
|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 20.12.2010 | Уровень: специалист | Доступ: платный
Лекция 16:
SQL в хранилищах данных: агрегация и суммирование
Аннотация: В настоящей лекции рассматривается расширение диалектов SQL промышленных СУБД для агрегации и суммирования данных в хранилищах данных, приводятся примеры работы со схемой "звезда", содержащей аддитивные и полуаддитивные факты. Разбираются примеры использования расширения оператора SELECT для агрегации данных в ХД.
Ключевые слова: оператор SELECT, предложение ROLLUP, предложение CUBE, предложение GROUP BY, аддитивные факты, полуаддитивные факты, SQL, БД, структурированный язык, запрос SQL, Oracle, server, ANSI, ISO, IBM, СУБД Ingres, СУБД, ПО, программное обеспечение, международный стандарт, SQL/89, стандарт SQL/92, PSM, persistent, PL/SQL, синтаксис, выборка, result, set, операторы, множества, звезда, запрос, эквисоединение, метрика, остаток, store, таблица, значение, разбиение, отношение, объединение, агрегатные функции, проекция, целый, предложение HAVING, CASE-выражение, subtotal, уровни представления данных, tabulation, аналитические функции, функции ранжирования, cumulation, EIS, спецификация запроса, куб данных, data cube, иерархии измерений, прибыль от продаж, EAST, перекрестный запрос, функция GROUPING, статистические функции, маска, TIME, region, базы данных, выражение, функция, согласование типов, подмножество, column, capacity, предикат
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- как используется оператор SELECT для обработки данных в хранилищах данных;
- как используется предложение ROLLUP для агрегации данных в результирующем множестве;
- как используется предложение CUBE для агрегации данных в результирующем множестве;
- как используется предложение GROUPING для агрегации данных в результирующем множестве;
- синтаксис предложения GROUP BY оператора SELECT ;
и научитесь:
- конструировать запросы для обработки аддитивных фактов;
- конструировать запросы для обработки полуаддитивных фактов;
- конструировать запросы для получения отчетов с использованием предложения ROLLUP ;
- конструировать запросы для получения отчетов с использованием предложения CUBE ;
- конструировать запросы для получения отчетов с использованием предложения GROUPING.
Введение
SQL – язык манипулирования данными в реляционной БД. В настоящей лекции мы сконцентрируем внимание на тех возможностях, которые предоставляет SQL для аналитической работы в ХД.
Единственным средством общения и администраторов БД, и проектировщиков, и разработчиков, и пользователей с реляционной БД является структурированный язык запросов SQL (Structured Query Language). SQL есть полнофункциональный язык манипулирования данными в реляционных БД. В настоящее время он является общепризнанным, стандартным интерфейсом для реляционных БД, таких как Oracle, Sybase, DB/2, MS SQL Server и ряда других (стандарты ANSI и ISO).
SQL — непроцедурный язык, который предназначен для обработки множеств, состоящих из строк и колонок таблиц реляционной БД. Существуют расширения SQL, допускающие процедурную обработку. Проектировщики используют SQL для создания всех физических объектов реляционной БД или ХД.
Теоретические основы SQL были заложены в известной статье [Кодд], положившей начало развитию теории реляционных БД. Первая практическая реализации была выполнена в исследовательских лабораториях фирмы IBM Chamberlin D.D. и Royce R.F. Промышленное применение SQL было впервые реализовано в СУБД Ingres. Одной из первых промышленных реляционных СУБД является Oracle. По сути дела, реляционная СУБД – это программное обеспечение, которое управляет работой реляционной БД.
Первый международный стандарт языка SQL был принят в 1989 г. (SQL-89). В конце 1992 г. был принят новый международный стандарт SQL-92. В настоящее время большинство производителей реляционных СУБД используют его в качестве базового. Однако работы по стандартизации языка SQL далеки от завершения, и уже разработан проект стандарта SQL-99, который вводит в обиход языка понятие объекта и разрешает на него ссылаться в операторах SQL. В исходном варианте SQL не было команд управления потоком данных, они появились в принятом стандарте ISO/IEC 9075-5: 1996 дополнительной части SQL.
Каждой конкретной СУБД соответствует своя собственная реализация SQL, в целом поддерживающая определенный стандарт, но имеющая свои особенности. Такие реализации называются диалектами. Так, стандарт ISO/IEC 9075-5 предусматривает объекты, называемые постоянно хранимыми модулями, или PSM-модулями (persistent stored modules). В СУБД Oracle расширение PL/SQL является аналогом указанного выше расширения стандарта.
Далее в примерах будет использоваться диалект SQL (Transact-SQL) СУБД MS SQL Server 2005/2008.
