Алтайский государственный университет
Опубликован: 12.07.2010 | Доступ: свободный | Студентов: 1469 / 391 | Оценка: 4.02 / 3.93 | Длительность: 16:32:00
ISBN: 978-5-9963-0349-6
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 4:
Многоядерные процессоры с низким энергопотреблением
Файл fourier2_.vf
Код:
\ -- hh hl \ - вычисляем Фурье спектр на основе Хартли отсчетов $3fff0 # ~u/mod \ -- r q ( -- r hv ) in_ # b! @b \ -- hv h(N-v) dup M* push push \ -- hv ; r: -- f2h f2l; dup M* pop pop D+ '-d-- # b! @b \ останов ядра
При таком подходе оперативная память ядер вычисляющих и H(v) и Фр(v) загружена на 80%. Дамп памяти одного из ядер приведен ниже.
Код:
RAM Node 12 000 01000 --- 001 014E8 002 016A1 003 014E8 004 01000 005 008A9 006 00000 007 3F757 008 3F000 }коэффициенты 009 3EB18 00A 3E95F 00B 3EB18 00C 3F000 00D 3F757 00E 00000 00F 008A9 --- : M* 010 134CA call CA * 011 308EA 2/ push drop . 012 26E12 pop a@ @p+ . 013 20000 014 39555 xor ; : D+ 015 2EA9A push a! pop . 016 3C88A + push a@ . 017 3CC55 + pop ; 018 04D97 @p+ dup dup @p+ -----------------------+ 019 00000 01A 0000F 01B 2E9B2 push . . . 01C 24DE3 dup dup xor dup 01D 2C1EF . + drop @p+ 01E 00175 01F 29F97 b! @b dup @p+ 020 001D5 вычисление H(v) 021 29BBA b! !b push . 022 2BC9A a! @a+ pop . 023 228B2 a@ push . . 024 13410 call 10 M* 025 13415 call 15 D+ 026 2701C pop next 1C 027 3BDB2 drop @p+ . . ----------------------------+ 028 3FFF0 029 136AE call 2AE ~u/mod 02A 04B03 @p+ b! @b dup 02B 00145 02C 13410 call 10 M* 02D 2E892 push push dup . вычисление Фр(v) 02E 13410 call 10 M* 02F 26CB2 pop pop . . 030 13415 call 15 D+ 031 04B00 @p+ b! @b + 032 00115 -----------------------------+ 033 034 035 036 037 038 039 03A 03B 03C 03D 03E 03F
Временные параметры вычислений следующие:
- вычисление коэффициента Хартли спектра ~ 3110 тактов;
- вычисление Фурье ~ 380 тактов;
- общее время выполнения ~ 3490 тактов.
Скорость преобразования упала до 200000 преобразований в секунду.
Вычисление быстрого преобразования Хартли
Введение
Алгоритмы быстрого преобразования Хартли [19] строятся приблизительно на тех же принципах, что и преобразования Фурье. Многоточечные преобразования также строятся на основе 2-, 3- или 4-точечных преобразований, т.н. <бабочек>.
16-ти точечное БПХ
Для примера рассмотрим 16-точечное быстрое преобразование Хартли.
Преобразование входной последовательности f(t) начинается с ее перестановки в двоично-инверсном порядке. f(t)>F(0,t). Далее элементы последовательности подвергаются трем этапам преобразований.
