Принципы проектирования класса
Инкапсуляция и утверждения
До рассмотрения лучших версий несколько комментариев к первой попытке.
Класс LINKED_LIST1 показывает, что даже на совершенно простых структурах манипуляции со ссылками - это некий вид трюков, особенно в сочетании с циклами. Использование утверждений помогает в достижении корректности (смотри процедуру put и инвариант), но явная трудность операций этого типа является сильным аргументом в пользу их инкапсуляции раз и навсегда в повторно используемых модулях, как рекомендуется ОО-подходом.
Обратите внимание на применение Принципа Унифицированного Доступа; хотя count это атрибут и empty это функция, клиентам нет необходимости знать такие детали. Они защищены от возможных последующих изменений в реализации.
Утверждения для put полны, но из-за ограничений языка утверждений они не полностью формальны. Аналогично подробные предусловия следует добавить в другие подпрограммы.
Критика интерфейса класса
Удобно ли использование LINKED_LIST1? Давайте оценим наш проект.
Беспокоящий аспект - существенная избыточность: item и put содержат почти идентичные циклы. Похожий код следует добавить в процедуры, оставленные читателю ( occurrence, replace, remove ). Все же не представляется возможным вынести за скобки общую часть. Не слишком многообещающее начало.
Это внутренняя проблема реализации, - отсутствие повторно используемого внутреннего кода. Но это указывает на более серьезный изъян - плохо спроектированный интерфейс класса.
Рассмотрим процедуру occurrence. Она возвращает индекс элемента, найденного в списке, или 0 в случае его отсутствия. Недостаток ее в том, что она дает только первое вхождение. Что, если клиент захочет получить последующие вхождения? Но есть и более серьезная трудность. Клиент, выполнивший поиск, может захотеть изменить значение найденного элемента или удалить его. Но любая из этих операций требует повторного прохода по списку!
Проектируя компонент библиотеки общецелевого использования, нельзя допустить такую неэффективность. Любые потери производительности в повторно используемых решениях неприемлемы, в противном случае разработчики просто откажутся платить, обрекая на провал идею повторного использования.
Простые, напрашивающиеся решения
Как справиться с неэффективностью? На ум приходят два возможных решения:
- Пусть occurrence возвращает не целое, а ссылку на звено LINKABLE, где впервые появилось искомое значение, или void при неуспешном поиске. Тогда клиент имеет прямой указатель на нужный ему элемент и может выполнить требуемые операции без прохода по списку. (Например, использовать put класса LINKABLE для изменения элемента; при удалении нужна еще ссылка на предыдущий элемент.)
- Можно было бы обеспечить дополнительные примитивы, реализующие различные комбинации: поиск и удаление, поиск и замена.
Первое решение, однако, противоречит всей идее инкапсуляции данных, - клиенты должны манипулировать внутренним представлением, со всеми вытекающими отсюда угрозами. Понятие звена является внутренним, а мы хотим, чтобы программист клиентского модуля думал в терминах списка и его значений, а не в терминах звеньев и указателей. В противном случае теряется смысл абстракции данных.
Второе решение мы пытались реализовать в ранней версии ISE. Для вставки элемента непосредственно перед вхождением известного значения клиент вместо вызова search вызывал:
insert_before_by_value (v: G; v1: G) is
-- Вставка нового элемента со значением v перед первым
-- вхождением элемента со значением v1 или в конец списка,
-- когда нет вхождений
do
...
endЭто решение сохраняет скрытым внутреннее представление, устраняя неэффективность первой версии.
Но вскоре мы осознали, на какой скользкий путь мы встали. Рассмотрим все потенциально полезные варианты: search_and_replace, insert_before_by_value, insert_ after_by_value, insert_after_by_position, insert_after_by_position, delete_before_by_value, insert_at_ end_if_absent и так далее.
Это затрагивает жизненно важные вопросы проектирования библиотек. Написание общецелевого, повторно используемого ПО является трудной задачей, и нет гарантии, что с первого раза все хорошо получится. Конечно, хотелось бы, чтобы проект при его повторных использованиях следовал горизонтальной линии, показанной на рис. 5.6. Но так не бывает, нужно быть готовым добавлять в классы новые компоненты для удовлетворения потребностей, возникающих у новых пользователей. Но этот процесс должен быть сходящимся. К сожалению, наше решение соответствует графику, показанному пунктиром на рис.5.6.