Оператор SELECT и схема "звезда"
Синтаксис оператора SELECT имеет следующий вид:
<SELECT statement> ::=
[WITH <common_table_expression> [,...n]]
<query_expression>
[ ORDER BY { order_by_expression | column_position [ ASC | DESC ] }
[ ,...n ] ]
[ COMPUTE
{ { AVG | COUNT | MAX | MIN | SUM } ( expression ) } [ ,...n ]
[ BY expression [ ,...n ] ]
]
[ <FOR Clause>]
[ OPTION ( <query_hint> [ ,...n ] ) ]
<query_expression> ::=
{ <query_specification> | ( <query_expression> ) }
[ { UNION [ ALL ] | EXCEPT | INTERSECT }
<query_specification> | ( <query_expression> ) [...n ] ]
<query_specification> ::=
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]Оператор SELECT предназначен для выборки строк из БД и позволяет построить выборки из одной или нескольких строк или колонок из одной или нескольких таблиц БД. Мы не будем детально разбирать синтаксис оператора SELECT. Результат выполнения оператора SELECT, т.е. построенная выборка, называется результирующим множеством, или результирующим набором (result set).
Оператор SELECT подробно разбирается в литературных источниках, указанных в списке литературы для этой лекции. Отметим основные предложения этого оператора.
- Предложение SELECT select_list [ INTO new_table ] определяет список имен колонок таблиц БД, представлений или производных полей.
- Предложение FROM table_source определяет список имен таблиц и представлений БД, участвующих в выборке.
- Предложение WHERE search_condition определяет предикат отбора строк в выборку.
- Предложение GROUP BY group_by_expression определяет условия группировки строк в выборке.
- Предложение HAVING search_condition, которое условия поиска на разбиении результирующего множества предложения GROUP BY.
- Предложение ORDER BY order_expression [ ASC | DESC ] определяет правила упорядочивания строк в выборке.
Операторы UNION, EXCEPT и INTERSECT используются для построения комбинации операторов SELECT или сравнения результатов их выполнения в рамках одного результирующего множества.
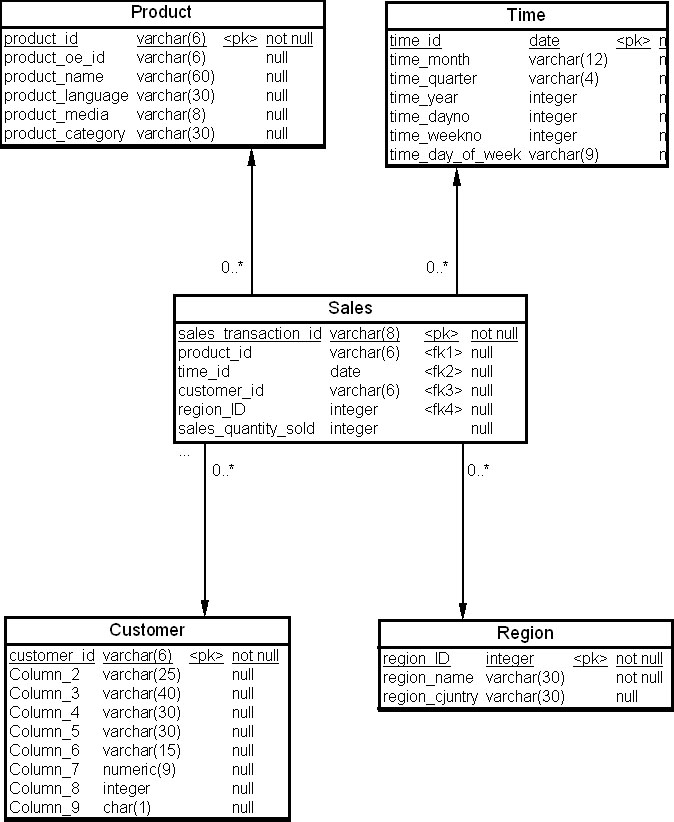
Теперь перейдем к примерам конструирования запросов к схеме типа "звезда". Рассмотрим схему "звезда" ХД, предназначенного для анализа сбыта продукции торговой организации ( рис. 22.1).
