Языки программирования
3.2. Компиляция против интерпретации
В оставшейся части лекции анализируется инструментарий, поддерживающий разработку ПО. Программы не пишутся в машинном коде – в форме, доступной для непосредственного выполнения компьютером, они создаются на языке высокого уровня – языке программирования, ориентированном на человека. Конечно, язык программирования также можно рассматривать как машинный код некоторого абстрактного компьютера, отличающегося от реальных процессоров. Мы будем говорить в таких случаях об абстрактных или виртуальных машинах.
Целью компиляции является реализация возможности выполнения реальным компьютером кода, написанного для абстрактной машины. Компиляция, однако, – лишь одна из двух базисных технологий, применяемых для достижения нашей цели.
Базисные схемы
Вместо компиляции программы можно ее интерпретировать. Рисунок ниже иллюстрирует разницу подходов, игнорируя роль входных данных.
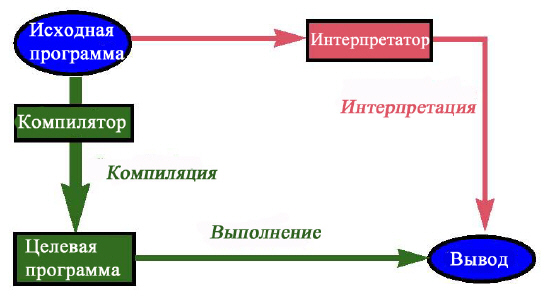
И компилятор, и интерпретатор являются программами, на вход которых подаются программы, написанные на языке программирования. Компилятор транслирует переданную ему программу в целевую форму – машинный код, который уже может быть непосредственно выполнен на компьютере, создавая выходные результаты вычислений. Обработка той же исходной программы интерпретатором не создает целевой программы, но непосредственно выполняет ее, получая выходные результаты.
Интерпретатор должен быть способен определить эффект выполнения каждой конструкции языка программирования. Как пример того, как интерпретатор выполняет свою задачу, рассмотрим интерпретацию присваивания x: = x +1. Интерпретатор должен хранить таблицу всех используемых переменных и связанных с ними значений. Он вычисляет новое значение x, добавляя 1 к старому значению, хранящемуся в таблице, а затем выполняет присваивание, заменяя старое значение x значением вычисленного выражения.
Компилятор будет генерировать машинный код, создающий тот же эффект, используя команды компьютера и адреса памяти (а не структуру более высокого уровня, такую как таблица).
Если рассматривать язык программирования как машинный код для абстрактной машины, можно сказать, что интерпретатор – это программа, моделирующая вычисление на этой машине. Машинная память в этом случае также абстрактна и представляет структуры данных в виде таблиц интерпретатора "переменные – значения".
На следующем рисунке процессы компиляции и интерпретации дополнены вводом данных:
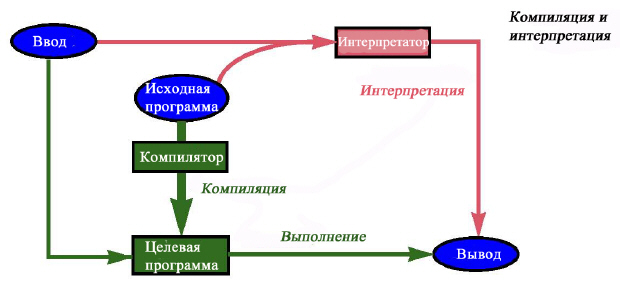
Рисунок демонстрирует еще одну разницу между компилятором и интерпретатором. У интерпретатора два источника ввода – исходная программа и входные данные; а компилятору подается только программа. В последующем обсуждении этому различию придадим математическую форму.
Компилировать или интерпретировать? Эта проблема – предмет широко рассмотрения в компьютерных науках. Что лучше: непосредственно обрабатывать исходную информацию в том виде, как она есть, или предварительно привести ее к более удобной форме? Этот вопрос стоит не только при обработке программ, мы будем сталкиваться с ним и при изучении алгоритмов.
У компиляторов и интерпретаторов имеются свои достоинства. Возможны различные критерии. По производительности – времени выполнения программы – компиляторы побеждают.
