|
Добрый день! В курсе "Проектирование систем искусственного интеллекта" начал проходить обучение и сдал тесты по лекциям 1,2,3,4. Но видимо из-за того что не записался на курс, после того как записался на курс у меня затерлись результаты сданных тестов. Можно как-то исправить (восстановить результаты по тестам 1,2,3,4) ? |
Опубликован: 15.06.2007 | Доступ: свободный | Студентов: 6551 / 2682 | Оценка: 3.96 / 3.52 | Длительность: 15:17:00
Специальности: Программист, Системный архитектор
Теги:
Лекция 8:
Бинарные деревья
Иерархия типов
Иерархия типов и подтипов является стандартной характеристикой семантических сетей. Иерархия может включать сущности: ТАКСА < СОБАКА < ПЛОТОЯДНОЕ < ЖИВОТНОЕ < ЖИВОЕ СУЩЕСТВО < ФИЗИЧЕСКИЙ ОБЪЕКТ < СУЩНОСТЬ. Они также могут включать в себя события: ЖЕРТВОВАТЬ < ДАВАТЬ < ДЕЙСТВИЕ < СОБЫТИЕ или состояния: ЭКСТАЗ < СЧАСТЬЕ < ЭМОЦИОНАЛЬНОЕ СОCТОЯНИЕ < СОСТОЯНИЕ. Иерархия Аристотеля включала в себя 10 основных категорий: субстанция, количество, качество, отношение, место, время, состояние, активность и пассивность. Некоторые учение дополнили его своими категориями.
Символ < между более общим и более частным символом читается как: "Х-тип/подтип У".
Термин " иерархия " обычно обозначает частичное упорядочение, где одни типы являются более общими, чем другие. Упорядочение является частичным, потому, что многие типы просто не подлежат сравнению между собой. Сравним HOUSE<DOG и DOG<HOUSE бессмысленны, если их сравнивать, однако слово DOGHOUSE является подтипом HOUSE, но не DOG. Рассмотрим некоторые виды графов:
Ацикличный граф. Любое частичное упорядочение может быть изображено, как граф без циклов. Такой граф имеет ветви, которые расходятся и сходятся вместе опять, что позволяет некоторым узлам иметь несколько узлов-родителей. Иногда такой тип графа называют путанным.
Деревья. Самым распространенным видом иерархии является граф с одной вершиной. В такого рода графах налагаются ограничения на ацикличные графы: вершина графа представляет собой один общий тип, и каждый другой тип Х имеет лишь одного родителя У.
Решетка. В отличие от деревьев узлы в решетке могут иметь несколько узлов родителей. Однако здесь налагаются другие ограничения: любая пара типов Х и У как минимум должна иметь общий гипертип ХиУ и подтип ХилиУ. Вследствие этого ограничения решетка выглядит, как дерево, имеющее по главной вершине с каждого конца. Вместо всего одной вершины решетка имеет одну вершину, которая является гипертипом всех категорий, и другую вершину, которая является подтипом всех типов.
Наследование.
Основным свойством иерархии является возможность наследования подтипами качеств гипертипов: все характеристики, которые присущи ЖИВОТНОМУ, также присущи МЛЕКОПИТАЮЩЕМУСЯ, РЫБЕ и ПТИЦЕ. В основе теории наследования лежит теория силлогизмов Аристотеля: Если А — характеристика В, а В — х-ка С, то А — хар-ка всех С.
Преимущества иерархии и наследования:
- Иерархия типов является отличной структурой для индексирования базы знаний и ее эффективной организации.
- Следование по какой-либо ветви с помощью иерархии осуществляется гораздо быстрее.
Синтаксический анализ языка и его порождение.
Семантические сети могут помочь парсеру разрешить семантическую неоднозначность. Без такого рода представления вся тяжесть анализ языка падает на синтаксические правила и семантические тесты. Структура же семантической сети ясно показывает, как отдельные концепты соединены между собой. Когда парсер встречает какую-либо неоднозначность, он может использовать семантическую сеть для того, чтобы выбрать тот или иной вариант. При работе с семантическими сетями используется несколько техник парсинга.
Парсинг, в основе которого лежит синтаксис. Работа парсера контролируется грамматикой непосредственных составляющих и операторами построения структур и их тестирования. В то время, как данные на входе анализируются, операторы построения структур создают семантическую сеть, а операторы тестирования проверяют ограничения на частично построенной сети. Если никакие ограничения не найдены, то используемое при этом грамматическое правило отвергается и парсер проверяет другую возможность. Это самый распространенный подход.
