
|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2178 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 10:
Поразрядная сортировка
Бинарная быстрая сортировка
Предположим, что мы можем переупорядочить записи в файле таким образом, что все ключи, начинающиеся с бита 0, будут расположены перед ключами, начинающимися с бита 1. Тогда можно воспользоваться рекурсивным методом сортировки, который является одним из вариантов быстрой сортировки (см. "Быстрая сортировка" ): разбиваем файл этим способом и потом независимо сортируем оба подфайла. Для переупорядочения файла мы просматриваем его слева до обнаружения ключа, который начинается с бита 1, затем просматриваем справа до обнаружения ключа, который начинается с бита 0, обмениваем их и продолжаем этот процесс до перекрещивания указателей. В литературе (включая и более ранние издания данной книги) этот метод часто называют поразрядной обменной сортировкой, а здесь мы будем называть его бинарной быстрой сортировкой (binary quicksort), чтобы подчеркнуть, что это лишь простой вариант алгоритма, изобретенного Хоаром, хотя он был открыт раньше быстрой сортировки (см. раздел ссылок).
В программе 10.1 представлена полная реализация этого метода. Применяемый в ней процесс разбиения по существу тот же, что и в программе 7.2, только в качестве центрального элемента используется число 2b, а не некоторый ключ из файла. Поскольку в файле может и не быть числа 2b, то нет и гарантии того, что в процессе разбиения хотя бы один элемент попадет в свою окончательную позицию. Данный алгоритм отличается и от обычной быстрой сортировки, поскольку рекурсивные вызовы выполняются для ключей размером на 1 бит меньше. Это различие существенно влияет на эффективность алгоритма. Например, если попадется вырожденное разбиение файла из N элементов, то будет выполнен рекурсивный вызов для подфайла размером N, но для ключей длиной на 1 разряд меньше. Поэтому число таких вызовов ограничено количеством разрядов в ключе. А последовательное использование центральных элементов, отсутствующих в файле, может ввести обычную быструю сортировку в бесконечный рекурсивный цикл.
Программа 10.1. Бинарная быстрая сортировка
Эта программа разбивает файл по ведущим битам ключей и затем рекурсивно сортирует полученные подфайлы. Переменная d содержит позицию анализируемого бита, начиная с 0 (самого левого). Разбиение завершается при j, равном i, после чего у всех элементов справа от a[i] в d-ой позиции находится 1, а у всех элементов слева от a[i] в d-ой позиции находится 0. Сам элемент a[i] содержит в d-ой позиции 1, кроме того случая, когда все ключи файла содержат в d-ой позиции нули. На этот случай сразу после цикла разбиения вставлена дополнительная проверка.
template <class Item>
void quicksortB(Item a[], int l, int r, int d)
{ int i = l, j = r;
if (r <= l || d > bitsword) return;
while (j != i)
{ while (digit(a[i], d) == 0 && (i < j)) i++;
while (digit(a[j], d) == 1 && (j > i)) j--;
exch(a[i], a[j]);
}
if (digit(a[r], d) == 0) j++;
quicksortB(a, l, j-1, d+1);
quicksortB(a, j, r, d+1);
}
template <class Item>
void sort(Item a[], int l, int r)
{ quicksortB(a, l, r, 0); }
Как и в случае стандартной быстрой сортировки, возможны различные варианты реализации внутреннего цикла. В программе 10.1 проверка, не пересеклись ли значения индексов, включена в оба внутренних цикла. Такая проверка приводит к лишнему обмену в случае, когда i = j; этого можно избежать с помощью оператора break, как сделано в программе 7.2, хотя там обмен элемента a[i] сам с собой вполне безобиден. Другой способ — использовать сигнальный ключ.
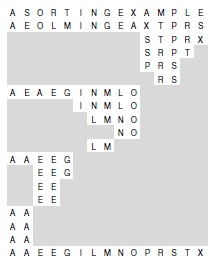
На рис. 10.2 показано выполнение программы 10.1 на небольшом файле, которое можно сравнить с рис. 7.1 для быстрой сортировки. Этот рисунок показывает, как перемещаются данные, но не объясняет, почему производятся те или иные перемещения — это зависит от двоичного представления ключей. Более подробное представление данного примера дано на рис. 10.3. Здесь считается, что буквы закодированы простым 5-разрядным кодом, в котором i-я буква алфавита представлена двоичным представлением числа i. Такая кодировка представляет собой упрощенную версию настоящих символьных кодировок, в которых для представления большего количества символов (буквы верхнего и нижнего регистров, цифры и специальные символы) используется большее число битов (7, 8 или даже 16).
