Лабораторная работа
Оптимизация
Рассмотрите листинги ассемблерного кода, полученные Clang при разных уровнях оптимизации, выполнив следующие команды:
- без оптимизаций
clang -target riscv64-unknown-linux-gnu --sysroot="$GCC_ROOT/sysroot" --gcc-toolchain="$GCC_ROOT" -S -o main.s main.c
- с флагом -O1
clang -target riscv64-unknown-linux-gnu --sysroot="$GCC_ROOT/sysroot" --gcc-toolchain="$GCC_ROOT" -S -o main-O1.s main.c -O1
- с флагом -O2
clang -target riscv64-unknown-linux-gnu --sysroot="$GCC_ROOT/sysroot" --gcc-toolchain="$GCC_ROOT" -S -o main-O2.s main.c -O2
Будет получен следующий ассемблерный код для функции dot_product:
Компиляция без оптимизаций
dot_product: # @dot_product
# %bb.0:
addi sp, sp, -64
sd ra, 56(sp) # 8-byte Folded Spill
sd s0, 48(sp) # 8-byte Folded Spill
addi s0, sp, 64
sd a0, -24(s0)
sd a1, -32(s0)
sd a2, -40(s0)
li a0, 0
sw a0, -44(s0)
sd a0, -56(s0)
j .LBB0_1
.LBB0_1: # =>This Inner Loop Header: Depth=1
ld a0, -56(s0)
ld a1, -40(s0)
bgeu a0, a1, .LBB0_4
j .LBB0_2
.LBB0_2: # in Loop: Header=BB0_1 Depth=1
ld a0, -24(s0)
ld a1, -56(s0)
slli a1, a1, 2
add a0, a0, a1
flw ft0, 0(a0)
ld a0, -32(s0)
add a0, a0, a1
flw ft1, 0(a0)
flw ft2, -44(s0)
fmadd.s ft0, ft0, ft1, ft2
fsw ft0, -44(s0)
j .LBB0_3
.LBB0_3: # in Loop: Header=BB0_1 Depth=1
ld a0, -56(s0)
addi a0, a0, 1
sd a0, -56(s0)
j .LBB0_1
.LBB0_4:
flw fa0, -44(s0)
ld ra, 56(sp) # 8-byte Folded Reload
ld s0, 48(sp) # 8-byte Folded Reload
addi sp, sp, 64
ret
В строках 3-12 происходит формирование кадра стека функции dot_product: выделяется необходимое для аргументов и локальных переменных место на стеке (строка 3), на стеке сохраняется адрес возврата и адрес предыдущего кадра (строки 4-5), в регистр сохраняется адрес текущего кадра (строка 6), переданные аргументы a, b и n загружаются на стек (строки 7-9), локальные переменные r и i инициализируются нулями (строки 10-12).
В строках 15-17 вычисляется, нужно ли выполнять очередную итерацию цикла: со стека в регистры загружаются значения переменных i и n (строки 15-16), а затем сравниваются (строка 17).
В строках 20-30 происходит вычисление очередной итерации цикла: со стека в регистр загружается значение переменной i (строка 21), вычисляются адреса в памяти значений a[i] и b[i] и они загружаются в регистры (строки 20, 22-27), со стека в регистр загружается значение переменной r (строка 28), к значению r прибавляется результат a[i] * b[i] (строка 29), новое значение r записывается на стек (строка 30).
В строках 33-35 происходит увеличение счётчика цикла i после выполнения очередной итерации: со стека в регистр загружается значение переменной i (строка 33), значение переменной i увеличивается на 1 (строка 34), новое значение переменной i записывается на стек (строка 35).
В строках 38-42 происходит возврат результата после выполнения цикла: со стека в регистр, через который возвращается результат, загружается значение переменной r (строка 38), со стека в регистры загружаются адрес возврата и адрес предыдущего кадра стека (строки 39-40), очищается кадр стека (строка 41), происходит возврат из функции dot_product (строка 42).