ХД предназначено для анализа системы сбыта продукции организации и включает, помимо времени, следующие объекты:
- таблица изменений "Товар" (Product), описание которой приведено в табл. 22.1;
- таблица измерений "Время" (Time), описание которой приведено в табл. 22.2;
- таблица измерений "Покупатель" (Customer), описание которой приведено в табл. 22.3;
- таблица измерения "Регион" (Region), описание которой приведено в табл. 22.4;
- таблица фактов "Данные по продажам" (Sales), описание которой приведено в табл. 22.5.
| Имя поля | Описание |
|---|---|
| product_id | Идентификатор товара |
| product_name | Наименование товара |
| product_category | Категория товара |
| Имя поля | Описание |
|---|---|
| time_id | Идентификатор времени |
| time_month | Месяц |
| time_quarter | Квартал |
| time_year | Год |
| time_dayno | День |
| time_weekno | Неделя |
| time_day_of_week | День недели |
| Имя поля | Описание |
|---|---|
| customer_id | Идентификатор покупателя |
| customer_name | Покупатель |
| customer_address | Адрес |
| customer_city | Город |
| customer_subregion | Район |
| customer_region | Область |
| customer_postalcode | Почтовый индекс |
| customer_age | Возраст |
| customer_gender | Тип покупателя |
| Имя поля | Описание |
|---|---|
| region_id | Идентификатор региона |
| region_name | Наименование региона |
| region_country | Страна |
| Имя поля | Описание |
|---|---|
| sales_transaction_id | Идентификатор транзакции |
| product_id | Идентификатор товара |
| customer_id | Идентификатор покупателя |
| time_id | Идентификатор времени |
| region_id | Идентификатор региона |
| sales_quantity_sold | Количество проданного товара |
| sales_dollar_amount | Цена в долларах проданного товара |
Таким образом, получаем одну таблицу фактов и четыре таблицы измерений. Рассмотрим, как конструируется запрос на SQL к схеме типа "звезда". В типовом запросе к такой схеме указываются детальные сведения о точках этой схемы (т.е. измерение), а затем данные, соответствующие этим точкам, обобщаются.
Рассмотрим пример запроса к схеме, приведенной на рис. 22.1.
Пример 22.1. Пусть требуется просмотреть данные о продажах товара с идентификационным номером 33 за месяцы с мая по август текущего года по региону "Москва" с идентификационным номером 81. Тогда запрос может выглядеть следующим образом:
SELECT SUM(sales_dollar_amount* sales_quantity_sold), time_month, region_name FROM Sales, Time, Region WHERE Sales.region_id = Region.region_id AND Sales.time_id = Time_time_id AND Sales.product_id = 33 AND Sales.region_id = 81 AND Time.time_month BETWEEN 'Май' AND 'Август' AND Time.time_year = 2009 GROUP BY time_month, region_name
Изменяя данные о регионе, месяцах и товаре, при помощи вышеприведенного запроса можно выявить тенденции изменения данных о продажах. Для схемы "звезда" характерно использование односторонних эквисоединений таблиц измерений и таблицы фактов. Таблицы измерений не соединяются друг с другом.
Метрика типа "Объем продаж", рассмотренная в предыдущем примере, является аддитивным фактом. Рассмотрим теперь, как конструировать запросы для полуаддитивных фактов.
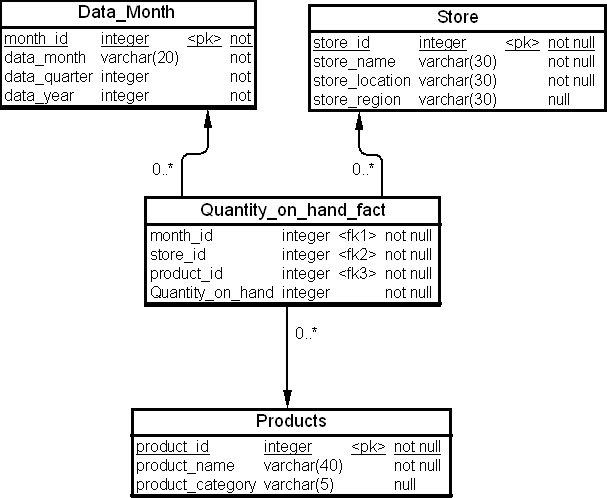
Метрика "Остаток на складе" является типичным примером полуаддитивного факта. Допустим, что в магазине на складе в конце каждого месяца рассчитывается остаток по каждому товару. Рассмотрим схему типа "звезда" на рис. 22.2 для ХД, которое предназначено для анализа движения товаров через магазин.