Разбиение по старшему разряду еще не гарантирует того, что хотя бы одно значение займет свое окончательное место; оно лишь обеспечивает, что все ключи с 0 в старшем разряде предшествуют ключам с 1 в старшем разряде. Можно сравнить эту диаграмму с рис. 7.1 для быстрой сортировки, хотя принцип разбиений совершенно непонятен, если ключи не представлены в двоичном виде. На рис. 10.3 рис. 10.3 приведены все детали, которые проясняют, по каким позициям производится разбиение.
Для ключей в виде полных слов, состоящих из случайных битов, программа 10.1 должна начинать работу с самого левого бита слова, т.е. нулевого. В общем случае начальный бит напрямую зависит от приложения, от количества битов в машинном слове и от внутреннего представления целых (в том числе отрицательных) чисел. Для однобуквенных 5-разрядных ключей с рис. 10.2 и рис. 10.3 на 32-битовой машине начальным должен быть бит 27.
Этот пример показывает потенциальную проблему, которая может возникнуть при использовании бинарной быстрой сортировки в реальных ситуациях: довольно часто могут встречаться вырожденные разбиения (когда все ключи имеют одно и то же значение разряда, по которому производится разбиение). Сортировка небольших чисел (в которых много нулевых старших разрядов), как в рассмотренных нами примерах, не является чем-то необычным. Эта же проблема возникает и для символьных ключей: допустим, мы строим 32-разрядные ключи, объединяя четыре символа, каждый из которых представлен в стандартной 8-битовой кодировке. Тогда весьма вероятно появление вырожденных разбиений в начальной позиции каждого символа, поскольку, например, все буквы нижнего регистра начинаются с одних и тех же битов. С этой проблемой часто приходится сталкиваться при сортировке кодированных данных; аналогичные проблемы возникают и в других видах поразрядной сортировки.
Эта диаграмма построена на основании рис. 10.2, только здесь значения ключей приведены в двоичном представлении, а таблица сжата так, чтобы показать сортировку независимых подфайлов, как будто они выполняются параллельно, и для удобства транспонирована. На первом этапе файл разбивается на подфайл, все ключи которого начинаются с 0, и подфайл, все ключи которого начинаются с 1. Затем первый подфайл разбивается на подфайл, все ключи которого начинаются с 00, и подфайл, все ключи которого начинаются с 01; независимо от этого в произвольный момент времени второй подфайл разбивается на подфайл, все ключи которого начинаются с 10, и подфайл, все ключи которого начинаются с 11. Этот процесс прекращается при исчерпании разрядов (для повторяющихся ключей в данном примере) или когда размер подфайлов станет равным 1.
После того как ключ можно отличить по его левым разрядам от всех остальных, никакие другие разряды больше не анализируются. Это свойство в одних ситуациях является достоинством, в других — недостатком. Если ключи представляют собой действительно случайные совокупности битов, то в каждом ключе анализируются только lg N битов, что обычно намного меньше числа битов в ключах. Этот факт рассматривается в разделе 10.6, а также в упражнении 10.5 и на рис. 10.1. Например, сортировка файла из 1000 записей со случайными ключами может потребовать анализа всего лишь 10 или 11 битов каждого ключа (даже если ключи, скажем, 64-разрядные). А вот для одинаковых ключей проверяются все биты. Поразрядная сортировка не способна хорошо работать на файлах с большим числом длинных повторяющихся ключей. Бинарная быстрая сортировка и стандартный метод работают достаточно быстро, если сортируемые ключи состоят из абсолютно случайных битов (различие между ними состоит в основном в разнице затрат на операции извлечения битов и сравнения), но стандартный алгоритм быстрой сортировки легче приспособить к обработке неслучайных последовательностей ключей, а трехпутевая быстрая сортировка идеально подходит для случаев с преобладанием повторяющихся ключей.
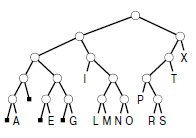
Как и в случае быстрой сортировки, структуру разбиения удобно описывать в виде бинарного дерева (как на рис. 10.4): корень дерева соответствует сортируемому файлу, а два его поддерева — подфайлам после разбиения. В случае стандартной быстрой сортировки известно, что по крайней мере одна из записей при разбиении попадает в свою окончательную позицию, так что этот ключ помещается в корневой узел.
