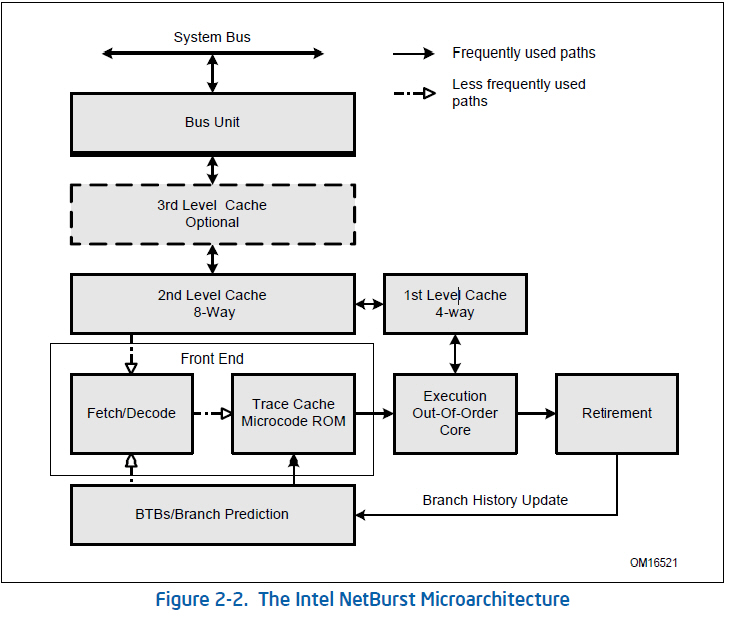
Архитектура микропроцессора Intel и основные факторы, влияющие на его производительность
Качество предсказания переходов
Инструкции могут быть зависимыми по данным и по управляющей логике программы. (Data dependence and control flow dependence).
Эффективность суперскалярных и конвейерных механизмов во многом ограничивается различными условными переходами внутри программы.
Существует специальный механизм предсказания переходов (branch prediction).
МПП выбирает один из возможных путей и продолжает выбирать инструкции и нагружать конвейеры МП работой. В момент, когда условие перехода вычислено, определяется, не ошибся ли предсказатель.
Ошибка предсказателя (branch misprediction) - все уже выполненные или еще находящиеся в обработке инструкции удаляются, и МП заново заполняет конвейеры.
Можно выделить статический и динамический предсказатель.
Динамический предсказатель отличается тем, что собирает статистику на каждое ветвление и делает предсказание на основании собранной статистики.
Тривиальное предсказание – переход не будет выполнен в случае если осуществляется переход вперед и будет выполнен – если происходит переход назад.
Существует также механизм предсказания цели ветвления (branch target prediction), который предсказывает безусловные переходы.
Качество предсказания переходов.
В программе есть некая управляющая логика, и эта логика включает в себя различные переходы внутри кода. Если встречаются if’ы и на основании вычисления какого-то условия принимается решение, какую выполнять инструкцию дальше? Как быть с загрузкой конвейера, в случае если встречается зависимость по управляющей логике? Можно остановить конвейер и ждать, пока вычислится условие перехода и после этого определить, какую инструкцию выполнять дальше и загружать ее на конвейер. Понятно, что в этом случае произойдет замедление работы конвейера, поэтому выбран другой метод. Процессор пытается предсказать по какому-то пути будет передаваться управление и продолжает выполнять инструкции с этого направления. Причем пока процессор не убедится, что выполняются правильные инструкции, они недействительны . Как только процессор убеждается, что путь угадан верно, все инструкции признаются правильными. Если предсказатель ошибся и реальное управление пошло по другому пути, недействительные инструкции удаляются из буферов, где они ожидали своей судьбы. Это приводит к некой задержке, приходится тратить время на то, чтобы инструкции удалять и загружать правильные инструкции на конвейер. Ошибка предсказателя (branch misprediction) вызывает замедление работы конвейера.
В процессоре есть статический и динамический предсказатель.
Статический предсказатель действует по простым правилам и принимает решения для тех переходов для которых нет собранной статистики.
Если встречается условный переход вперед, то статический предсказатель считает, что перехода не будет (в случае с оператором if управление пойдет по ветке if а не else).
В том случае, если у нас будет переход назад, то этот переход будет выполнен. Это сделано для лучшей обработки циклов. Обычно циклы имеют более двух итераций, и эта схема лучше работает.
При выполнении перехода накапливается статистика, которую при последующих исполнениях данного перехода будет использовать динамический предсказатель.
Если у вас внутри цикла постоянно встречается if (и этот if хорошо предсказуемый), то начиная со второй-третьей итерации процессор будет четко угадывать правильное направление и задержки мы не получим. Если переход плохо предсказуемый, то будет много неугадываний и производительность цикла понизится.