1й этап F(0,0)+F(0,1)->F(1,0) F(0,0)-F(0,1)->F(1,1) F(0,2)+F(0,3)->F(1,2) F(0,2)-F(0,3)->F(1,3) F(0,4)+F(0,5)->F(1,4) F(0,4)-F(0,5)->F(1,5) F(0,6)+F(0,7)->F(1,6) F(0,6)-F(0,7)->F(1,7) F(0,8)+F(0,9)->F(1,8) F(0,8)-F(0,9)->F(1,9) F(0,10)+F(0,11)->F(1,10) F(0,10)-F(0,11)->F(1,11) F(0,12)+F(0,13)->F(1,12) F(0,12)-F(0,13)->F(1,13) F(0,14)+F(0,15)->F(1,14) F(0,14)-F(0,15)->F(1,15) 2й этап F(1,0)+F(1,1)->F(2,0) F(1,2)+F(1,3)->F(2,1) F(1,0)-F(1,1)->F(2,2) F(1,2)-F(1,3)->F(2,3) F(1,4)+F(1,5)->F(2,4) F(1,6)+F(1,7)->F(2,5) F(1,4)-F(1,5)->F(2,6) F(1,6)-F(1,7)->F(2,7) F(1,8)+F(1,9)->F(2,8) F(1,10)+F(1,11)->F(2,9) F(1,8)-F(1,9)->F(2,10) F(1,10)-F(1,11)->F(2,11) F(1,12)+F(1,13)->F(2,12) F(1,14)+F(1,15)->F(2,13) F(1,12)-F(1,13)->F(2,14) F(1,14)-F(1,15)->F(2,15) 3й этап F(2,0)+F(2,4)->F(3,0) F(2,1)+rF(2,5)+rF(2,7)->F(3,1) F(2,2)+F(2,6)->F(3,2) F(2,3)-rF(2,7)+rF(2,5)->F(3,3) F(2,0)-F(2,4)->F(3,4) F(2,1)-rF(2,5)-rF(2,7)->F(3,5) F(2,2)-F(2,6)->F(3,6) F(2,3)+rF(2,7)-rF(2,5)->F(3,7) F(2,8)+F(2,12)->F(3,8) F(2,9)+rF(2,13)+rF(2,15)->F(3,9) F(2,10)+F(2,14)->F(3,10) F(2,11)-rF(2,15)+rF(2,13)->F(3,11) F(2,8)-F(2,12)->F(3,12) F(2,9)-rF(2,13)-rF(2,15)->F(3,13) F(2,10)-F(2,14)->F(3,14) F(2,11)+rF(2,15)-rF(2,13)->F(3,15) 4й этап F(3,0)+F(3,8)->> F(4,0)=H(0) F(3,1)+F(3,9)c1+F(3,15)c3->>F(4,1)=H(1) F(3,2)+F(3,10)c2+F(3,14)c2->>F(4,2)=H(2) F(3,1)+F(3,11)c3+F(3,13)c1->>F(4,3)=H(3) F(3,4)+F(3,12)->> F(4,4)=H(4) F(3,5)-F(3,13)c3+F(3,12)c1->>F(4,5)=H(5) F(3,6)-F(3,14)c2+F(3,11)c2->>F(4,6)=H(6) F(3,7)-F(3,15)c1+F(3,10)c3->>F(4,7)=H(7) F(3,0)-F(3,8)->> F(4,8)=H(8) F(3,1)-F(3,9)c1-F(3,15)c3->>F(4,9)=H(9) F(3,2)-F(3,10)c2-F(3,14)c2->>F(4,10)=H(10) F(3,1)-F(3,11)c3-F(3,13)c1->>F(4,11)=H(11) F(3,4)-F(3,12)->> F(4,12)=H(12) F(3,5)+F(3,13)c3-F(3,12)c1->>F(4,5)=H(5) F(3,6)+F(3,14)c2-F(3,11)c2->>F(4,6)=H(6) F(3,7)+F(3,15)c1-F(3,10)c3->>F(4,7)=H(7) где r=1/sqrt(2); с1= cos(2pi/16)=0,924; с2= cos(2pi*2/16)=0,707; с3= cos(2pi*3/16)=0,383.
Как видно из приведенных выше соотношений, основная вычислительная нагрузка идет на операции типа сложения/вычитания и выборку значений из памяти, особенно на первых трех этапах.
