|
"Сокрытие деталей реализации называется инкапсуляцией (от слова "капсула"). " Сколько можно объяснять?! ИНКАПСУЛЯЦИЯ НЕ РАВНА СОКРЫТИЮ!!! Инкапсуляция это парадигма ООП, которая ОБЕСПЕЧИВАЕТ СОКРЫТИЕ!!! НО СОКРЫТИЕМ НЕ ЯВЛЯЕТСЯ!!! Если буровая коронка обеспечивает разрушение породы, то является ли она сама разрушением породы? Конечно нет! |
Опубликован: 15.09.2010 | Доступ: свободный | Студентов: 5578 / 969 | Оценка: 3.97 / 3.80 | Длительность: 14:45:00
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 9:
Интерфейсы. Контейнерные классы
Контейнерные классы
Абстрактные структуры данных
Любая программа предназначена для обработки данных, от способа организации которых зависит ее алгоритм. Для разных задач необходимы различные способы хранения и обработки данных, поэтому выбор структур данных должен предшествовать созданию алгоритмов и основываться на требованиях к функциональности и быстродействию программы. Наиболее часто в программах используются массив, список, стек, очередь, бинарное дерево, хеш-таблица, граф и множество. Далее дана краткая характеристика каждой из этих структур данных.
Массив — это конечная совокупность однотипных величин. Массив занимает непрерывную область памяти и предоставляет прямой (произвольный) доступ к своим элементам по индексу. Память под массив выделяется до начала работы с ним и впоследствии не изменяется.
В списке каждый элемент связан со следующим и, возможно, с предыдущим. В первом случае список называется односвязным, во втором — двусвязным. Если последний элемент связать указателем с первым, получится кольцевой список. Количество элементов в списке может изменяться в процессе работы программы.
Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью данных, хранящихся в каждом элементе списка. В качестве ключа в процессе работы со списком могут выступать разные части данных. Например, если создается список из записей, содержащих фамилию, год рождения и стаж работы, любая часть записи может выступать в качестве ключа: при упорядочивании списка по алфавиту ключом будет фамилия, а при поиске, например, ветеранов труда ключом можно сделать стаж. Ключи разных элементов списка могут совпадать.
Над списками можно выполнять операции добавления, удаления и вставки элемента, чтения элемента с заданным ключом, упорядочивания списка по ключу (ключам). Список не обеспечивает произвольный доступ к элементу, поэтому при выполнении операций чтения, вставки и удаления выполняется последовательный перебор элементов, пока не будет найден элемент с заданным ключом.
Стек — частный случай однонаправленного списка, добавление элементов в который и выборка из которого выполняются с одного конца, называемого вершиной стека. Другие операции со стеком не определены. При выборке элемент исключается из стека. Говорят, что стек реализует принцип обслуживания LIFO (Last In — First Out, последним пришел — первым ушел).
Очередь — частный случай однонаправленного списка, добавление элементов в который выполняется в один конец, а выборка — из другого конца. Другие операции с очередью не определены. При выборке элемент исключается из очереди. Говорят, что очередь реализует принцип обслуживания FIFO (First In — First Out, первым пришел — первым ушел).
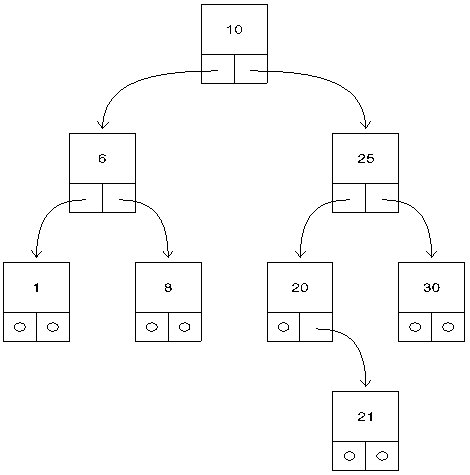
Бинарное дерево — динамическая структура данных, состоящая из узлов, каждый из которых содержит, помимо данных, не более двух ссылок на различные бинарные поддеревья. На каждый узел имеется ровно одна ссылка. Начальный узел называется корнем дерева. Пример бинарного дерева приведен на рис. 9.1 (корень обычно изображается сверху). Узел, не имеющий поддеревьев, называется листом. Исходящие узлы называются предками, входящие — потомками. Высота дерева определяется количеством уровней, на которых располагаются его узлы.
Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева — больше, оно называется деревом поиска. Одинаковые ключи не допускаются. В дереве поиска можно найти элемент по ключу, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа в каждом узле. Такой поиск гораздо эффективнее поиска по списку, поскольку время поиска определяется высотой дерева, а она пропорциональна двоичному логарифму количества узлов.
Хеш-таблица, ассоциативный массив, или словарь — это массив, доступ к элементам которого осуществляется не по номеру, а по некоторому ключу. Можно сказать, что это таблица, состоящая из пар "ключ-значение" (табл. 9.1). Хеш-таблица эффективно реализует операцию поиска значения по ключу. При этом ключ преобразуется в число ( хэш-код ), которое используется для быстрого нахождения нужного значения в хеш-таблице.
Преобразование выполняется с помощью хэш-функции, или функции расстановки. Эта функция обычно производит какие-либо преобразования внутреннего представления ключа. Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов массива, то доступ к элементу по ключу выполняется почти так же быстро, как в массиве.
Смысл хэш-функции состоит в том, чтоб отобразить более широкое множество ключей в более узкое множество индексов. При этом неизбежно возникают так называемые коллизии, когда хеш-функция формирует для двух разных элементов один и тот же хэш-код. В разных реализациях хэш-таблиц используются различные стратегии борьбы с коллизиями.
Граф — это совокупность узлов и ребер, соединяющих различные узлы. Например, можно представить себе карту автомобильных дорог как граф с городами в качестве узлов и шоссе между городами в качестве ребер. Множество реальных практических задач можно описать в терминах графов, что делает их структурой данных, часто используемой при написании программ.
Множество — это неупорядоченная совокупность элементов. Для множеств определены операции проверки принадлежности элемента множеству, включения и исключения элемента, а также объединения, пересечения и вычитания множеств.
Описанные структуры данных называются абстрактными, поскольку в них не задается реализация допустимых операций.
В библиотеках большинства современных объектно-ориентированных языков программирования представлены стандартные классы, реализующие основные абстрактные структуры данных. Такие классы называются коллекциями, или контейнерами. Для каждого типа коллекции определены методы работы с ее элементами, не зависящие от конкретного типа хранимых данных, поэтому один и тот же вид коллекции можно использовать для хранения данных различных типов. Использование коллекций позволяет сократить сроки разработки программ и повысить их надежность. Изучение возможностей стандартных коллекций и их грамотное применение является необходимым условием создания эффективных и профессиональных программ.
Внимание
Каждый вид коллекции поддерживает свой набор операций над данными, и быстродействие этих операций может быть разным. Выбор вида коллекции зависит от того, что требуется делать с данными в программе и какие требования предъявляются к ее быстродействию. Например, при необходимости часто вставлять и удалять элементы из середины последовательности следует использовать список, а если включение элементов выполняется в конец последовательности — очередь.
В библиотеке .NET определено множество стандартных классов, реализующих большинство перечисленных ранее абстрактных структур данных. Основные пространства имен, в которых описаны эти классы — System.Collections, System.Collections.Specialized и System.Collections.Generic (начиная с версии 2.0).
Пространство имен System.Collections
В пространстве имен System.Collections определены наборы стандартных коллекций и интерфейсов, которые реализованы в этих коллекциях. В таблице 9.2 приведены наиболее важные интерфейсы, часть из которых уже изучались в разделе "Стандартные интерфейсы .NET".
В таблице 9.3 перечислены основные коллекции, определенные в пространстве System.Collections.
Пространство имен System.Collections.Specialized включает специализированные коллекции, например, коллекцию строк StringCollection и хэш-таблицу со строковыми ключами StringDictionary.
В качестве примера стандартной коллекции рассмотрим класс ArrayList.
Георгий Кузнецов