фактов для одного бизнес-процесса — определяет проектировщик ХД. Ясно, что для каждого бизнес-процесса должна быть одна модель (схема "звезда" или "снежинка"). Если гранулированность фактов различна, то их следует помещать в различные таблицы.
Перенесение атрибутов из таблиц корпоративной модели данных в таблицы хранилища данных
На следующем шаге преобразования корпоративной модели данных в модель ХД проектировщик объединяет набор таблиц корпоративной модели данных в таблицы ХД в рамках выбранной многомерной модели. Таблицы корпоративной модели данных, как правило, нормализованы в соответствии с требованиями реляционной модели. Объединение нескольких нормализованных таблиц в одну является денормализацией схемы БД. Для ХД большого размера денормализация выполняется исходя из соображений производительности. Объединение таблиц экономит дисковое пространство и увеличивает производительность обработки запросов.
Несмотря на соображения производительности, проектировщик ХД при объединении таблиц должен помнить о том, что таблицы имеет смысл объединять, если:
- таблицы имеют общий ключ;
- частота совместного использования данных из нескольких таблиц в запросах высока;
- данные добавляются в таблицы одинаковым образом.
Рассмотрим пример на рис. 16.13. В корпоративной модели данных имеются три нормализованные таблицы, содержащие данные об изделиях. Все три таблицы БД OLTP-системы, показанные на рисунке сверху, имеют один и тот же первичный ключ "Номер изделия" ( Part_ID ). Поэтому имеет смысл в модели ХД объединить эти таблицы в одну "Комплектующие объединенные" ( Part Merge DW ), как показано на рисунке внизу.
Массивы данных
Нормализованные таблицы корпоративной модели данных не содержат периодических групп и массивов данных. Таковы требования реляционной модели. Однако для ХД использование таких элементов данных может быть целесообразным. По своему усмотрению проектировщик ХД может рассмотреть вопрос о создании массивов данных в реляционной модели. При принятии решения о создании массивов данных можно руководствоваться следующими соображениями — массив данных имеет смысл создавать, если:
- размерность массива постоянна или предсказуема;
- размер массива не очень велик;
- элементы массива используются совместно.
С точки зрения физического проектирования схемы базы данных это называется разбиением или секционированием таблиц. Разбиение и секционирование являются схожими методами, но различаются по механизму реализации. Разбиение — это логический прием, а секционирование — встроенный механизм диалекта SQL. Для ХД обычно используется секционирование.
Секционирование выполняется из соображений повышения производительности обработки запросов. Обоснование использования секционирования для схем ХД, кратко говоря, состоит в следующем. Таблица фактов, как правило, одна. Временной атрибут, как правило, входит как часть ключа. Время по своей природе имеет предсказуемую структуру измерения — день, неделя, месяц, квартал, год и т.д. Поэтому целесообразно рассмотреть возможность секционирования таблицы фактов по единицам измерения времени.
Например, телефонные компании часто выставляют счета своим абонентам за разговоры в течение месяца. Поэтому можно рассмотреть возможность представления таблицы оплаты счетов абонентами как массива из двенадцати элементов, каждый из которого отвечает месяцу года. Хотя на практике информационные службы телефонных компаний используют такой подход редко, с точки зрения анализа задолженности клиентов он оказывается весьма эффективным.
Примеры секционирования таблиц были рассмотрены в "Знакомство с CASE инструментом" .
Группировка данных в соответствии с частотой использования
Реляционная модель (а, следовательно, и построенная на ее основе корпоративная модель данных — тоже) не различает скорость изменения данных внутри таблицы. ХД имеют одной из своих главных функций накопление данных, и скорость поступления данных для них имеет значение. Другими словами, ХД чувствительны к скорости добавления данных.
Чтобы нивелировать чувствительность к скорости добавления данных в ХД, таблицы следует организовывать следующим образом: медленно меняющиеся данные помещать в одну таблицу, а быстро меняющиеся — в другую. Т.е. скорость изменения количества данных в каждой из таблиц ХД должна быть приблизительно одинаковой.
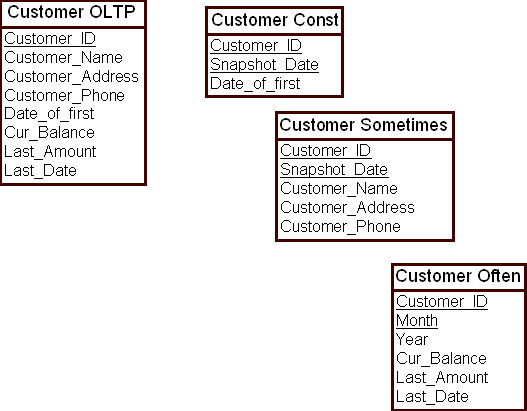
Рассмотрим пример. В корпоративной модели данных имеются данные о покупателях, которые были объединены в одну таблицу – "Покупатели OLTP" ( Customer OLTP ). Среди атрибутов этой таблицы есть данные, которые никогда не меняются, например, значения атрибута "Дата первой покупки" ( First_Date ). Есть и данные, которые иногда меняются, например, значение атрибута "Телефон покупателя" ( Customer_Phone ). Также здесь существуют данные, которые меняются часто, например, значение атрибута "Дата последней покупки" ( Last_Date ).
Такую таблицу целесообразно разбить на три таблицы. Первая таблица содержит атрибуты с постоянными данными; вторая содержит атрибуты, значения которых иногда меняются; третья — атрибуты, значения которых меняются часто. На рис. 16.14 показана схема ХД, которая учитывает принцип изменчивости значений атрибутов.
Таким образом, мы рассмотрели все восемь шагов базового алгоритма преобразования данных корпоративной модели в модель ХД.
Первый этап алгоритма перекидывает мостик от корпоративной модели данных к модели ХД. Этапы со второго по шестой по своей сути представляют процесс многомерного проектирования, который далее мы рассмотрим с позиции использования CASE-средств проектирования многомерных моделей. Седьмой и восьмой шаги непосредственно связаны с обеспечением производительности ХД на уровне проектных решений.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|