Intel® CilkTM Plus – общая характеристика и ключевые слова
Плохой и хороший стиль

Ключевое слово cilk_for
cilk_for является псевдонимом к _Cilk_for.
Распараллеливание цикла. В программе используется вместо заголовка цикла с параметром:
cilk_for(int k = 0; k < Niterations; ++k) {тело цикла}В конце цикла используется барьерная синхронизация – исполнение программы продолжается только после завершения всех итераций.
Синтаксис (допустим любой из трех):
cilk_for(описания; условное выражение; приращение)
Ограничения
- Распараллеливаются только циклы без цикловых зависимостей (итерации могут выполняться независимо).
- Недопустимы переходы в тело цикла и из него (операторы return, break, goto с переходом из тела цикла или в тело цикла).
- В цикле должна быть только одна переменная цикла.
- Переменная цикла не должна модифицироваться в цикле.
- Границы изменения параметра и шаг не должны меняться в теле цикла.
- Цикл не должен быть бесконечным.
Пример:
void floyd_warshall() {
cilk_for (int k = 0; k < n; ++k)
for (int i = 0; i < n; ++i)
work(k,i);
}Алгоритм
Рекурсивный алгоритм divide-and- conquer.
Нельзя считать, что каждая итерация цикла запускается в параллельном потоке!
Компилятор преобразует тело цикла в функцию, которая вызывается рекурсивно, с использованием стратегии "разделяй и властвуй".
На каждом уровне рекурсии половина оставшейся работы выполняется потомком , а вторая половина – продолжением.
Такой алгоритм позволяет обеспечить оптимальный баланс накладных расходов и выигрыша в результате распараллеливания для циклов с разной сложностью.
#pragma cilk grainsize = 1 cilk_for (int Niterations = 0; Niterations < 8; ++ Niterations) f(Niterations);
Ключевое слово grainsize задает гранулярность распараллеливания (количество итераций в наименьшей "порции", которые будут выполняться последовательно).
Если зернистость не указано явно, используется следующая формула:
#pragma cilk grainsize = min(512, N / (8*p))
Здесь N – число итераций цикла, p – число исполнителей. В случае, когда N>4096*p, зернистость устанавливается равной 512.
Если grainsize = 0, используется формула по умолчанию.
Если grainsize < 0, результат не определен.
Если
#pragma cilk grainsize = n/(4*__cilkrts_get_nworkers())
Зернистость будет определяться во время выполнения программы.

Как выбрать оптимальное значение зернистости
Если количество работы значительно варьируется от итерации к итерации, следует уменьшить grainsize.
Если все итерации "маленькие" (в смысле вычислительной сложности) , следует увеличить grainsize.
Оптимальность выбора grainsize следует подтверждать опытнм путем!
Пример
for( int i=0; i<n; ++i )
cilk_spawn f(i);
cilk_sync;
Пример
a(); cilk_spawn b(); c(); cilk_sync; d();
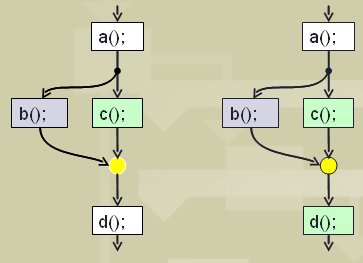
Пример
…
#include <cilk/cilk.h>
int const n = 500;
int dist[n][n];
void work(int k, int i)
{
for (int j = 0; j < n; ++j)
if ((dist[i][k] * dist[k][j] != 0) && (i != j))
if ((dist[i][k] + dist[k][j] < dist[i][j]) ||
(dist[i][j] == 0))
dist[i][j] = dist[i][k] + dist[k][j];
}
void floyd_warshall() {
cilk_for (int k = 0; k < n; ++k)
for (int i = 0; i < n; ++i)
work(k,i);
}
int main(int argc, char *argv[]) {
srand(time(NULL));
int i, j;
for (i = 0; i < n; ++i)
for (j = 0; j < n; ++j)
{
if(i!=j)
dist[i][j]=rand()%130;
else
dist[i][j]=0;
}
floyd_warshall();
}
Накладные расходы на диспетчеризацию
Сравним два варианта распараллеливания двойного цикла:
// A
cilk_for (int i = 0; i < 4; ++i)
for (int j = 0; j < 1000000; ++j)
do_work();
// B
for (int j = 0; j < 1000000; ++j)
cilk_for (int i = 0; i < 4; ++i)
do_work();Эффективность распараллеливания фрагмента A выше, чем эффективность распараллеливания фрагмента B.