
| Россия, Москва |
Инспектор
Вы можете этот курс.
Опубликован: 13.09.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Лекция 14:
Адаптивная резонансная теория (АРТ)
а) если критерий сходства не выполняется, схема сброса вырабатывает сигнал  , который тормозит нейрон
, который тормозит нейрон  в слое
распознавания. Сигнал остается равным 1 до окончания данной
классификации. Выход нейрона становится равным 0, а, следовательно, и весь
вектор
в слое
распознавания. Сигнал остается равным 1 до окончания данной
классификации. Выход нейрона становится равным 0, а, следовательно, и весь
вектор  . Сигнал
. Сигнал 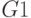 становится равным нулю и вектор
становится равным нулю и вектор  снова проходит
через слой сравнения без
изменений, вызывая новый цикл поиска (шаги
2в-3б), пока критерий
сходства не будет удовлетворен.
снова проходит
через слой сравнения без
изменений, вызывая новый цикл поиска (шаги
2в-3б), пока критерий
сходства не будет удовлетворен.
При соответствующем выборе начальных значений весов 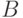 поиск
всегда
закончится на нераспределенном нейроне слоя распознавания. Для него будет
выполнен критерий сходства, т.к. все веса
поиск
всегда
закончится на нераспределенном нейроне слоя распознавания. Для него будет
выполнен критерий сходства, т.к. все веса 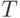 равны 1.
Если все нейроны
выделены и критерий сходства не выполняется, следует аварийная остановка
либо расширение сети введением нового нейрона в слое распознавания и новых
входов в слое сравнения.
равны 1.
Если все нейроны
выделены и критерий сходства не выполняется, следует аварийная остановка
либо расширение сети введением нового нейрона в слое распознавания и новых
входов в слое сравнения.
5. Обучение.
Независимо от того, найден ли на этапе поиска распределенный нейрон или
нераспределенный, обучение протекает одинаково. Корректируются лишь веса
выигравшего нейрона в слое распознавания и веса 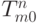 для всех
для всех  в слое
сравнения.
в слое
сравнения.
Различают быстрое и медленное обучение. При быстром обучении коррекции весов имеют вид:
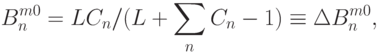
где  - константа.
- константа.
Веса в слое сравнения - двоичные: .
В результате такого алгоритма обучения ядра изменяются,
несущественные
компоненты обнуляются в процессе обучения. Если какая-то компонента
вектора 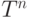 стала нулевой на какой-то итерации обучения, она
никогда не
вернется к единице. В этом проявляется асимметрия АРТ по отношению к
значениям 0 и 1. Эта асимметрия имеет серьезные
отрицательные последствия
для модели, приводя к деградации ядер классов в случае зашумленных входных
векторов.
стала нулевой на какой-то итерации обучения, она
никогда не
вернется к единице. В этом проявляется асимметрия АРТ по отношению к
значениям 0 и 1. Эта асимметрия имеет серьезные
отрицательные последствия
для модели, приводя к деградации ядер классов в случае зашумленных входных
векторов.
Медленное обучение меняет ядра малыми коррекциями:
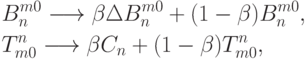
где  мало и характеризует скорость обучения.
мало и характеризует скорость обучения.
В результате каждой итерации обучения ядра меняются незначительно.
Видно, что веса в любой момент времени могут быть однозначно
рассчитаны
через веса , таким образом, кодирование информации о ядрах в АРТ
в
рассмотренной модели является избыточным в смысле расхода памяти.