Семантический анализ. Внутреннее представление
Атрибутное дерево разбора
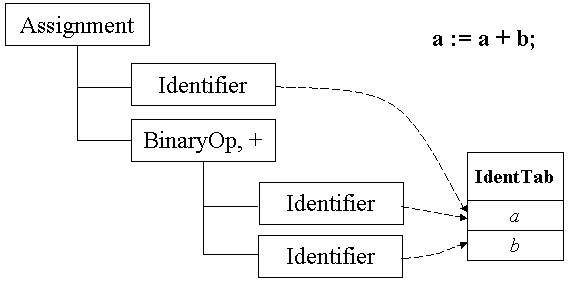
Атрибутное дерево разбора является, наверное, самой распространенной формой организации внутреннего представления программы. При таком подходе каждая исходная конструкция языка представляется в виде узла дерева, содержащего ссылки на все возможные элементы этой конструкции (естественно, каждый отдельный элемент тоже может иметь сложную структуру и, таким образом, также может быть поддеревом). Кроме того, каждый узел дерева может нагружаться дополнительными атрибутами, такими, как ссылки в таблицы представлений или таблицы идентификаторов. В итоге, вся программа представляется в виде единого дерева разбора.
На слайде в качестве примера приведено атрибутное дерево разбора, порожденное по следующему оператору исходного языка a := a + b; Отметим, что форма представления дерева, использованная на слайде, является типичной при компиляции, так как позволяет изобразить практически сколь угодно сложные деревья на экране компьютера (попробуйте представить себе традиционное изображение дерева разбора для сколько-нибудь сложной программы!).
Деревья разбора привлекательны прежде всего своей гибкостью и возможностью использования в самых разных этапах компиляции - их можно спроектировать таким образом, чтобы они мало зависели от исходного языка и целевой платформы. Деревья разбора легко строить во время анализа исходной программы, а все последующие просмотры компилятора могут быть реализованы в виде самостоятельных обходов этого дерева. Кроме того, некоторые просмотры, такие, как оптимизация программы, удобнее всего выполнять именно над деревьями разбора.
Польская запись
Польская запись была предложена польским логиком Лукасевичем. В этой форме записи все операторы непосредственно предшествуют операндам. Так, обычное выражение (a+b)*(c-d) в польской записи может быть представлено как *+ab-cd.
Такую форму записи называют также префиксной. Аналогичным образом вводится обратная или постфиксная польская запись, в которой все операторы выписываются после операндов. Скажем, пример, приведенный выше, в обратной польской записи будет записан следующим образом: ab+cd-*. Для представления унарных операций в польской записи можно воспользоваться эквивалентными выражениями, использующими бинарные операции, как в следующем примере: -b -> 0 - b, а можно ввести новый знак операции, скажем, @b . Польская запись может быть распространена не только на арифметические выражения, но и на прочие конструкции языка. Например, оператор a := a + b; может быть записан в польской записи как :=a+ab, а условный оператор if <expr> then <instr1> else <instr2> может быть записан как следующая последовательность операторов:
<expr> <c1> BZ <instr1> <c2> BR <instr2>,
где c1 указывает на первую инструкцию <instr2>, а c2 - на первую инструкцию, следующую за <instr2>, BR - безусловный переход на адрес <c2>, а BZ - переход на <c1> при условии равенства нулю выражения <expr1>.
Пользуясь такой терминологией, мы можем называть традиционную форму записи выражений инфиксной, так как в ней знаки операций расположены между операндами. Понятно, что любое выражение может быть переведено из инфиксной формы в польскую запись и наоборот. Польская запись замечательна тем, что при ее использовании исчезает потребность в приоритетах операций - каждая операция выполняется в порядке появления в исходной цепочке (хотя очевидно, что приоритет операций необходимо учитывать при преобразованиях из инфиксной формы).
Польская запись (особенно обратная) очень хорошо накладывается на стековую модель: каждый встреченный операнд загружается в стек, а операции производятся только на вершине стека: каждая операция снимает необходимое количество операндов с вершины стека и кладет на стек свой результат. Именно такая модель используется в MSIL для реализации большинства операций.
Триады и тетрады

Триады и тетрады представляют собой низкоуровневые формализмы записи промежуточного представления программы, приближающие программу к объектному коду. В этих формализмах все операции записываются в виде последовательности действий, выдающих результаты.
Тетрады (также называемые "четверками" или трехадресным кодом) состоят из двух операндов, разделенных операцией, и результата операции, записываемого с помощью равенства и обозначаемого целым числом (см. пример на слайде). Таким образом, тетрады содержат явную ссылку на результат операции. В каком-то смысле, это может считаться недостатком тетрад, так как при прямолинейной генерации кода приходится порождать по одной временной переменной на каждую операцию в программе.
Триады (также называемые "тройками" или двухадресным кодом) построены аналогичным образом, но не содержат явного указания на результат операции, хотя на эти результаты по-прежнему можно ссылаться в последующих командах. Подразумевается, что задачу отслеживания и нумерации всех триад выполняет сам компилятор. Понятно, что триады компактнее тетрад, но с другой стороны, отсутствие явного указания на результат операции может затруднить фазу оптимизации. Эту проблему можно решить путем использования косвенных триад, в которых вместо ссылки на ранее использовавшуюся триаду используется ссылка на элемент специальной таблицы указателей на триады.
Естественно, триады и тетрады также могут быть расширены для записи всех операций, поддерживаемых на данной целевой платформе.