- Выход компилятора является машинным кодом, непосредственно выполняемым компьютером. Дополнительно при создании этого кода компилятор мог применять оптимизацию, улучшающую эффективность кода.
- Интерпретация кода требует при выполнении каждого оператора его предварительной обработки. В результате интерпретация программы выполняется на порядок медленнее в сравнении с работой программы, созданной компилятором.
Все меняется, если в качестве критерия выбрать удобство и скорость разработки. Компилятор стоит между вами и реализацией вашей последней идеи: прежде чем увидеть результаты последнего изменения в программе, необходимо ждать результата компиляции (и связывания, о чем ниже пойдет речь). При интерпретации выполнение начинается незамедлительно.
Еще один критерий, согласно которому предпочтение опять-таки отдается компиляции, состоит в надежности программы. Компиляторы не просто транслируют программу – в процессе компиляции они осуществляют различные проверки, например, контроль типов для статически типизированных языков. Тем самым многие ошибки устраняются еще на этапе компиляции, в то время как для режима интерпретации ошибки обнаруживаются в процессе выполнения на одном из сеансов работы.
В принципе, интерпретатор также способен выполнять некоторые из проверок перед выполнением программы. Фактически, чистые интерпретаторы не применяются, они представляют собой всегда некоторую смесь компиляции и интерпретации.
Комбинирование компиляции и интерпретации
Схемы чистой компиляции и чистой интерпретации являются предельными вариантами: большинство практических решений является смесью. Это верно и для процесса компиляции в EiffelStudio, который будет рассмотрен позже в этой лекции.
Заметим, что 100% схема интерпретации имеет мало смысла: каждый раз, когда интерпретатор выполнял очередной оператор, например, оператор цикла, он должен был бы возвращаться многократно к фактической последовательности символов и осуществлять ее разбор. Любое реалистическое решение не могло бы согласиться с такой неразумной тратой ресурсов. Так что фактически интерпретатор также начинает с преобразования входа в форму, приемлемую для интерпретации, например, строя абстрактное синтаксическое дерево. В ходе этого процесса, как отмечалось, возможен контроль проверки типов. Так что даже тогда, когда можно прочесть, что используется интерпретатор языка, частичная компиляция подразумевается.
Комбинирование интерпретации и компиляции идет значительно дальше рассмотренной основной идеи. Выход компилятора не должен быть непосредственным машинным кодом, он может быть субъектом дальнейшего процесса обработки.
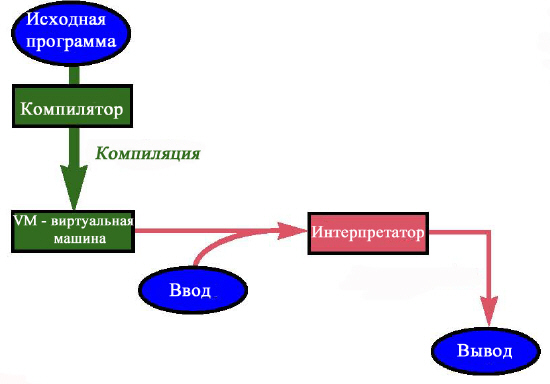
Смешанная стратегия предполагает, что компилятор создает код на промежуточном языке, понимаемом некоторой виртуальной машиной – VM на рисунке. Такой подход объединяет преимущества компиляции и интерпретации. Благодаря тщательно спроектированной виртуальной машине возможно получить:
- переносимость, так как VM-код не зависит от специфики физических процессоров;
- повышение эффективности, поскольку создаваемый промежуточный код легко интерпретируется.
Виртуальные машины, байт-код и JIT (Just In Time) компиляторы
Реализация современных языков – Java, C#, других языков .Net – основана на смешанном решении. Промежуточный код для Java называется байт-кодом. В термине отражается тот факт, что виртуальная машина использует компактные команды, подобные командам фактического процессора, где каждая команда содержит код команды – типично задаваемый одним байтом, – после которого следует 0, 1 или 2 аргумента команды.
