
|
поддерживаю выше заданые вопросы
|
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1753 / 198 | Длительность: 17:47:00
Специальности: Программист
Теги:
Лекция 2:
Архитектурные аспекты параллелизма
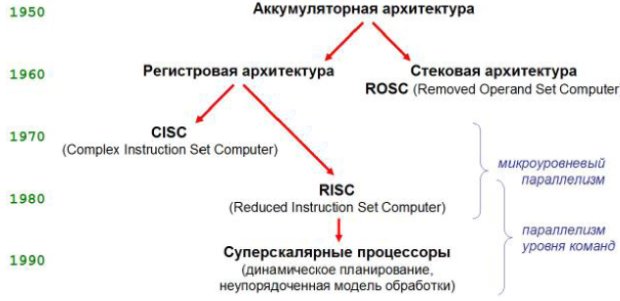
Эволюция микропроцессорных архитектур
Рассмотрим основные вехи в эволюции микропроцессорных архитектур. На ранних стадиях эволюции смена поколений ассоциировалась с революционными технологическими прорывами: каждое из первых четырех поколений имело четко выраженные отличительные технологические признаки. Последующие нечеткие деления на поколения основаны на изменениях в архитектуре вычислительных систем, а не на изменениях элементной базы.
Итак, вплоть до 1945 года была "механическая" эра эволюции вычислительной техники (нулевое поколение). Ключевым моментом эволюции является концепция вычислительной машины с хранимой в памяти программой, сформулированная Джоном фон Нейманом в 1945 году. Относительно нее историю развития вычислительной техники можно представить в виде трех этапов: донеймановкого периода, эры вычислительных машин с фон-неймановской архитектурой и постнеймановской эпохи (эпохи параллельных и распределенных вычислений). Напомним, что сущность фон-неймановской концепции состоит из четырех принципов: двоичного кодирования, программного управления, однородности памяти (с позиций современного программирования не приветствуется) и адресности.
Первое поколение вычислительной техники (1937–1953) использовало электронные компоненты, которые могли переключаться в тысячу раз быстрее электромеханических аналогов. Программирование осуществлялось в машинном коде, а в пятидесятых годах вместо числовой записи появилась символьная нотация (ассемблер). В простейшем дизайне процессора был только аккумулятор.
Второе поколение (1954–1962) ознаменовалось переходом от электронных ламп к полупроводниковым диодам и транзисторам со временем переключения порядка 0.3 мс. Появление регистрового файла позволило организовать машины либо с регистровой архитектурой, либо со стековой архитектурой. Тогда стековая архитектура превалировала над регистровой, благодаря очень компактному коду. Безоперандные команды брали аргументы из стека и клали результат в стек. Для кодирования такой команды достаточно нескольких бит. В условиях ограниченности объема доступной памяти это было очень веским преимуществом. В дальнейшем появление полупроводниковых запоминающих устройств привело к резкому увеличению объема оперативной памяти и, соответственно, к бесперспективности стековой архитектуры.
Третье поколение вычислительной техники (1963–1972) ознаменовалось переходом от дискретных полупроводниковых элементов к интегральным микросхемам, что обусловило скачок производительности. Зарождаются принципы конвейеризации и суперскалярности (принципы мелкозернистого параллелизма). Появляются многозадачные ОС. Архитектура системы команд (ISA) сильно развивается, предоставляя программистам более развитые команды. Такую ISA впоследствии назовут CISC.
Четвертое поколение (1972–1984) осуществило переход на СБИС (тысячи транзисторов на одном кристалле). Появление языков высокого уровня привело к резкому снижению востребованности CISC инструкций, так как компиляторы использовали только небольшое подмножество из них. Оказалось целесообразным перейти к архитектуре с сокращенным набором команд (RISC) и использовать высвобожденные ресурсы (транзисторы) для улучшения количественных характеристик CPU.
В девяностых годах доминируют суперскалярные процессоры. Принципы мелкозернистого параллелизма эксплуатируются максимально. Процессор содержит сложную логику динамического планирования в неупорядоченной модели обработки. Увеличение числа конвейеров и станций резервации приводит к экспоненциальному росту взаимосвязей между ними, что ограничивает дальнейшее распараллеливание на уровне команд. Назрела необходимость использования более высоких уровней параллелизма, началась эпоха параллельных и распределенных вычислений (постнеймановская эпоха).
Заметим, что история развития дизайна процессоров (включая эволюцию ISA) связана с агрегированием все более высоких уровней параллелизма, что в настоящее время привело к мультипроцессорным и мультикомпьютерным системам.