Введение состояния
К счастью, есть выход. Для его нахождения следует обратиться, как и положено, к абстрактному типу данных.
До сих пор список рассматривался как пассивное хранилище информации. Для обеспечения клиентов лучшим сервисом, список должен стать активным, "запоминая" точку выполнения последней операции.
Как отмечалось в этой лекции, без колебаний можно рассматривать объекты как машины с внутренним состоянием и вводить как команды, изменяющие состояние, так и запросы на этом состоянии. В первом решении список уже имел состояние, определяемое его содержимым и модифицируемое командами, такими как put and remove ; но, добавив еще несколько компонентов, мы получим лучший интерфейс, делающий класс более простым и эффективным.
Помимо содержимого списка состояние теперь будет включать текущую активную позицию или курсор, интерфейс теперь будет позволять явным образом передвигать курсор.
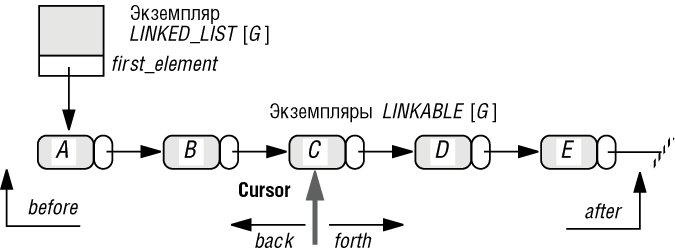
Мы полагаем, что курсор может указывать на элемент списка, если таковые имеются, или быть в позиции слева от первого - в этом случае булев запрос before будет возвращать true, или справа от последнего - тогда after принимает значение true.
Примером команды, передвигающей курсор, является процедура search, заменяющая функцию occurrence. Вызов l.search(v) передвинет курсор к первому элементу со значением v справа от текущей позиции курсора, или передвинет его в позицию after, если таких элементов нет. Заметьте, помимо прочего, это решает проблему множественных вхождений, - просто повторяйте поиск столько раз подряд, сколь это необходимо. Для симметрии можно также иметь search_back.
Основные команды манипулирования курсором:
- start и finish, передвигающие курсор в первую и последнюю позицию, если они определены;
- forth и back, передвигающие курсор в следующую и предыдущую позицию;
- go(i), передвигающие курсор в позицию i.
Кроме before и after запросы о позиции курсора включают index, целочисленный номер позиции, начинающийся с 1 для первой позиции, а также булевы запросы is_first и is_last.
Процедуры построения и модификации списка - вставка, удаление, замена - становятся проще, поскольку они не должны заботиться о позиции, а будут действовать на элемент, заданный курсором. Все циклы исчезают! Например, remove не будет теперь вызываться как l.remove (i), а просто l.remove. Необходимо установить точные и согласованные условия того, что случится с курсором при выполнении каждой операции:
- Remove, без аргументов, удаляет элемент в позиции курсора и перемещает курсор к правому соседу, так что значение index не изменится в результате.
- Put_right (v: G) вставляет элемент со значением v справа от курсора, не передвигая его, так что значение index не изменится.
- Put_left (v: G) вставляет элемент со значением v слева от курсора, не передвигая его, увеличивая значение index на единицу.
- Replace (v: G) изменяет значение элемента в позиции курсора. Значение этого элемента может быть получено функцией item, не имеющей аргументов, которая может быть реализована атрибутом.
Поддержка согласованности: инвариант реализации
При построении класса для фундаментальной структуры данных следует тщательно позаботиться обо всех деталях. Утверждения здесь обязательны. Без них велика вероятность пропуска важных деталей. Например:
- Является ли вызов start допустимым, если список пуст; если да, то каков эффект вызова?
- Что случится с курсором после remove, если курсор был в последней позиции? Неформально мы к этому подготовились, позволяя курсору передвигаться на одну позицию левее и правее списка. Но нам нужны более точные утверждения, недвусмысленно описывающие все случаи.
Ответы на вопросы первого вида будут даны в виде предусловий и постусловий.
