
| Украина |
Инспектор
Вы можете этот курс.
Опубликован: 22.04.2008 | Уровень: специалист | Доступ: платный | ВУЗ: Лаборатория Параллельных информационных технологий НИВЦ МГУ
Лекция 4:
Коллективные взаимодействия процессов
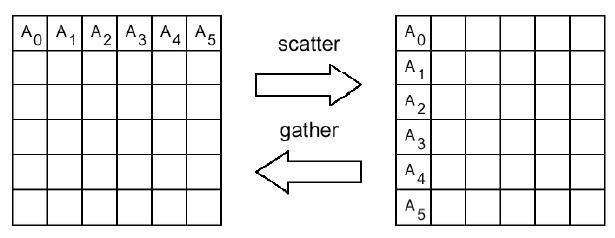
Например, для того чтобы процесс 2 собрал в массив rbuf по 10 целочисленных элементов массивов buf со всех процессов приложения, нужно, чтобы во всех процессах встретился следующий вызов:
call MPI_GATHER(buf, 10, MPI_INTEGER, & rbuf, 10, MPI_INTEGER, & 2, MPI_COMM_WORLD, ierr) MPI_GATHERV(SBUF, SCOUNT, STYPE, RBUF, RCOUNTS, DISPLS, RTYPE, ROOT, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNTS(*), DISPLS(*), RTYPE, ROOT, COMM, IERR
Сборка различного количества данных из массивов SBUF. Порядок расположения данных в результирующем буфере RBUF задает массив DISPLS.
RCOUNTS - целочисленный массив, содержащий количество элементов, передаваемых от каждого процесса (индекс равен рангу посылающего процесса, размер массива равен числу процессов в коммуникаторе сомм ).
DISPLS - целочисленный массив, содержащий смещения относительно начала массива RBUF (индекс равен рангу посылающего процесса, размер массива равен числу процессов в коммуникаторе сомм ).
Данные, посланные процессом J-1, размещаются в J-oм блоке буфера RBUF на процессе ROOT, который начинается со смещением в DISPLS ( J) элементов типа RTYPE с начала буфера.
MPI_SCATTER(SBUF, SCOUNT, STYPE, RBUF, RCOUNT, RTYPE, ROOT, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNT, RTYPE, ROOT, COMM, IERR
Процедура MPI_SCATTER по своему действию является обратной к MPI_GATHER. Она осуществляет рассылку по SCOUNT элементов данных типа STYPE из массива SBUF процесса ROOT В массивы RBUF всех процессов коммуникатора сомм, включая сам процесс ROOT. Можно считать, что массив SBUF делится на равные части по числу процессов, каждая из которых состоит из SCOUNT элементов типа STYPE, после чего i-я часть посылается (i-1)-му процессу.
На процессе ROOT существенными являются значения всех параметров, а на всех остальных процессах - только значения параметров RBUF, RCOUNT, RTYPE, SOURCE и сомм. Значения параметров SOURCE и СОММ ДОЛЖНЫ быть одинаковыми у всех процессов.
Следующая схема иллюстрирует действие процедуры MPI_SCATTER.
В следующем примере процесс о определяет массив sbuf, после чего рассылает его по одному столбцу всем запущенным процессам приложения. Результат на каждом процессе располагается в массиве rbuf.
real sbuf(size, size), rbuf(size) if(rank .eq. 0) then do 1 i = 1, size do 1 j = 1, size 1 sbuf(i, j) = .. . end if if (numtasks .eq. size) then call MPI_SCATTER(sbuf, size, MPI_REAL, & rbuf, size, MPI_REAL, & 0, MPI_COMM_WORLD, ierr) end if MPI_SCATTERV(SBUF, SCOUNTS, DISPLS, STYPE, RBUF, RCOUNT, RTYPE, ROOT, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNTS(*), DISPLS(*), STYPE, RCOUNT, RTYPE, ROOT, COMM, IERR
Рассылка различного количества данных из массива SBUF. Начало порций рассылаемых данных задает массив DISPLS.
SCOUNTS - целочисленный массив, содержащий количество элементов, передаваемых каждому процессу (индекс равен рангу адресата, длина равна числу процессов в коммуникаторе сомм ).
DISPLS - целочисленный массив, содержащий смещения относительно начала массива SBUF (индекс равен рангу адресата, длина равна числу процессов в коммуникаторе сомм ).
Данные, посылаемые процессом ROOT процессу J-1, размещены в J-oм блоке буфера SBUF, который начинается со смещением в DISPLS (J) элементов типа STYPE с начала буфера SBUF.
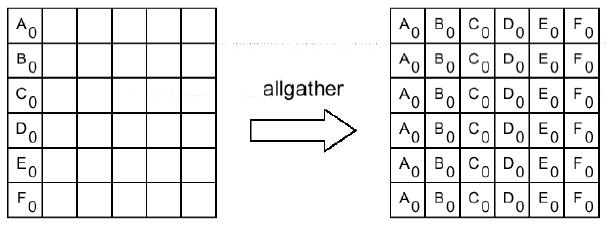
MPI_ALLGATHER(SBUF, SCOUNT, STYPE, RBUF, RCOUNT, RTYPE, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNT, RTYPE, COMM, IERR
Сборка данных из массивов SBUF со всех процессов коммуникатора сомм в буфере RBUF каждого процесса. Данные сохраняются в порядке возрастания номеров процессов. Блок данных, посланный процессом J-1, размещается в J-oм блоке буфера RBUF принимающего процесса. Операцию можно рассматривать как MPI_GATHER, при которой результат получается на всех процессах коммуникатора сомм.
Следующая схема иллюстрирует действие процедуры MPI_ALLGATHER.
MPI_ALLGATHERV(SBUF, SCOUNT, STYPE, RBUF, RCOUNTS, DISPLS, RTYPE, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNTS(*), DISPLS(*), RTYPE, COMM, IERR
Сборка на всех процессах коммуникатора сомм различного количества данных из массивов SBUF. Порядок расположения данных в массиве RBUF задает массив DISPLS.
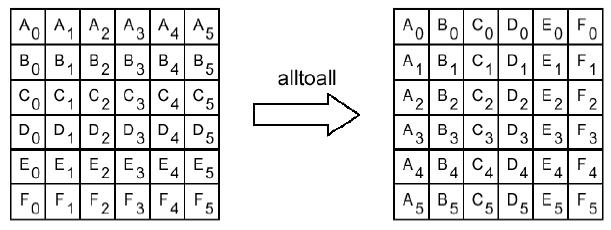
MPI_ALLTOALL(SBUF, SCOUNT, STYPE, RBUF, RCOUNT, RTYPE, COMM, IERR) <type> SBUF(*), RBUF(*) INTEGER SCOUNT, STYPE, RCOUNT, RTYPE, COMM, IERR
Рассылка каждым процессом коммуникатора сомм различных порций данных всем другим процессам, J-Й блок данных буфера SBUF (i-i) -ro процесса попадает в 1-й блок данных буфера RBUF (j-i) -ro процесса.
Следующая схема иллюстрирует действие процедуры MPI_ALLTOALL.