Система команд первых трех поколений вычислительной техники стремилась удовлетворить растущие потребности развивающихся технологий программирования, включая в состав ISA новые, более развитые команды. Однако угнаться за высоким темпом развития технологий программирования процессоростроители не могли. Образовался семантический разрыв. Так самая сложная в мире CISC система команд x86 не содержит никакой поддержки, например, объектно-ориентированного программирования. Отказ от языковой гонки (переход на RISC) и постоянное совершенствование языков программирования (Java и т.д.) закрепили семантический разрыв окончательно. Тем не менее, стоит отметить, что в последнее время все активнее осуществляется аппаратная поддержка процессорами общего назначения машинного кода Java (иначе программная интерпретация кода Java имеет низкую производительность) либо в полном объеме, либо частично. Сейчас язык Java и код Java возродили интерес к стековой архитектуре (ROSC). В процессоры все чаще стали интегрировать виртуальные машины.
Все современные процессоры базируются на RISC. Некоторые могут возразить: например, машинный код Pentium 4 типа CISC, а машинный код сопроцессора Pentium 4 типа ROSC. Тем не менее, Pentium 4 имеет RISC ядро (начиная с i486). Поддержка CISC и ROSC инструкций выполнена с использованием техники Code Morphing для обеспечения преемственности x86 программ. Фактически, CISC и ROSC интерпретируются процессором при помощи декодирования в RISC инструкции (в микрокод).
Тенденции развития GPP
Итак, назревшая необходимость использования более высоких уровней параллелизма определила перспективные пути развития GPP: VLIW, SMT и CMP. Переход от RISC к VLIW (как в процессорах общего, так и специального назначения) позволил преодолеть ограниченность ILP. Тенденции многопоточного (SMT) и многоядерного процессирования (CMP) привели к аппаратной поддержке крупнозернистого параллелизма.
Архитектура VLIW
Процессоры с множественной выдачей инструкций (multiple-issue processors) ориентированы на исполнение нескольких инструкций за такт и бывают двух видов: суперскалярные процессоры (superscalar processors) и процессоры с архитектурой VLIW (Very Long Instruction Word).
Первые суперскалярные процессоры работали в режиме упорядоченной выдачи команд. Но упорядоченная выдача команд (in-order issue) неэффективна, так как требуемое функциональное устройство (FU) может оказаться занятым. Упорядоченное завершение команд (in-order completion) также неэффективно, так как остановка продвижения в одном FU приведет к простою всех FU. Неупорядоченные выдача и завершение – неупорядоченная модель обработки (out-of-order execution) – дополнительный потенциал повышения производительности суперскалярного процессора. Современные суперскалярные процессоры исполняют от 2 до 10 инструкций за такт и используют аппаратную логику анализа ILP перед выдачей команд. Такой аппаратный механизм переупорядочивания исполнения инструкций (out-of-order engine) называется динамическим планированием. Компилятор и динамический планировщик не могут обойти все конфликты (структурные, по данным, по управлению) и задержки доступа к памяти (при кеш-промахах). Таким образом, фактическое число выданных в такте инструкций колеблется от нуля до максимально возможного (загрузка FU колеблется от 0% до 100%).
Если суперскалярные процессоры исполняют переменное число инструкций за такт, используя методы как статического (развертка кода компилятором), так и динамического (алгоритм Томасуло) планирования, то VLIW процессоры, напротив, исполняют фиксированное число независимых инструкций, сгруппированных в одну длинную инструкцию. В таком пакете инструкций параллелизм уровня инструкций обеспечивается статически на этапе компиляции. Компания Intel, например, именует такую методику явного распараллеливания инструкций – EPIC – Explicitly Parallel Instruction Computing.
Суть явного параллелизма заключается в том, что распределение команд между исполнительными узлами производится не процессором в ходе выполнения программы (динамически), а компилятором при формировании машинного кода (статически).
Таким образом, схемотехника VLIW процессора существенно упрощается (по сложности он сравним с суперскалярным процессором без поддержки неупорядоченного исполнения команд). Кроме того, в компиляторах алгоритмы выбора порядка исполнения команд могут быть существенно сложнее и эффективнее, чем алгоритмы аппаратного планирования инструкций (так как решение необходимо принимать в течение наносекунд).
Классические многопоточные процессоры
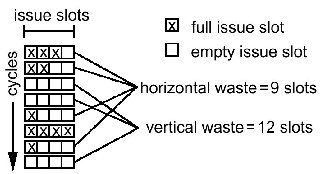
Для однопоточного суперскалярного процессора характерен простой функциональных устройств вследствие имеющихся зависимостей (в первую очередь типа RAW) в исходном алгоритме решения задачи. Потерянные слоты выдачи инструкций можно классифицировать на вертикальные и на горизонтальные потери.
Причины возникновения пустых слотов – структурные конфликты, конфликты данных и управления. Так на рис. 7 приведен пример работы однопоточного четырехконвейерного процессора, для которого идеальное IPC = 4. Реальное IPC будет существенно меньше идеального (пикового) IPC.