Для таких свойств, как допустимые позиции курсора, следует использовать предложения, устанавливающие инвариант реализации. Напомним, он отражает согласованность представления, задающего класс - визави АТД. В данном случае он включает свойство:
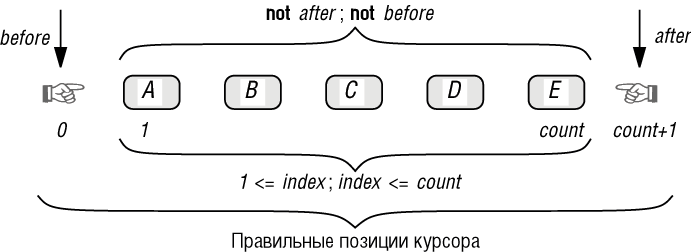
0 <= index; index <= count + 1
Что можно сказать о пустом списке? Необходима симметрия по отношению к левому и правому. Одно решение, принятое в ранних версиях библиотеки, состояло в том, что пустой список это тот единственный случай, когда before и after оба истинны. Это работает, но приводит в алгоритмах к частой проверке тестов в форме: if after and not empty. Это привело нас к концептуальному изменению точки зрения и введению в список двух специальных элементов - стражей (sentinel), изображаемых на рисунке в виде специальных картинок.
Стражи помогают нам разобраться в структуре, но нет причин хранить их в представлении. Реализация рассматривает возможность хранения только левого стража, но не правого, можно также использовать реализацию совсем без стражей, хотя и продолжающую соответствовать концептуальной модели, представленной на предыдущем рисунке.
Часто хочется установить, что некоторый индекс соответствует позиции какого-либо элемента списка. Для этого можно предложить соответствующий запрос:
on_item (i: INTEGER): BOOLEAN is
-- Есть ли элемент в позиции i?
do
Result := ((i >= 1) and (i <= count))
ensure
within_bounds: Result = ((i >= 1) and (i <= count))
no_elements_if_empty: Result implies (not empty)
endДля установления того, что есть элемент списка в позиции курсора, можно определить запрос readable, чье значение определялось бы как on_item (index). Это хороший пример Принципа Списка Требований, поскольку readable концептуально избыточен, то минималистская позиция отвергала бы его, в то же время его включение обеспечивало бы клиентов лучшей абстракцией, освобождая их от необходимости запоминания того, что точно означает индекс на уровне реализации.
Инвариант устанавливает истинность утверждения: not (after and before). В граничном случае пустого списка картина выглядит так:
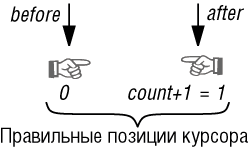
Итак, пустой список имеет два возможных состояния: empty and before и empty and after, соответствующие двум позициям курсора на рисунке. Это кажется странным, но не имеет неприятных последствий и на практике предпочтительнее прежнего соглашения empty = (before and after), сохраняя справедливость empty implies (before or after).
Отметим два общих урока: важность, как во многих математических и физических задачах, проверки граничных случаев, важность утверждений, выражающих точные свойства проекта. Вот некоторые принципиальные предложения, включенные в инвариант:
0 <= index; index <= count + 1
before = (index = 0); after = (index = count + 1)
is_first = ((not empty) and (index = 1));
is_last = ((not empty) and (index = count))
empty = (count = 0)
-- Три следующих предложения являются теоремами,
-- выводимыми из предыдущих утверждений:
empty implies (before or after)
not (before and after)
empty implies ((not is_first) and (not is_last))Этот пример иллюстрирует общее наблюдение, что написание инварианта - лучший способ придти к настоящему пониманию особенностей класса. Утверждения инварианта применимы ко всем реализациям последовательных списков, они будут дополнены еще несколькими, отражающими специфику выбора связного представления.
Последние три предложения инварианта выводимы из предыдущих (см. У5.6). Для инвариантов минимализм не требуется, часто полезно включать дополнительные предложения, если они устанавливают важные, нетривиальные свойства. Как мы видели (см. лекцию 6 курса "Основы объектно-ориентированного программирования"), АТД и, как следствие, реализация класса является теорией, в данном случае теорией связных списков. Утверждения инварианта выражают аксиомы теории, но любая полезная теория имеет также и интересные теоремы.