Будем предполагать, что отсчеты входного сигнала последовательно принимаются одним из ядер процессора (из внешнего или внутреннего АЦП, или, например, из памяти).
Применим конвейерную схему распараллеливания - каждое ядро или группа ядер заняты вычислением результатов отдельного этапа преобразования, с распараллеливанием операций по этапам. Выделим для проведения вычислений группу средних ядер процессора, тем самым, снижая нагрузку на периферийные ядра.
Диаграмма потоков данных двоично-инверсной перестановки для 16-ти ядер выглядит следующим образом:

Для первого этапа имеем следующее:
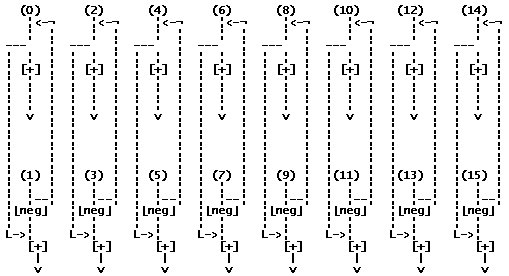
Для второго этапа:
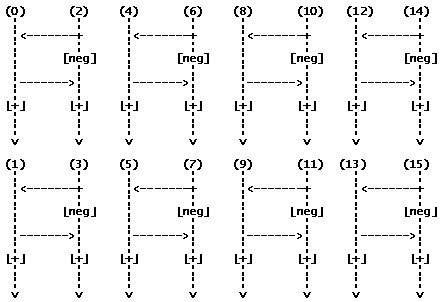
Для третьего этапа:
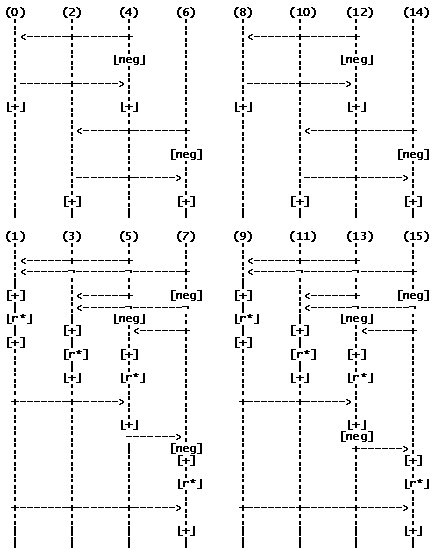
И заключительный четвертый этап:
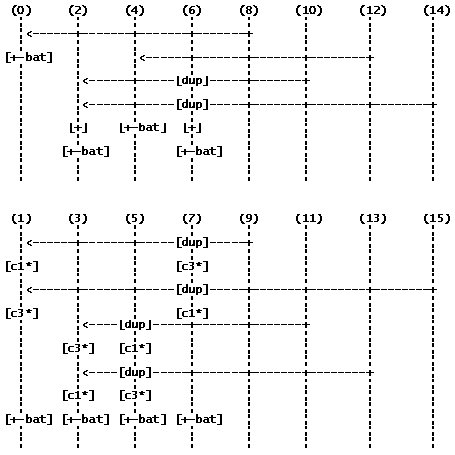
В результате в ядре с номером 0 хранятся коэффициенты Хартли 0 и 8; в 1-м - 1 и 9; во 2-м - 2 и 10; в 3-м - 3 и 11; в 4-м - 4 и 12; в 5-м - 5 и 13; в 6-м - 6 и 14; в 7-м - 7 и 15.
Для примера рассмотрена реализация БПХ на средних 16-ти ядрах SEAforth40, при этом ядра 28-21 соответствуют четным индексам (0=28, 2=27, и т.д.), а ядра 18-11 нечетным индексам (1=18, 3=17, и т.д.). Ядро 38 работает генератором сигнала - выдает шестнадцать последовательных отсчетов.
При создании кода учитывались следующие ограничения - работаем в формате с фиксированной точкой одинарной точности. Масштабирование - $100 =1.