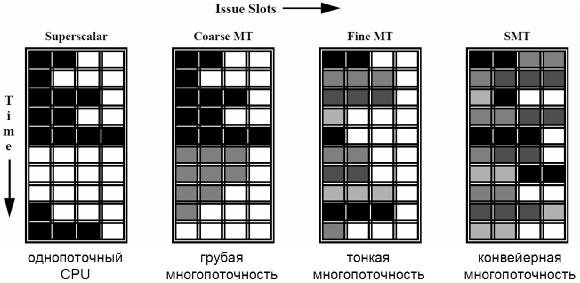
Классическое многопоточное процессирование снижает вертикальные потери слотов выдачи за счет использования параллелизма более высокого уровня – параллелизма уровня потоков (TLP). Вместо простоев при исполнении единственного потока команд происходят переключения на исполнение других потоков команд (в порядке кольцевой очереди). При этом усложнение аппаратуры минимально – необходимо поддерживать несколько контекстов исполнения (в основном несколько регистровых файлов). Только один поток (один контекст) выдает инструкции каждый такт. С точки зрения ОС множество аппаратных контекстов – это несколько логических процессоров (SMP система). Такая аппаратная многопоточность не снижает горизонтальные потери, так как параллелизм уровня инструкций в каждом отдельном потоке остается ограниченным.
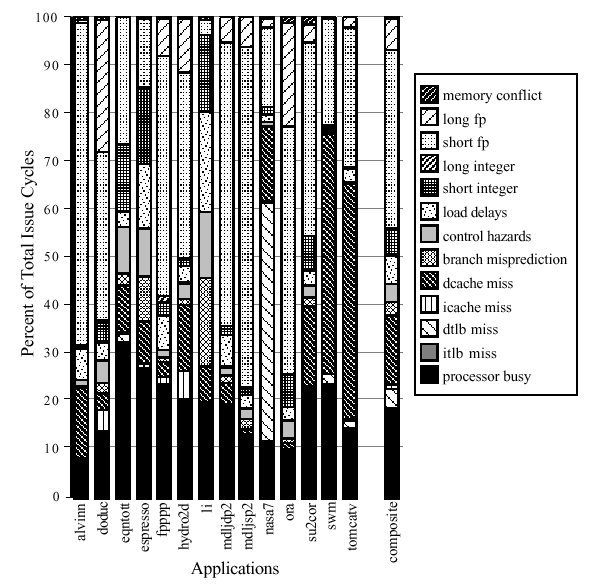
В [5] под нагрузкой SPEC92 собрана статистика причин простоев восьмипоточного процессора: реальное IPC _ 1.5, потерян 81% слотов выдачи, из них вертикальных – 61% (рис. 2.8).
Конвейерная многопоточность
Simultaneous Multithreading (SMT) – эволюционная микропроцессорная архитектура, впервые представленная в 1995 году в университете Вашингтона Дином Тулсеном (Dean Tullsen) и предназначенная для повышения эффективности использования аппаратных ресурсов в многопоточных суперскалярных микропроцессорах.
SMT использует параллелизм уровня потоков (TLP) на одном вычислительном ядре, позволяющий производить одновременную выдачу, исполнение и завершение инструкций из различных потоков в течение одного и того же такта. Один физический SMT процессор действует как несколько логических процессоров, каждый из которых исполняет отдельный поток инструкций. SMT предоставляет эффективный механизм скрытия длительных простоев конвейера, снижая как вертикальные, так и горизонтальные потери.
Экономическая целесообразность технологии SMT: рост производительности значительно больше, чем рост площади чипа и энергопотребления.
При множестве исполняющихся потоков в случаях промахов кеша, неверно предсказанных переходов и т.п. скрываются даже длительные штрафы (с большими задержками). Снижение и горизонтальных, и вертикальных потерь слотов выдачи ведет к увеличению скорости выдачи инструкций (к увеличению IPC). Функциональные устройства совместно используются всеми контекстами в каждом такте. Выдача инструкций для функциональных устройств множеством потоков повышает использование ресурсов процессора. Однако с целью поддержки множества исполняющихся потоков накладываются более жесткие требования к размерам ресурсов процессора (кешей, буфера BTB, буфера TLB, буфера переименования и т.д.).
Необходимые изменения для поддержки SMT: множество контекстов исполнения и привязка каждой инструкции к своему контексту при прохождении всего конвейера; механизм выборки инструкций из множества потоков; отдельные для каждого потока механизмы завершения инструкций, менеджмента очереди инструкций и обработки исключений.
Изменения для повышения производительности SMT: больший аппаратный регистровый файл для поддержки переименования регистров во всех потоках; большая пропускная способность доступа к памяти; большие кеши для компенсации снижения производительности из-за совместного использования несколькими потоками (из-за снижения локальности); больший BTB; больший TLB.
Преимущества SMT: преодоление ограничений производительности суперскалярной обработки, связанных с низким параллелизмом уровня инструкций, посредством применения параллелизма уровня потоков; повышение эффективности использования аппаратных ресурсов; предоставление механизма скрытия длительных простоев конвейера. Недостатки SMT: повышенные требования к производительности иерархии памяти; повышенные требования к размерам ресурсов процессора.
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|