Особенности управления памятью при создании мобильных приложений
8.3. Управление памятью на микроскопическом "уровне алгоритма"
Современные языки программирования, библиотеки классов и управляемые среды времени выполнения позволили значительно повысить продуктивность написания программ. В то же время, избавляя программиста от необходимости задумываться о низкоуровневом распределении памяти, в котором нуждаются алгоритмы, они невольно создают предпосылки для написания неэффективного кода. Неэффективность кода может быть обусловлена причинами двоякого рода:
-
Вычислительная неэффективность алгоритма. Этот вид неэффективности наблюдается в тех случаях, когда спроектированный вами алгоритм предусматривает интенсивные вычисления или выполнение большего количества циклов, чем это объективно необходимо, от чего можно было бы избавиться, используя более эффективные алгоритмы. В качестве классического примера можно привести сортировку массива данных. Иногда у вас может появляться возможность выбирать между несколькими возможными вариантами алгоритмов сортировки, отдельными частными случаями которых могут, например, быть алгоритмы "порядка N" (линейная зависимость времени вычислений от количества сортируемых элементов), "порядка N*Log(N)" (зависимость времени вычислений от количества сортируемых элементов отличается от линейной, но остается все же лучшей, чем экспоненциальная) или "порядка
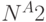 " (экспоненциальная зависимость времени вычислений
от количества сортируемых элементов). Кроме вышеперечисленных "порядков" возможно множество других (например,
" (экспоненциальная зависимость времени вычислений
от количества сортируемых элементов). Кроме вышеперечисленных "порядков" возможно множество других (например, 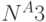 ). Выбор наиболее подходящего алгоритма зависит от объема данных, с которыми вы работаете, объема доступной памяти и ряда других факторов, например, от состояния рабочих данных. Отдельные стратегии, например, предварительная обработка данных перед отправкой их на устройство или хранение данных в формате, специфическом для использования памяти в качестве хранилища, способны обеспечить значительное повышение производительности алгоритма. Существует огромное количество компьютерной литературы, посвященной проектированию эффективных алгоритмов и оценке их быстродействия, поэтому никаких попыток более подробного анализа этих вопросов в данной книге не делается. Необходимо только отметить, что чем больше объем обрабатываемых данных, тем ответственнее необходимо отнестись к принятию решения относительно выбора вычислительного алгоритма.
Во всех затруднительных случаях тщательно анализируйте алгоритм и обращайтесь к существующей литературе по этому вопросу. Очень часто оказывается так, что кто-то другой уже прошел этот путь, и вам остается лишь перенять их опыт.
). Выбор наиболее подходящего алгоритма зависит от объема данных, с которыми вы работаете, объема доступной памяти и ряда других факторов, например, от состояния рабочих данных. Отдельные стратегии, например, предварительная обработка данных перед отправкой их на устройство или хранение данных в формате, специфическом для использования памяти в качестве хранилища, способны обеспечить значительное повышение производительности алгоритма. Существует огромное количество компьютерной литературы, посвященной проектированию эффективных алгоритмов и оценке их быстродействия, поэтому никаких попыток более подробного анализа этих вопросов в данной книге не делается. Необходимо только отметить, что чем больше объем обрабатываемых данных, тем ответственнее необходимо отнестись к принятию решения относительно выбора вычислительного алгоритма.
Во всех затруднительных случаях тщательно анализируйте алгоритм и обращайтесь к существующей литературе по этому вопросу. Очень часто оказывается так, что кто-то другой уже прошел этот путь, и вам остается лишь перенять их опыт. - Неэффективное распределение памяти. После того как вы определитесь со стратегией алгоритма, следующим фактором, от которого в значительной степени зависит производительность приложения, является способ реализации этого алгоритма. При этом едва ли не наибольшие усилия вы должны приложить к тому, чтобы избежать распределения лишних объемов памяти, особенно если память распределяется в циклах. В данном разделе этого курса основное внимание уделяется именно этому вопросу.
