Инспектор
Вы можете этот курс.
Опубликован: 22.12.2006 | Уровень: специалист | Доступ: платный | ВУЗ: Московский государственный университет путей сообщения
Лекция 10:
Асинхронная ВС на принципах "data flow"
Дисциплина обращения к памяти данных
Так как процесс коммутации процессорных элементов, включая процессор памяти, отделен от процесса вычислений и исполнительные устройства работают асинхронно, важно обеспечить в ПП порядок обращения к ОПД, предусмотренный алгоритмом преобразования данных. В противном случае возникает возможность нарушения последовательности изменения определенных данных, находящихся в памяти. Конкретно это означает, что последовательность обращения к каждой ячейке памяти по записи и считыванию в процессе выполнения операций должна быть такой, которая предусмотрена алгоритмом.
Сохранение такого порядка облегчается последовательной обработкой команд на процессоре, допускающей упорядочение заявок к памяти в ОЗП. Здесь в основном воспроизводится та же схема обработки потока заявок, которая рассматривалась при динамическом распараллеливании на уровне команд в лекции 2.
Рассмотрим фрагмент записи алгоритма:
a := a + b; c := a x c.
Он преобразуется в две команды коммутации:
+ a b a
x a c c
с очевидностью определяющие обязательное выполнение порядка обращения к ячейкам a и c.
Считаем, что при обработке каждой трехадресной команды процессор (коммутации) формирует до трех заявок к ОПД: две на считывание (и отсылку по адресу ПЭ-исполнителя) и одну на запись. Адрес заявки на запись сообщается ПЭ-исполнителю, чтобы впоследствии он мог ее дополнить записываемым кодом. В рассматриваемом примере для каждой команды формируются по три заявки к ОПД.
Упорядочение по времени заявок к ОПД, в которых указан один и тот же адрес, обеспечивается тем, что при выборе для исполнения адрес ячейки ОПД, указанный в каждой заявке, сравнивается с адресами ячеек ОПД, указанными в еще не исполненных (находящихся в ОПД) заявках, пришедших ранее. Заявка может быть выполнена лишь в том случае, если выполнены все заявки по указанному в ней адресу, поступившие ранее.
При анализе адресов каждой команды данного примера предположим, что для выполнения первой команды АГ назначил адрес ПЭ (1, 1), а для выполнения второй команды — адрес (2, 1). Процессор сформирует заявки к ОПД в следующем порядке:
- "Считать a — послать в (1, 1), 1" (указана позиция операнда);
- "Считать b — послать в (1, 1), 2";
- "Записать в a
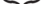 "
( — позиция неизвестного пока кода);
"
( — позиция неизвестного пока кода); - "Считать a — послать в (2, 1), 1";
- "Считать c — послать в (2, 1), 2";
- "Записать в
 ".
".
Очевидно, что заявки 1, 2 и 5 могут выполняться процессором памяти тотчас же после формирования. Выполненные заявки из ОЗП исключаются.
После выполнения ПЭ 1 команды сложения, записанной в регистре 1 его буфера, и отсылки результата в текст заявки 3 эта заявка может быть выполнена. Затем появляется возможность выполнения заявки 4, а после выполнения команды умножения, записанной в регистре 1 буфера ПЭ 2, и отсылки результата в текст заявки 6 — возможность выполнения и этой заявки.
Тогда может быть предложен следующий (идеальный) алгоритм выполнения заявок к памяти данных.
- Производится последовательный просмотр очереди заявок к памяти.
- Если очередная заявка является заявкой на считывание по адресу A (в ОП), анализируется, нет ли выше этой заявки (т.е. среди еще не выполненных заявок) заявки на запись по этому же адресу. Если такая заявка есть, данная заявка на считывание выполнена быть не может. Продолжаем выполнение 1.
- Если выше данной заявки нет невыполненных заявок на запись по этому же адресу, организуется считывание из ОП в указанный в заявке регистр.
- Если очередная заявка является заявкой на запись по адресу A, производится анализ, указан ли в тексте заявки записываемый код результата вычислений. Если код еще не поступил, выполняется шаг 1.
- Если заявка на запись сформирована полностью, производится анализ нет ли выше данной заявки (т.е. среди еще не выполненных заявок) хотя бы одной заявки на запись или считывание по этому же адресу. Если такая заявка существует, выполняется шаг 1.
- Если выше данной заявки нет заявок, в которых указан тот же адрес A, выполняется запись в ОП по этому адресу.
При аппаратной реализации такого алгоритма необходимо учесть модульный принцип построения ОПД, допускающий возможность одновременного выполнения заявок к разным модулям памяти.
Предположим для определенности, что модули ОПД объединяются в блоки, которые адресуются старшими разрядами адреса. Внутри одного блока модули адресуются младшими разрядами адреса в соответствии с интерливингом. Остальная часть адреса — адрес ячейки в модуле памяти.
Так как при анализе одной команды одним процессором может быть сформировано до трех заявок к памяти, то, считая по максимуму, что такое формирование происходит в каждом машинном такте, очевидно, что заявки должны выполняться с таким же темпом. Другими словами, необходимо, аккумулируя заявки к памяти в ОЗП, отделить процесс их выполнения от процесса поступления и организовать дисциплину выполнения таким образом, чтобы в каждом такте имелась возможность выбора до трех заявок к разным модулям памяти в однопроцессорной ВС.
Итак, синхронизация выполнения заявок к ОПД должна удовлетворять двум требованиям:
- Заявки к одной ячейке памяти должны выполняться в порядке вхождения адреса этой ячейки в текст программы — этим обеспечивается алгоритмически заданный порядок преобразования данных.
- При обращении в разных заявках, находящихся в ОЗП, к ячейкам одного и того же модуля памяти целесообразно реализовать простейшую дисциплину устранения конфликта, при которой использование такого модуля производится также в порядке вхождения его адреса (в составе адресов ячеек ОПД) в текст программы.
Очевидно, что дисциплина устранения конфликтов при обращении к одному модулю ОПД включает упорядочение обращения к одной ячейке. Т.е. при выполнении заявок из ОЗП к ОПД достаточно выполнять заявки обращения к одной ячейке (независимо от того, запись это или считывание) в порядке их поступления. Пришедшие одновременно заявки при анализе процессором одной команды упорядочиваются по необходимости в соответствии с номером адреса в команде.
Такое упорядочение имеет единственный недостаток: возможны длительные задержки одних заявок к модулю памяти другими заявками к тому же модулю, несмотря на обращение в разные ячейки. Однако можно считать, что выбором достаточной глубины интерливинга (большого числа модулей в блоке) можно добиться малой вероятности таких задержек. Это согласуется и с общим требованием минимизации числа обращений к оперативной памяти.
Другим способом ускорения алгоритма выполнения заявок к ОПД является формирование и уточнение матрицы следования, связывающей все заявки в ОЗП. При каждом поступлении новой заявки формируется соответствующая строка этой матрицы на основе совместного анализа адресов модулей памяти, указанных в пришедшей заявке, и таких же адресов в других заявках, записанных ранее в ОЗП. При выполнении заявок строки и столбцы, им соответствующие, из матрицы следования исключаются.