Одна из целей vtun’а — это определение таких событий, как неверное угадывание перехода, например. Вы можете этим устройством проанализировать ваше приложение и увидеть, что в определенном месте вашего кода есть плохо предсказуемый переход или цепочка переходов влияющих на производительность. Зачастую такие проблемы могут быть решены творческим модифицированием кода.
Существуют разные проблемы. Проблема с КЭШем, например. Если у вас идет неугадывание по КЭШу, и вы не можете вовремя получить из памяти какие-то адреса, то эта проблема заслонит ту проблему, что вы не можете правильно определить цель ветвления, потому что процессор будет простаивать много времени по другой причине.
Суперскалярность
Суперскалярный процессор – процессор, способный выполнять несколько операций за один такт.
Как следствие, для такого типа процессора обязательно наличие нескольких исполнительных блоков (execution unit).
Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств.
Pentium - первый суперскалярный процессор архитектуры x86.
Выигрыш от суперскалярности определяется уровнем параллелизма инструкций.
"Разнообразие" поступающих на конвейер инструкций позволяет более полно нагружать исполняемые устройства.
Суперскалярность.
Теперь обсудим суперскалярность. Мы рассуждали о командном управляющем устройстве и об арифметико-логических устройствах. Суперскалярность — это процессор, который имеет несколько исполняющих устройств, то есть одновременно он может выполнять несколько арифметических и логических операций. Мы обсуждали конвейер, где обрабатывались инструкции, и была часть конвейера, которая выполняла операцию и называлась "исполняющее устройство", где непосредственно делалась основная работа, для которой эта инструкция была написана. Суперскалярность означает, что построен конвейер имеющий несколько исполняющих устройств и одновременно может исполняться несколько различных команд. Исполняющие устройства специфицированы, они не могут исполнить любую инструкцию, у них у каждого своя должность (один выполняет одни виды команд, другой – другие и так далее). То есть у нас появилась возможность выполнять одновременно несколько инструкций на этих исполняющих устройствах. Например до 6 инструкций на микропроцессорах семейства IA32 последних моделей.
Первым суперскалярным процессором интеловской архитектуры был Pentium, и в нем было реализовано исполняемое устройство U и исполняемое устройство V. Одно умело делать все операции, а второе — самые простенькие, например, инкрементирование.
Разнообразие поступающих на конвейер инструкций позволяет процессору полнее загружать работой конвейер. Если у вас все инструкции однотипные, то спектр всех этих исполняющих устройств не будет задействован и они будут простаивать.
Упрощенная модель процессора
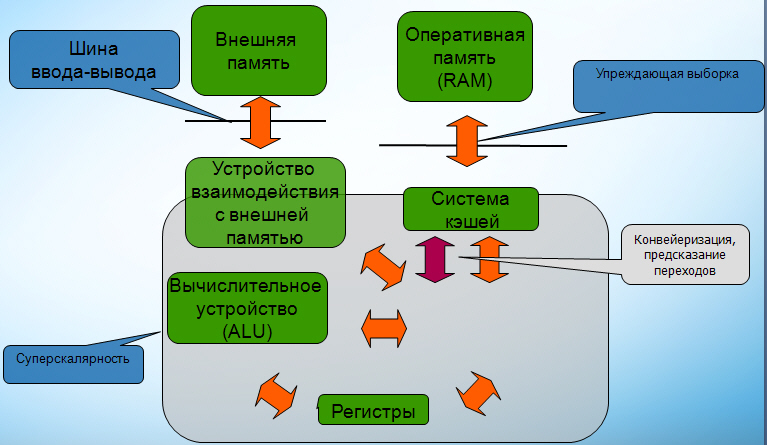
Теперь мы берем и изменяем несколько упрощенную модель нашего микропроцессора, чтобы схематично отобразить на ней те свойства, которые мы только что обсуждали. На системной шине работает упреждающая выборка, которая из памяти подгружает данные в систему КЭШа, базируясь на логике железного предсказателя. Отображаем систему КЭШей. В микропроцессоре будет работать конвейер и предсказатель переходов, то есть управляющее устройство будет брать не только те инструкции, которые оно в данный момент собирается выполнять, а также те, которые ему рекомендует брать предсказатель переходов (чтобы конвейер более плотно нагружать). Регистров увеличенное количество, ну и суперскалярность, которую мы можем отобразить как наличие нескольких вычислительно-логических устройств.
Использование векторных инструкций, векторизация
Типичная векторная инструкция выполняет элементарную операцию над двумя векторными последовательностями в памяти или векторными регистрами фиксированной длины.

Векторизация – процесс конвертации компьютерной программы из скалярного представления, в котором одна операция выполняется над парой операндов, в векторное представление, в котором одна операция выполняется над парой векторных операндов.