Вашей целью должно быть распределение "нулевых объемов памяти" внутри циклов в написанном вами коде. Существуют случаи, когда это является неизбежным, как, например, при построении дерева объектов, которое требует размещения в памяти новых узлов для помещения их в иерархическую структуру. Во многих других случаях эффективность приложения можно существенно повысить, тщательно анализируя распределение памяти для каждого объекта и рассматривая альтернативные решения. Чего, как правило, следует избегать - так это выполнения операций размещения объектов в памяти и удаления их из памяти внутри алгоритмических циклов.
8.4. "Структуры" и .NET Compact Framework
Во многих случаях, если вы хотите инкапсулировать некоторые простые данные, то для локальных переменных внутри функций гораздо эффективнее использовать не объекты, а структуры. Структура - это просто удобный способ сгруппировать в одном пакете взаимосвязанные данные, а не передавать их в виде отдельных переменных.
Структуры обладают более простыми свойствами по сравнению с объектами, но могут "упаковываться" в объекты и передаваться внутри программы так же, как они, если в этом возникает необходимость. Использование структур предоставляет определенные удобства и может привести к некоторому увеличению производительности (по сравнению с вариантом, когда используются объекты), но поскольку они выглядят, а во многих случаях и действуют подобно объектам и могут заключаться в объекты-оболочки, необходимо тщательно взвешивать, когда их следует использовать, чтобы избежать дополнительных накладных расходов и не создать лишнего мусора. В сомнительных случаях тестируйте алгоритмы, используя как отдельные переменные (например, базовые типы, подобные int, string, double ), так и структуры, чтобы сравнить производительность приложения в обоих случаях и убедиться в том, что она остается примерно одинаковой.
8.5. Использование строк в алгоритмах
Современные языки программирования позволяют очень легко работать со строками, создавать их, разбивать, копировать и объединять. Рассмотрим, например, следующие простые операторы:
string strl = "internet"; string str2 = "explorer"; string str3 = strl + str2; string str3 = str3 + str3;
Простота операций со строками ведет к их нерациональному использованию. Не оптимизированная обработка строк является одной из наиболее вероятных причин плохой производительности. Ниже представлены некоторые рекомендации и правила, которыми следует руководствоваться при работе со строками.
- Строки неизменчивы (постоянны). Этот странный термин неизменчивый (immutable) просто означает, что текстовые данные строки не могут быть изменены в памяти. Те операции в коде, которые, как вам кажется, изменяют данные строки, на самом деле создают новую строку. Постоянство обладает некоторыми весьма привлекательными свойствами. Например, поскольку строковые данные сами по себе являются статическими, несколько переменных могут указывать на одни и те же данные; благодаря этому присвоение одной строковой переменной значения другой сводится к простому копированию "указателя" вместо глубокого копирования всех данных, которые ему соответствуют. Отрицательной стороной неизменчивости является невозможность изменения данных. Если вы хотите изменить, добавить или отсечь данные, то эти изменения будут отражаться в новой копии строки.
-
Когда па строковые данные не ссылается пи одна "активная" ("live") переменная, они становятся "мусором". Рассмотрим пример:
string strl = "internet"; //"internet" - статические данные, скомпилированные //в двоичные данные вашего приложения string str2 = strl + strl; //только что была создана новая строка, являющаяся результатом конкатенации двух строк str2 = "explorer"; //Поскольку отсутствуют другие переменные, указывающие на те данные, на которые указывала переменная str2, //эти данные становятся мусором, и память должна быть //очищена от них.
- Если вы хотите сослаться на некоторую часть строки, то во многих случаях это проще всего сделать, используя целочисленные индексы в строке. Поскольку строки - это данные, представленные массивами символов, то использование индексов для получения этих данных не составляет труда. Существует множество функций, позволяющих осуществлять поиск и просмотр данных внутри строк (но только не изменять эти данные!).
-
Если вы создаете новые строки внутри циклов, настоятельно рекомендуется рассмотреть возможность использования объекта StringBuilder. Все виды строк создаются на основе других переменных, обрабатываемых в циклах. Типичным примером динамического создания строк может служить цикл, генерирующий текстовый отчет, каждая строка которого содержит следующие данные:Вместо того чтобы конкатенировать строки и создавать новую строку, для создания отчета можно было бы использовать класс StringBuilder. Класс StringBuilder очень удобно использовать для работы с массивами переменной размерности с целью создания строк. Он позволяет эффективно изменять длину или содержимое массива и, что самое важное, создавать новые строки на ос нове символьных массивов. Обязательно изучите класс StringBuilder, поскольку умение использовать его имеет решающее значение для написания эффективных алгоритмов, генерирующих строковые данные.