Синтаксический анализатор с использованием семантики. Синтаксический анализатор с использованием семантики оперирует также как и парсер, в основе которого лежит синтаксис. Однако он оперирует не с синтаксическими категориями типа группа подлежащего и группа сказуемого, а с концептами высокого уровня типа КОРАБЛЬ и ПЕРЕВОЗИТЬ.
Концептуальный парсинг. Семантическая сеть предсказывает возможные ограничения, которые могут встретится в отношениях между словами, а также прогнозировать слова, которые позже могут встретиться в предложении. Например, глагол давать требует одушевленного агента и а также прогнозирует возможность реципиента и объекта, который будет дан. Шенк был одним из самых активных сторонников концептуального парсинга.
Парсинг, основанный на экспертизе слов. Вследствие существования большого количества неправильных образований в естественном языке, многие люди вместо того, чтобы обращаться к каким-либо универсальным обобщениям, используют специальные словари, представляющих собой совокупность некоторых независимых процедур, которые называются экспертами слов. Анализ предложения рассматривается как процесс, осуществляемый совместно различными словарными экспертами. Главным сторонником этого подхода был Смол.
Аргументы за и против различных техник парсинга часто основывался не на конкретные данные, а больше на уже устоявшемся мнении. И лишь один проект на практике сравнил несколько видов парсинга — это Язык Семантических Репрезентаций, проект разработанный в Университете Берлина. В течение нескольких лет они создали четыре разных вида парсеров для анализа немецкого языка и его записи на Язык Семантических Репрезентаций, который представляет собой сеть.
Первым парсером был парсер, созданный по подобию концептуального парсера Шенка. Было отмечено, что хотя добавление в его лексикон новых слов было довольно легко, анализ однако мог проводиться только на простых предложениях и только относительных придаточных. Расширить область синтаксической обработки этого парсера оказалось сложной задачей.
Второй парсер был семантически ориентированные расширенные сети перехода. В нем было легче обобщить синтаксис, однако аппарат синтаксиса работал медленнее, чем у первого рассмотренного парсера.
Затем работа велась с парсером словарных экспертов. Здесь легко велась обработка особых случаев, однако разбросанность грамматики между отдельными составляющими делала практически невозможным ее общее понимание, поддержку и модифицирование.
Парсер, который был создан относительно недавно, — это синтаксически ориентированный парсер, основанный на общей грамматике фразовой структуры. Он наиболее систематичен и обобщен и относительно быстр.
Эти результаты в принципе соответствуют мнению других лингвистов: синтаксически ориентированные парсеры наиболее целостны, однако для них необходим определенный набор сетевых операторов для плавного взаимодействия между грамматикой и семантическими сетями.
Порождение языка по семантической сети представляет собой обратный парсинг. Вместо синтаксического анализа некоторй цепочки с целью порождения сети генератор языка производит парсинг сети для получения некоторой цепочки. Существует два варианта порождения языка из семантической сети.
- Генератор языка просто следует по сети, превращая концепты в слова, а отношения, указанные рядом с дугами, в отношения естественного языка. Этот метод имеет много ограничений.
- Подходы, ориентированные на синтаксис контролируют порождение языка с помощью грамматических правил, которые используют сеть для того, чтобы определить, какое следующее правило нужно применить.
Однако на практике оба метода имеют много сходств: например, первый способ представляет собой последовательность узлов, которые обрабатываются генератором языка, ориентированным на синтаксис.
Элементы нечеткой логики
Как известно, классическая логика оперирует только с двумя значениями: истина и ложь. Однако этими двумя значениями довольно сложно представить (можно, но громоздко) большое количество реальных задач. Поэтому для их решения был разработан специальный математический аппарат, называемый нечеткой логикой. Основным отличием нечеткой логики от классической, как явствует из названия, является наличие не только двух классических состояний (значений), но и промежуточных:
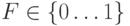
Соответственно, вводятся расширения базовых операций логического умножения, сложения и отрицания (сравните с соответствующими операциями теории вероятностей):
a I b = min{a,b}
a Y b = max{a,b}
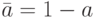
Как можно легко заметить, при использовании только классических состояний (ложь-0, истина-1) мы приходим к классическим законам логики.
Нечеткое логическое управление может использоваться, чтобы осуществлять разнообразные интеллектуальные функции, в самых разнообразных электронных товарах и домашних приборах, в автоэлектронике, управлении производственными процессами и автоматизации.
Сергей Пчеляков