В Pentium III новая технология SSE (Streaming SIMD Extensions), которая добавила в МП 8 128-битных регистров (XMM0-XMM7) и 70 новых инструкций в том числе для работы с вещественными числами. SSE2,SSE3,SSEE3,SSE4,SSE4.2,AVX – последующие расширения этой идеи.
Конвейеризация, суперскалярность — это некие варианты параллелизации. Они несколько разные по их специфике, но в целом приводят к тому, что мы одновременно работаем с несколькими инструкциями.
Третий вариант параллелизации — параллелизация по данным, векторизация. Типичная векторная инструкция выполняет элементарную операцию над двумя векторными последовательностями в памяти или векторными регистрами фиксированной длины. Ее можно трактовать двояко, с одной стороны это поддержка на уровне микропроцессора векторных регистров и операций с ними, с другой стороны это некая оптимизация, позволяющая обычный скалярный код преобразовывать в векторный код. Т.е. в отличии от обсуждаемых ранее особенностей микропроцессора, эта технология не будет работать по умолчанию, если не будут предприняты какие-либо действия разработчиками запускаемого приложения. Сам микропроцессор на данном этапе векторизовать код не умеет.
Векторизация — это некая технология, когда вы можете ваш скалярный код (то есть код, который работает с какими-то скалярными элементами, допустим, элементами массива) превратить в векторный код, который будет оперировать уже не элементами массива, а секциями массива, будет делать операции не над одним элементом из массива а, соответственно, над вектором элементов. Вы можете делать векторизацию либо руками, либо поручить эту работу компилятору, и он вашу скалярную программу преобразует в векторный вид. В данной лекции, перечисляя факторы влияющие на производительность, я просто хочу подчеркнуть, что использование при рассчетах векторных инструкций способно серьезно ускорить работу микропроцессора.
Процессор поддерживает разные наборы векторных инструкций: SSE2, SSE3 и так далее. Обсуждая полноту набора инструкций мы уже затронули вопрос, что приложение будет работать оптимальнее на архитектуре, если при создании приложения вы будете специально создавать его для работы на данной архитектуре. Это верно и в случае с векторными инструкциями.
Опережающий просмотр потока инструкций
Для того, чтобы эффективно использовать несколько АЛУ и конвейер, современные микропроцессоры используют опережающий просмотр потока инструкций. Это позволяет определить те инструкции, которые могут вычисляться параллельно.
Также возможно исполнение с изменением последовательности операций (out-of-order execution).
Но технологии опережающего просмотра инструкций (lookahead) не могут решить проблему простоя АЛУ и конвейера в случае низкого уровня инструкционного параллелизма.
Out-of-order execution – одно из определяющих свойств архитектуры x86. Реализация этого механизма усложняет процессор. В качестве противоположного примера от Интел можно упомянуть архитектуры Itanium и Atom. На этих архитектурах инструкции выполняются в порядке, заданном приложением.
Ранее я описал некоторые особенности характерные для работы конвейера микропроцессора. Можно считать, что перед загрузкой инструкций на конвейер, они ожидают в неком буфере. И есть процессорные механизмы для того, чтобы подходящие инструкции выбирать и посылать на выполнение. То есть существуют процессорные механизмы для опережающего просмотра потока инструкций и определения тех инструкций, которые в данный момент выгодно загружать на конвейер. И вот если в этом буфере есть возможность выбрать много независимых инструкций — это позволяет более полно загрузить конвейер. А если в буфере много зависимых инструкций, то этот механизм может не справиться и будут случаи когда конвейер частично будет простаивать.
Т.е. в микроархитектурах семейства IA32 реализовано исполнение с изменением последовательности операций (out-of-order-execution). То есть программисты написали какие-то инструкции, подали их на процессор, а он сам выбрал, в каком порядке их выполнять. В данном случае важная часть работы – планирование инструкций выполняется непосредственно микропроцессором.
Это не единственный возможный вариант работы микропроцессора. Есть микропроцессор Intel Atom, предназначенный для различных планшетных устройств, который последовательно выполняет получаемые микроинструкции, или например, процессор Itanium, в котором в процессор поступают инструкции уже объединенные в группы. То есть работа по определению того, какие инструкции независимы и в каком порядке их подавать процессору переложена на компилятор. В этом случае работа по определению оптимального порядка инструкций выполняется один раз — во время компиляции. Это должно быть выгодно с точки зрения энергопотребления.
Если кто-то хочет более подробно с этим всем ознакомиться, я отсылаю к инструкциям, к документации от Интел. Вы можете скачать документацию и после этого сидеть и перед сном ее почитывать. Документация содержит много схем, объясняющих более подробно работу микропроцессора и взаимодействия между различными компонентами процессора. Пример, который показывает спецификацию исполняемых устройств. То есть существует внутри конвейера некий распределитель, который поступающие инструкции распределяет на то или иное подходящее исполняющее устройство.