//Неэффективный код, выполняющийся внутри цикла { myString = myString +"CustomerID: " + System.Convert.ToString(customer[idx].id) + ", Name: " + System.Convert.ToString(customer[idx].name); } - Измеряйте объективные количественные показатели своих алгоритмов. Занимаясь написанием алгоритма обработки строк, тестируйте его быстродействие! Испробуйте несколько различных подходов. Вы очень быстро научитесь распознавать, какой алгоритм будет эффективным, а какой - нет.
В листинге представлены два аналогичных алгоритма, которые приводят к одному и тому же результату. В обоих алгоритмах осуществляется инкрементирование счетчика, и каждый раз, когда значение счетчика увеличивается, его строковое представление добавляется в расширяемый фрагмент текста. Оба алгоритма выполняют одинаковое количество итераций и характеризуются одинаковой степенью сложности написания, тем не менее, один из них работает гораздо быстрее другого.
//Для имитации создания типичного набора строк используются
//обычные строки
private void buttonl_Click(object sender, System.EventArgs e)
{
//Вызвать сборщик мусора, чтобы тест
//начинался с чистого состояния.
System.GC.Collect ();
int numberToStore = 0;
PerformanceSampling.StartSample (0, "StringAllocaitons");
string total_result = "";
for (int outer_loop = 0; outer_loop < LOOP_ITERATIONS; outer_loop++)
{
//Сбросить старый результат
total_result = "";
//Выполнять цикл до максимального значения x_counter, каждый
//раз присоединяя очередную тестовую строку к рабочей строке
for(int x_counter = 0; x_counter < COUNT_UNTIL; x_counter++)
{
total_result = total_result + numberToStore.ToString();
//Увеличить значение счетчика
numberToStore ++;
}
}
PerformanceSampling.StopSample(0);
//Отобразить длину строки
System.Windows.Forms.MessageBox.Show("Длина строки: " +total_result.Length.ToString());
//Отобразить строку
System.Windows.Forms.MessageBox.Show("Строка : " +total_result);
//Отобразить длительность интервала времени, ушедшего на вычисления
System.Windows.Forms.MessageBox.Show(PerformanceSampling.GetSampleDurationText(0));
}//Для имитации создания типичного набора строк используется
//объект StringBuilder
private void button2_Click(object sender, System.EventArgs e) {
//Вызвать сборщик мусора, чтобы тест
//начинался с чистого состояния.
System.GC.Collect();
System.Text.StringBuilder sb = new System.Text.StringBuilder(); string total_result = ""; int numberToStore = 0;
PerformanceSampling.StartSample(1, "StringBuilder");
for (int outerJLoop = 0; outer_loop < LOOP_ITERATIONS; outer_loop++)
{
//Очистить объект StringBuilder (не создавая нового объекта)
sb.Length = 0;
//Очистить строку со старым результатом
total_result = "";
//Выполнять цикл до максимального значения x_counter, каждый раз
//присоединяя очередную тестовую
//строку к рабочей строке
for(int x_counter = 0; x_counter < COUNTJJNTIL; x_counter++)
{
sb.Append(numberToStore );
sb.Append(", ");
//Увеличить значение счетчика numberToStore ++;
}
//Имитируем выполнение некоторых операций над строкой...
total_result = sb.ToStringO ;
}
PerformanceSampling.StopSample(1);
//Отобразить длину строки
System.Windows.Forms.MessageBox.Show("Длина строки: "+ total_result.Length.ToString()) ;
//Отобразить строку
System.Windows.Forms.MessageBox.Show("String : " + total_result);
//Отобразить длительность интервала времени, ушедшего на вычисления System.Windows.Forms.MessageBox.Show(
PerformanceSampling.GetSampleDurationText(1));
}