В схеме представлено три таблицы измерений: "Месяц" (Data_month), "Магазин" (Store), "Товары" (Products) и таблица фактов "Остаток на складе" (Quantity_on_hand_fact). Описание таблиц приведено в табл. 22.6 ниже.
| Имя поля | Описание |
|---|---|
| Таблица измерения "Месяц" (Data_month) | |
| month_id | Идентификатор месяца |
| data_month | Месяц |
| data_quarter | Квартал |
| data_year | Год |
| Таблица измерения "Магазин" (Store) | |
| store_id | Идентификатор магазина |
| store_name | Название магазина |
| store_location | Месторасположение магазина |
| store_region | Регион |
| Таблица измерения "Товары" (Products) | |
| product_id | Идентификатор товара |
| product_name | Название товара |
| product_category | Категория товара |
| Таблица фактов "Остаток на складе" (Quantity_on_hand_fact) | |
| month_id | Идентификатор месяца |
| store_id | Идентификатор магазина |
| product_id | Идентификатор товара |
| Quantity_on_hand | Остаток на складе |
Метрика "Остаток на складе" является аддитивной по измерениям "Товары" (Products) и "Магазин" (Store), но не является аддитивной по измерению "Месяц" (Data_month). Рассмотрим, как можно получить итоговое количество товаров на складе в магазине в любой момент времени, используя измерения, для которых полуаддитивный факт является аддитивным.
Пример 22.2. Пусть нам необходимо просуммировать остатки товара "Подушка" на складе магазинов за январь 2009 года с учетом месторасположения последних, т.е. определить, сколько нереализованных подушек было в сети магазинов торговой организации в январе 2009 года. Сделаем это за счет соединения таблицы фактов с измерением "Магазин", как показано ниже.
SELECT Store.store_location, SUM(Quantity_on_hand_fact.Quantity_on_hand) FROM Store, Quantity_on_hand_fact, Products, Data_month WHERE Store.store_id = Quantity_on_hand_fact.store_id AND Quantity_on_hand_fact.month_id = Data_month.month_id AND Products.product_id = Quantity_on_hand_fact.product_id AND Data_month.data_month = 'Январь' AND Data_month.data_year = 2009 AND Products.product_name ='Подушка' GROUP BY Store.store_location
Аналогично можно суммировать метрику "Остаток на складе" по измерению "Товары", чтобы получать количество нереализованных товаров, сгруппированных по категориям товара.
В примерах, приведенных выше, мы использовали агрегатную функцию SUM() для суммирования и предложение GROUP BY для построения заданного разбиения результирующего множества.
В ХД, как правило, отношение имеет внутреннюю структуру, и при его обработке требуется проводить разбиение отношения на подмножества, обладающие тем или иным значением определенного атрибута. Например, в достаточно общей постановке вопрос можно сформулировать так: протабулировать значение некоторой функции на каждом из этих подмножеств в соответствии с общим значением атрибута.
Предложение GROUP BY определяет, каким образом строить разбиение исходного множества на подмножества в соответствии с заданным критерием. Полученное разбиение представляет исходное отношение как объединение конечного числа непересекающихся подмножеств. В частности, агрегатные функции применяются последовательно к каждому подмножеству в отдельности, а результат функции выводится в результирующем отношении.
Кроме функции SUM(), к агрегатным функциям относятся функции: AVG() – вычисляет среднее значение, MIN() – вычисляет минимальное значение, MAX() – вычисляет максимальное значение, COUNT() – вычисляет количество итемов в результирующем множестве (или элементе разбиения результирующего множества), и ряд других, предусмотренных реализацией SQL в конкретной СУБД.
Предложение GROUP BY ведет себя как проекция с производными колонками. Оно разбивает значения в заданных колонках на подмножества в соответствии со списком колонок группировки. Эти подмножества характеризуются одинаковыми значениями из списка проекции. Затем осуществляется проекция на эти атрибуты, причем при этом вычисляется какая-либо производная колонка и помещается в дополнительную колонку результирующей таблицы.
На использование колонок группировки существуют ограничения. В качестве колонок группировки в данном предложении SELECT можно указывать только колонки из заданного списка, а не любые из таблицы. В конкретных реализациях SQL предусмотрен еще целый ряд ограничений.
Можно задавать условия выборки на результаты выполнения предложения GROUP BY, для того чтобы исключить определенные кортежи из построенного разбиения. Для этого предназначено специальное предложение HAVING, которое задает условие выборки к атрибутам перегруппированного, а не исходного отношения. Основное отличие в действии условия выборки предложения HAVING в сравнении с аналогичным условием выборки предложения WHERE состоит в том, что первое выбирает подмножества из разбиения целиком в зависимости от его агрегируемых свойств, в то время как последнее просматривает содержимое каждого из этих подмножеств построчно, не учитывая полученное разбиение. Иногда наблюдается более быстрое выполнение команды SELECT с использованием предложения HAVING, чем с предложением WHERE.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|
Анатолий Федоров
| Россия, Москва, Московский государственный университет им. М. В. Ломоносова, 1989 |