Прием двухэтапной компиляции был использован еще в семидесятые годы при реализации компилятора с языка Паскаль. Он получил второе рождение с распространением Интернета, так как хорошо был приспособлен для локального выполнения Web-клиентами. Поставщики апплетов – небольших программ – могли компилировать их в байт-код и поставлять их в такой форме. Дополнительным преимуществом к компактности стала переносимость кода, поскольку в противном случае машинный код пришлось бы создавать для каждой возможной целевой платформы.
Для выполнения апплета пользователям необходим только интерпретатор байт-кода. Они даже не должны знать, что такой интерпретатор существует, если он встроен в их Web-браузер, Поскольку при таком подходе возникают потенциальные риски, связанные с безопасностью, – жульнические или некорректные апплеты могут повредить ваш компьютер, – по этой причине для апплетов необходим интепретатор, который будет строго контролировать операции, разрешенные для апплетов.
Для улучшения эффективности времени выполнения байт-кода применяются JIT (Just In Time) компиляторы, называемые джитерами, – осуществляющие компиляцию по требованию. Основная идея состоит в том, что машинный код для некоторого модуля создается "на лету", в тот момент, когда он первый раз вызывается на выполнение (не следует путать любителя джаза –jitterbug, с ошибками такого компилятора – jitter bug). Внесем соответствующие дополнения в предыдущий рисунок, который теперь выглядит так:
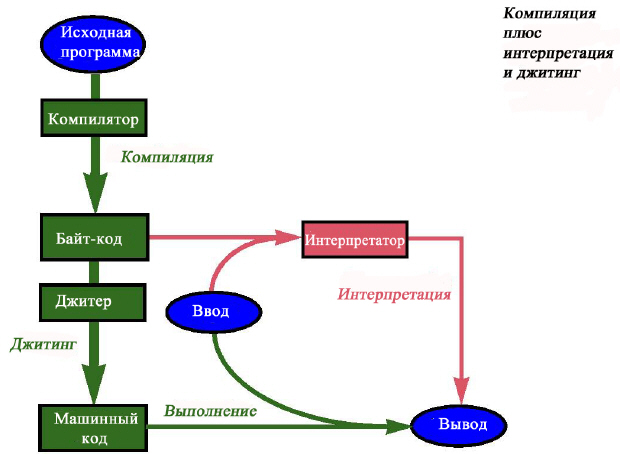
Обычно, как показано на рисунке, наряду с компиляцией "на лету" (джитингом) остается и возможность интерпретации байт-кода. Компиляция "на лету" обычно имеет место при первом использовании модуля (метода или всего класса), так что она будет нужна только для кода, фактически используемого в этом сеансе выполнения. В сравнении с традиционным компилятором, который компилирует всю программу, такой подход позволяет создавать более компактный код, сокращает время компиляции, но, что более важно, делает компиляцию частью процесса выполнения. Последнее является серьезным недостатком, поскольку к времени выполнения добавляются расходы на компиляцию, так что само время выполнения становится менее предсказуемым.
С первого взгляда кажется, что при таком подходе не стоит выполнять проверки типов и другой контроль, поскольку кому же хочется во время выполнения получать сообщения о нарушении согласованности типов? Это возвращало бы нас к проблемам динамически типизированных языков. Конечно, нам хотелось бы, чтобы все необходимые проверки выполнялись на первом шаге компиляции при создании байт-кода, так, чтобы любой код, передаваемый джитеру, был безопасным. К сожалению, эти утешительные предположения нереалистичны в распределенной среде, где опять возникают проблемы безопасности. Если вы загружаете байт-код из сайта, то можете ли вы знать, прошел ли он проверку? В общем случае – нет. Но тогда нарушения типа могут стать не только причиной нарушения надежности и аварийного завершения программы, все может быть гораздо хуже: в результате атаки становится возможным нарушение безопасности.
Как следствие, на практике компиляция на лету включает в любом случае проверку согласованности типов. Потери производительности при этом могут оставаться приемлемыми, поскольку система типов виртуальной машины с байт-кодом значительно проще, как правило, чем система типов исходной программы.
Стратегия компиляции в EiffelStudio также включает байт-код, но, как мы увидим, она использует различные способы комбинирования интерпретации и компиляции.