Компиляция с флагом 
dot_product: # @dot_product
# %bb.0:
fmv.w.x fa0, zero
beqz a2, .LBB0_2
.LBB0_1: # =>This Inner Loop Header: Depth=1
flw ft0, 0(a0)
flw ft1, 0(a1)
fmadd.s fa0, ft0, ft1, fa0
addi a2, a2, -1
addi a1, a1, 4
addi a0, a0, 4
bnez a2, .LBB0_1
.LBB0_2:
ret
Полученный ассемблерный код значительно короче, полученного без применения оптимизаций. Это получается за счёт того, что на стеке не выделяется место под аргументы и локальные переменные, и все вычисления производятся с регистрами без обращений к памяти.
В строке 3 происходит инициализация регистра, в котором хранится значение r, нулём.
В строке 4 происходит сравнение регистра, в котором хранится значение n, с нулём, чтобы начать выполнение цикла.
В строках 6-7 происходит загрузка в регистры значений a[0] и b[0].
В строке 8 к значению r прибавляется результат a[0] * b[0].
В строке 9 значение n уменьшается на 1.
В строках 10-11 увеличиваются значения регистров, в которых хранятся адреса массивов a и b, чтобы на следующей итерации a[0] и b[0] соответствовали следующим элементам массивов.
В строке 12 происходит сравнение регистра, в котором хранится значение n, с нулём, чтобы узнать, нужно ли выполнять очередную итерацию цикла.
В строке 14 происходит возврат из функции dot_product.
Таким образом, данный код работает аналогично неоптимизированному, однако выполняет гораздо меньше "дорогих" обращений к памяти.
Компиляция с флагом 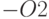
dot_product: # @dot_product
# %bb.0:
beqz a2, .LBB0_4
# %bb.1:
li a3, 8
andi a6, a2, 7
bgeu a2, a3, .LBB0_5
# %bb.2:
fmv.w.x fa0, zero
li a2, 0
bnez a6, .LBB0_8
.LBB0_3:
ret
.LBB0_4:
fmv.w.x fa0, zero
ret
.LBB0_5:
andi a2, a2, -8
fmv.w.x fa0, zero
li a4, 0
neg a2, a2
addi a5, a1, 16
addi a3, a0, 16
.LBB0_6: # =>This Inner Loop Header: Depth=1
flw ft0, -16(a3)
addi a4, a4, -8
flw ft1, -16(a5)
flw ft2, -12(a5)
fmadd.s ft0, ft0, ft1, fa0
flw ft1, -12(a3)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, -8(a3)
flw ft2, -8(a5)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, -4(a3)
flw ft2, -4(a5)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, 0(a3)
flw ft2, 0(a5)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, 4(a3)
flw ft2, 4(a5)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, 8(a3)
flw ft2, 8(a5)
fmadd.s ft0, ft1, ft2, ft0
flw ft1, 12(a3)
flw ft2, 12(a5)
addi a5, a5, 32
addi a3, a3, 32
fmadd.s fa0, ft1, ft2, ft0
bne a2, a4, .LBB0_6
# %bb.7:
neg a2, a4
beqz a6, .LBB0_3
.LBB0_8:
slli a2, a2, 2
add a3, a0, a2
flw ft0, 0(a3)
add a3, a1, a2
flw ft1, 0(a3)
li a3, 1
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.9:
addi a3, a2, 4
add a4, a0, a3
add a3, a3, a1
flw ft1, 0(a3)
li a3, 2
flw ft0, 0(a4)
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.10:
addi a3, a2, 8
add a4, a0, a3
add a3, a3, a1
flw ft1, 0(a3)
li a3, 3
flw ft0, 0(a4)
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.11:
addi a3, a2, 12
add a4, a0, a3
add a3, a3, a1
flw ft1, 0(a3)
li a3, 4
flw ft0, 0(a4)
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.12:
addi a3, a2, 16
add a4, a0, a3
add a3, a3, a1
flw ft1, 0(a3)
li a3, 5
flw ft0, 0(a4)
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.13:
addi a3, a2, 20
add a4, a0, a3
add a3, a3, a1
flw ft1, 0(a3)
li a3, 6
flw ft0, 0(a4)
fmadd.s fa0, ft0, ft1, fa0
beq a6, a3, .LBB0_3
# %bb.14:
addi a2, a2, 24
add a0, a0, a2
flw ft0, 0(a0)
add a0, a1, a2
flw ft1, 0(a0)
fmadd.s fa0, ft0, ft1, fa0
ret