|
Не очень понятно про оболочечные Данные,ячейки памяти могут наверно размер менять,какое это значение те же операции только ячейки больше,по скорости тоже самое |
Опубликован: 04.12.2009 | Доступ: свободный | Студентов: 8416 / 657 | Оценка: 4.30 / 3.87 | Длительность: 27:27:00
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 7:
Важнейшие объектные типы
7.2. Коллекции, списки, итераторы
В Java получили широкое использование коллекции (Collections) – "умные" массивы с динамически изменяемой длиной, поддерживающие ряд важных дополнительных операций по сравнению с массивами. Базовым для иерархии коллекций является класс java.util.AbstractCollection. (В общем случае класс коллекции не обязан быть потомком AbstractCollection – он может является любым классом, реализующим интерфейс Collection ). Основные классы и интерфейсы коллекций:
- интерфейсы Set, SortedSet ; классы HashSet, TreeSet, EnumSet, LinkedHashSet — множества (неупорядоченные или некоторым образом упорядоченные наборы неповторяющихся элементов);
- интерфейс java.util.List ; классы java.awt.List, ArrayList, LinkedList, Vector — списки (упорядоченные наборы элементов, причем элементы могут повторяться в разных местах списка);
- интерфейсы Map, SortedMap ; классы HashMap, HashTable, ConcurrentHashMap, TreeMap, EnumMap, Properties — таблицы (списки пар "имя-значение").
Доступ к элементам коллекции в общем случае не может осуществляться по индексу, так как не все коллекции поддерживают индексацию элементов. Эту функцию осуществляют с помощью специального объекта – итератора ( iterator ). У каждой коллекции collection имеется свой итератор который умеет с ней работать, поэтому итератор вводят следующим образом:
Iterator iter = collection.iterator()
У итераторов имеются следующие три метода:
- boolean hasNext() - дает информацию, имеется ли в коллекции следующий объект.
- Object next() – возвращает ссылку на следующий объект коллекции.
- void remove() – удаляет из коллекции текущий объект, то есть тот, ссылка на который была получена последним вызовом next().
Пример преобразования массива в коллекцию и цикл с доступом к элементам этой коллекции, осуществляемый с помощью итератора:
java.util.List components= java.util.Arrays.asList(this.getComponents());
for (Iterator iter = components.iterator();iter.hasNext();) {
Object elem = (Object) iter.next();
javax.swing.JOptionPane.showMessageDialog(null,"Компонент: "+
elem.toString());
}Самыми распространенными вариантами коллекций являются списки ( Lists ). Они во многом похожи на массивы, но отличаются от массивов тем, что в списках основными операциями являются добавление и удаление элементов. А не доступ к элементам по индексу, как в массивах.
В классе List имеются методы коллекции, а также ряд дополнительных методов:
- list.get(i) – получение ссылки на элемент списка list по индексу i.
- list.indexOf(obj) - получение индекса элемента obj в списке list. Возвращает -1 если объект не найден.
- list.listIterator() – получение ссылки на итератор типа ListIterator, обладающего дополнительными методами по сравнению с итераторами типа Iterator.
- list.listIterator(i) – то же с позиционированием итератора на элемент с индексом i.
- list.remove(i) – удаление из списка элемента с индексом i.
- list.set(i,obj) – замена в списке элемента с индексом i на объект obj.
- list.subList(i1,i2) – возвращает ссылку на подсписок, состоящий из элементов списка с индексами от i1 до i2.
Кроме них в классе List имеются и многие другие полезные методы.
Ряд полезных методов для работы с коллекциями содержится в классе Collections:
- Collections.addAll(c,e1,e2,…,eN) - добавление в коллекцию c произвольного числа элементов e1,e2,…,eN.
- Collections.frequency(c,obj) – возвращает число вхождений элемента obj в коллекцию c.
- Collections.reverse(list) – обращает порядок следования элементов в списке list (первые становятся последними и наоборот).
- Collections.sort(list) – сортирует список в порядке возрастания элементов. Сравнение идет вызовом метода e1.compareTo(e2) для очередных элементов списка e1 и e2.
Кроме них в классе Collections имеются и многие другие полезные методы.
В классе Arrays имеется метод
- Arrays.asList(a) – возвращает ссылку на список элементов типа T, являющийся оболочкой над массивом T[] a. При этом и массив, и список содержат одни и те же элементы, и изменение элемента списка приводит к изменению элемента массива, и наоборот.
7.3. Работа со строками в Java. Строки как объекты. Классы String, StringBuffer и StringBuilder
Класс String инкапсулирует действия со строками. Объект типа String - строка, состоящая из произвольного числа символов, от 0 до 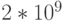 . Литерные константы типа String представляют собой последовательности символов, заключенные в двойные кавычки: "A", "abcd", "abcd", "Мама моет раму", " ".
. Литерные константы типа String представляют собой последовательности символов, заключенные в двойные кавычки: "A", "abcd", "abcd", "Мама моет раму", " ".
Это так называемые "длинные" строки. Внутри литерной строковой константы не разрешается использовать ряд символов - вместо них применяются управляющие последовательности.
Внутри строки разрешается использовать переносы на новую строку. Но литерные константы с такими переносами запрещены, и надо ставить управляющую последовательность "\n". К сожалению, такой перенос строки не срабатывает в компонентах.
Разрешены пустые строки, не содержащие ни одного символа.
В языке Java строковый и символьный тип несовместимы. Поэтому "A" - строка из одного символа, а 'A' - число с ASCII кодом символа "A". Это заметно усложняет работу со строками и символами.
Строки можно складывать: если s1 и s2 строковые литерные константы или переменные, то результатом операции s1+s2 будет строка, являющаяся сцеплением (конкатенацией) строк, хранящихся в s1 и s2. Например, в результате операции
String s="Это "+"моя строка";
в переменной s будет храниться строковое значение "Это моя строка".
Для строк разрешен оператор "+=". Для строковых операндов s1 и s2 выражение s1+=s2 эквивалентно выражению s1=s1+s2.
Любая строка (набор символов) является объектом - экземпляром класса String. Переменные типа String являются ссылками на объекты, что следует учитывать при передаче параметров строкового типа в подпрограммы, а также при многократных изменениях строк. При каждом изменении строки в динамической области памяти создается новый объект, а прежний превращается в "мусор". Поэтому при многократных изменениях строк в цикле возникает много мусора, что нежелательно.
Очень частой ошибкой является попытка сравнения строк с помощью оператора "==". Например, результатом выполнения следующего фрагмента
String s1="Строка типа String";
String s2="Строка";
s2+=" типа String";
if(s1==s2)
System.out.println("s1 равно s2");
else
System.out.println("s1 не равно s2");будет вывод в консольное окно строки "s1 не равно s2", так как объекты-строки имеют в памяти разные адреса. Сравнение по содержанию для строк выполняет оператор equals. Поэтому если бы вместо s1==s2 мы написали s1.equals(s2), то получили бы ответ "s1 равно s2".
Удивительным может показаться факт, что результатом выполнения следующего фрагмента
String s1="Строка";
String s2="Строка";
if(s1==s2)
System.out.println("s1 равно s2");
else
System.out.println("s1 не равно s2");будет вывод в консольное окно строки "s1 равно s2". Дело в том, что оптимизирующий компилятор Java анализирует имеющиеся в коде программы литерные константы, и для одинаковых по содержанию констант использует одни и те же объекты-строки.
В остальных случаях то, что строковые переменные ссылочные, обычно никак не влияет на работу со строковыми переменными, и с ними можно действовать так, как если бы они содержали сами строки.
В классе String имеется ряд методов. Перечислим важнейшие из них. Пусть s1 и subS имеют тип String, charArray – массив символов char[], ch1 – переменная или значение типа char, а i, index1 и count ("счет, количество") – целочисленные переменные или значения. Тогда
- String.valueOf(параметр) – возвращает строку типа String, являющуюся результатом преобразования параметра в строку. Параметр может быть любого примитивного или объектного типа.
- String.valueOf(charArray, index1,count) – функция, аналогичная предыдущей для массива символов, но преобразуется count символов начиная с символа, имеющего индекс index1.
У объектов типа String также имеется ряд методов. Перечислим важнейшие из них.
- s1.charAt(i) – символ в строке s1, имеющий индекс i (индексация начинается с нуля).
- s1.endsWith(subS) – возвращает true в случае, когда строка s1 заканчивается последовательностью символов, содержащихся в строке subS.
- s1.equals(subS) - возвращает true в случае, когда последовательностью символов, содержащихся в строке s1, совпадает с последовательностью символов, содержащихся в строке subS.
- s1.equalsIgnoreCase(subS) – то же, но при сравнении строк игнорируются различия в регистре символов (строчные и заглавные буквы не различаются).
- s1.getBytes() – возвращает массив типа byte[], полученный в результате платформо-зависимого преобразования символов строки в последовательность байт.
- s1.getBytes(charset) – то же, но с указанием кодировки ( charset ). В качестве строки charset могут быть использованы значения "ISO-8859-1" (стандартный латинский алфавит в 8-битовой кодировке), "UTF-8", "UTF-16" (символы UNICODE) и другие.
- s1.indexOf(subS) – индекс позиции, где в строке s1 первый раз встретилась последовательность символов subS.
- s1.indexOf(subS,i) – индекс позиции начиная с i, где в строке s1 первый раз встретилась последовательность символов subS.
- s1. lastIndexOf (subS) – индекс позиции, где в строке s1 последний раз встретилась последовательность символов subS.
- s1. lastIndexOf (subS,i) – индекс позиции начиная с i, где в строке s1 последний раз встретилась последовательность символов subS.
- s1.length() – длина строки (число 16-битных символов UNICODE, содержащихся в строке). Длина пустой строки равна нулю.
- s1.replaceFirst(oldSubS,newSubS) – возвращает строку на основе строки s1, в которой произведена замена первого вхождения символов строки oldSubS на символы строки newSubS.
- s1.replaceAll(oldSubS,newSubS) – возвращает строку на основе строки s1, в которой произведена замена всех вхождений символов строки oldSubS на символы строки newSubS.
- s1.split(separator) – возвращает массив строк String[], полученный разделением строки s1 на независимые строки по местам вхождения сепаратора, задаваемого строкой separator. При этом символы, содержащиеся в строке separator, в получившиеся строки не входят. Пустые строки из конца получившегося массива удаляются.
- s1.split(separator, i) – то же, но положительное i задает максимальное допустимое число элементов массива. В этом случае последним элементом массива становится окончание строки s1, которое не было расщеплено на строки, вместе с входящими в это окончание символами сепараторов. При i равном 0 ограничений нет, но пустые строки из конца получившегося массива удаляются. При i <0 ограничений нет, а пустые строки из конца получившегося массива не удаляются.
- s1.startsWith(subS) – возвращает true в случае, когда строка s1 начинается с символов строки subs.
- s1.startsWith(subs, index1) – возвращает true в случае, когда символы строки s1 с позиции index1 начинаются с символов строки subs.
- s1.substring(index1) – возвращает строку с символами, скопированными из строки s1 начиная с позиции index1.
- s1.substring(index1,index2) – возвращает строку с символами, скопированными из строки s1 начиная с позиции index1 и кончая позицией index2.
- s1.toCharArray() – возвращает массив символов, скопированных из строки s1.
- s1.toLowerCase() – возвращает строку с символами, скопированными из строки s1, и преобразованными к нижнему регистру (строчным буквам). Имеется вариант метода, делающего такое преобразование с учетом конкретной кодировки ( locale ).
- s1.toUpperCase() - возвращает строку с символами, скопированными из строки s1, и преобразованными к верхнему регистру (заглавным буквам). Имеется вариант метода, делающего такое преобразование с учетом конкретной кодировки ( locale ).
- s1.trim() – возвращает копию строки s1, из которой убраны ведущие и завершающие пробелы.
В классе Object имеется метод toString(), обеспечивающий строковое представление объекта. Конечно, оно не может отражать все особенности объекта, а является представлением "по мере возможностей". В самом классе Object оно обеспечивает возврат методом полного имени класса (квалифицированное именем пакета), затем идет символ "@", после которого следует число – хэш-код объекта (число, однозначно характеризующее данный объект во время сеанса работы) в шестнадцатеричном представлении. Поэтому во всех классах-наследниках, где этот метод не переопределен, он возвращает такую же конструкцию. Во многих стандартных классах этот метод переопределен. Например, для числовых классов метод toString() обеспечивает вывод строкового представления соответствующего числового значения. Для строковых объектов - возвращает саму строку, а для символьных (тип Char ) - символ.
При использовании операций "+" и "+=" с операндами, один из которых является строковым, а другой нет, метод toString() вызывается автоматически для нестрокового операнда. В результате получается сложение (конкатенация) двух строк. При таких действиях следует быть очень внимательными, так как результат сложения более чем двух слагаемых может оказаться сильно отличающимся от ожидаемого. Например,
String s=1+2+3;
даст вполне ожидаемое значение s=="6". А вот присваивание
String s="Сумма ="+1+2+3;
даст не очень понятное начинающим программистам значение " Сумма =123". Дело в том, что в первом случае сначала выполняются арифметические сложения, а затем результат преобразуется в строку и присваивается левой части. А во втором сначала производится сложение "Сумма ="+1. Первый операнд строковый, а второй - числовой. Поэтому для второго операнда вызывается метод toString(), и складываются две строки. Результатом будет строка "Сумма =1". Затем складывается строка "Сумма =1" и число 2. Опять для второго операнда вызывается метод toString(), и складываются две строки. Результатом будет строка "Сумма =12". Совершенно так же выполняется сложение строки "Сумма =12" и числа 3.
Еще более странный результат получится при присваивании
String s=1+2+" не равно "+1+2;
Следуя изложенной выше логике мы получаем, что результатом будет строка "3 не равно 12".
Выше были приведены простейшие примеры, и для них все достаточно очевидно. Если же в такого рода выражениях используются числовые и строковые функции, да еще с оператором " ? : ", результат может оказаться совершенно непредсказуемым.
Кроме указанных выше имеется ряд строковых операторов, заданных в оболочечных числовых классах. Например, мы уже хорошо знаем методы преобразования строковых представлений чисел в числовые значения
- Byte.parseByte ( строка )
- Short.parseShort ( строка )
- Integer.parseInt ( строка )
- Long.parseLong ( строка )
- Float.parseFloat ( строка )
- Double.parseDouble ( строка )
и метод valueOf ( строка ), преобразующий строковые представления чисел в числовые объекты – экземпляры оболочечных классов Byte, Short, Character, Integer, Long, Float, Double. Например,
- Byte.valueOf ( строка ) , и т.п.
Кроме того, имеются методы классов Integer и Long для преобразования чисел в двоичное и шестнадцатеричное строковое представление:
- Integer.toBinaryString ( число )
- Integer.toHexString ( число )
- Long.toBinaryString ( число )
- Long.toHexString ( число )
Имеется возможность обратного преобразования – из строки в объект соответствующего класса ( Byte, Short, Integer, Long ) с помощью метода decode:
Также полезны методы для анализа отдельных символов:
- Character.isDigit ( символ ) – булевская функция, проверяющая, является ли символ цифрой.
- Character.isLetter ( символ ) – булевская функция, проверяющая, является ли символ буквой.
- Character.isLetterOrDigit ( символ ) – булевская функция, проверяющая, является ли символ буквой или цифрой.
- Character.isLowerCase ( символ ) – булевская функция, проверяющая, является ли символ символом в нижнем регистре.
- Character.isUpperCase ( символ ) – булевская функция, проверяющая, является ли символ символом в верхнем регистре.
- Character.isWhitespace ( символ ) – булевская функция, проверяющая, является ли символ "пробелом в широком смысле" – пробелом, символом табуляции, перехода на новую строку и т.д.
Для того чтобы сделать работу с многочисленными присваиваниями более эффективной, используются классы StringBuffer и StringBuilder. Они особенно удобны в тех случаях, когда требуется проводить изменения внутри одной и той же строки (убирать или вставлять символы, менять их местами, заменять одни на другие). Изменение значений переменных этого класса не приводит к созданию мусора, но несколько медленнее, чем при работе с переменными типа String. Класс StringBuffer рекомендуется использовать в тех случаях, когда используются потоки ( threads ) – он, в отличие от классов String и StringBuilder, обеспечивает синхронизацию строк. Класс StringBuilder, введенный начиная с JDK 1.5, полностью ему подобен, но синхронизации не поддерживает. Зато обеспечивает большую скорость работы со строками (что обычно бывает важно только в лексических анализаторах).
К сожалению, совместимости по присваиванию между переменными этих классов нет, как нет и возможности преобразования этих типов. Но в классах StringBuffer и StringBuilder имеется метод sb.append(s), позволяющий добавлять в конец "буферизуемой" строки sb обычную строку s. Также имеется метод sb.insert(index,s), позволяющий вставлять начиная с места символа, имеющего индекс index, строку s.
Пример:
StringBuffer sb=new StringBuffer();
sb.append("типа StringBuffer");
sb.insert(0,"Строка ");
System.out.println(sb);Буферизуемые и обычные строки можно сравнивать на совпадение содержания: s1.contentEquals(sb) – булевская функция, возвращающая true в случае, когда строка s1 содержит такую же последовательность символов, как и строка sb.
Полетаев Дмитрий
Максим Старостин
|
Код с перемещением фигур не стирает старую фигуру, а просто рисует новую в новом месте. Точку, круг. |