Это дерево описывает структуру разбиения для бинарной быстрой сортировки, соответствующую рис. 10.2 и 10.3. Поскольку элементы не обязательно занимают свои окончательные позиции, ключи соответствуют внешним узлам дерева. Такая структура обладает следующим свойством: если на пути от корня к любому ключу обозначить разветвления влево за 0, а вправо — за 1, то получим значения старших разрядов этого ключа. Именно эти значения и отличают во время сортировки данный ключ от всех остальных. Черные квадратики означают пустые части разбиения (когда все ключи переходят в другую часть, поскольку значения их старших разрядов совпадают). В данном примере это происходит только на нижних уровнях дерева, но в принципе возможно и выше: например, если бы среди ключей не было I или X, то их узлы на рисунке были бы заменены пустым узлом. Обратите внимание, что повторяющиеся ключи (A и E) не могут быть разделены (сортировка поместит их в один подфайл только после исчерпания всех их битов).
В случае бинарной быстрой сортировки известно, что ключи попадают в свои окончательные позиции лишь тогда, когда размер подфайлов дошел до 1, либо когда исчерпаны все разряды ключа; так что эти ключи помещаются на нижний уровень дерева. Такая структура называется бинарным trie-деревом (binary trie); ее свойства будут подробно рассмотрены в "Поразрядный поиск" . Например, одно из важных и интересных свойств заключается в том, что структура trie-дерева полностью определяется значениями ключей, а не порядком их следования.
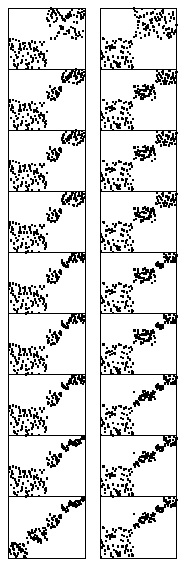
Разбиения на части при бинарной быстрой сортировке менее чувствительны к упорядоченности ключей, чем в стандартной быстрой сортировке. Здесь показан процесс упорядочения двух различных случайно упорядоченных файлов с 8-разрядными ключами; профили их разбиений практически совпадают.
Разделы разбиений в быстрой сортировке зависят от двоичного представления диапазона ключей и количества сортируемых элементов. Например, если файлы представляют собой случайные перестановки целых чисел, меньших 171 = 101010112 , то разбиение по первому биту эквивалентно разбиению по значению 128, и подфайлы получаются разновеликими (размер одного — 128, а другого — 43). Ключи на рис. 10.5 являются случайными 8-разрядными значениями, поэтому здесь такой эффект не наблюдается, но знать о нем надо, чтобы не было неприятных сюрпризов при столкновении с ним на практике.
Базовая рекурсивная реализация может быть усовершенствована с помощью отказа от рекурсии и особой обработки небольших подфайлов, как это было сделано для стандартной быстрой сортировки в "Быстрая сортировка" .
Упражнения
10.8. Начертите, в стиле рис. 10.2, trie-дерево, соответствующее процессу разбиений при поразрядной быстрой сортировке ключей E A S Y Q U E S T I O N.
10.9. Сравните количество обменов, используемых бинарной быстрой сортировкой, с количеством обменов, используемых обычной быстрой сортировкой, для 3-разрядных двоичных чисел 001, 011, 101, 110, 000, 001, 010, 111, 110, 010.
о 10.10. Почему сортировка меньшего из двух под-файлов первым менее важна в бинарной быстрой сортировке, чем в обычной быстрой сортировке?
о 10.11. Опишите, что происходит на втором уровне разбиения (когда разбивается левый подфайл и когда разбивается правый подфайл) при использовании бинарной быстрой сортировки для упорядочения случайных перестановок неотрицательных целых чисел, меньших 171.
10.12. Напишите программу, которая за один предварительный проход определяет число старших разрядов, одинаковых у всех ключей, а затем вызывает бинарную быструю сортировку, модифицированную так, что она игнорирует эти разряды. Сравните время выполнения этой программы со временем выполнения стандартной реализации для N = 103, 104, 105 и 106 , если входными данными являются 32-разрядные слова следующего формата: крайние правые 16 битов — равномерно распределенные случайные значения, а крайние левые 16 битов равны 0, кроме единицы в i-ой позиции, если в правой половине имеется i единиц.
10.13. Внесите в бинарную быструю сортировку явную проверку ситуаций, когда все ключи равны. Сравните время выполнения этой программы с аналогичным показателем для стандартной реализации при N = 103, 104, 105 и 106 и входных данных, описанных в упражнении 10.12.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |